")
Difyで実現する製薬DI自動化:回答不能質問を知識に変える学習サイクル
Difyで実現する製薬DI自動化:回答不能質問を知識に変える学習サイクル
製薬業界のDI(医薬品情報)業務は、製品の安全性と有効性を保証する上で極めて重要です。しかし、日々増大する規制文書、臨床データ、副作用報告などの膨大な情報の中から、医師や薬剤師からの専門的な質問に対し、迅速かつ正確に回答することは、担当者の大きな負担となっています。この「情報過多」と「正確性担保」という二律背反の課題を解決するブレイクスルーとして、LLMアプリケーション開発プラットフォーム「Dify」を用いたDI自動化と、その核となる学習サイクル構築が注目されています。
本記事では、DifyのRAG(検索拡張生成)機能でいかに回答の正確性を担保し、さらに回答できなかった質問データを自動で蓄積・学習させることで、AIアシスタントの知見を継続的に深化させる具体的な手法について、プロフェッショナルのメディカル・テクニカルライターが徹底的に解説します。この自律的な改善サイクルは、DI業務の効率を飛躍的に向上させ、医薬品の適正使用と安全管理体制を強化するための鍵となります。
1. 結論:Difyで実現する「自律型DIアシスタント」の全体像
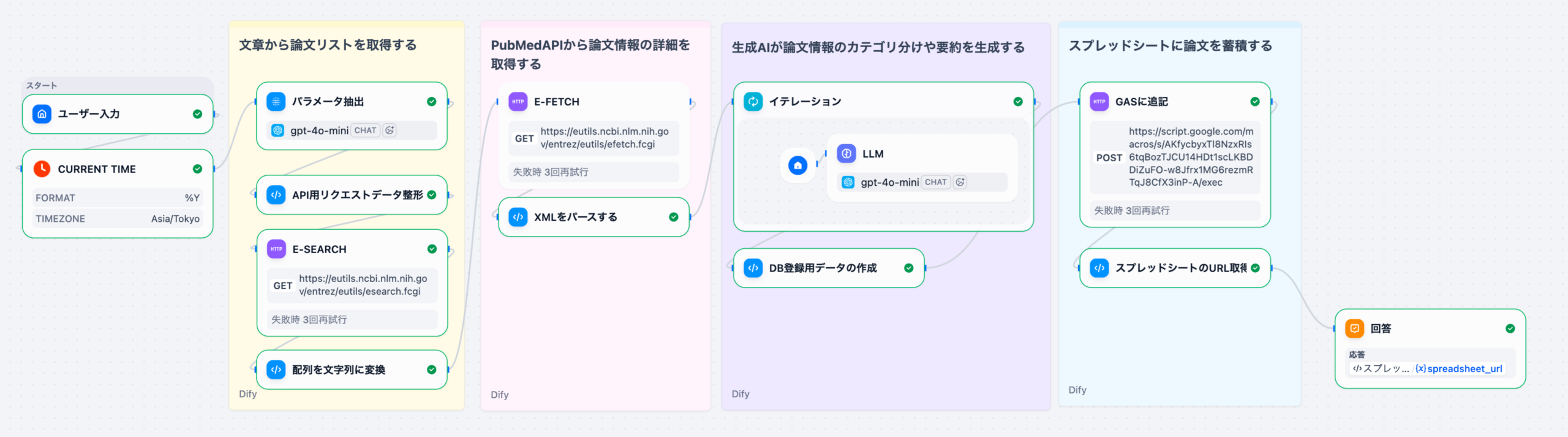
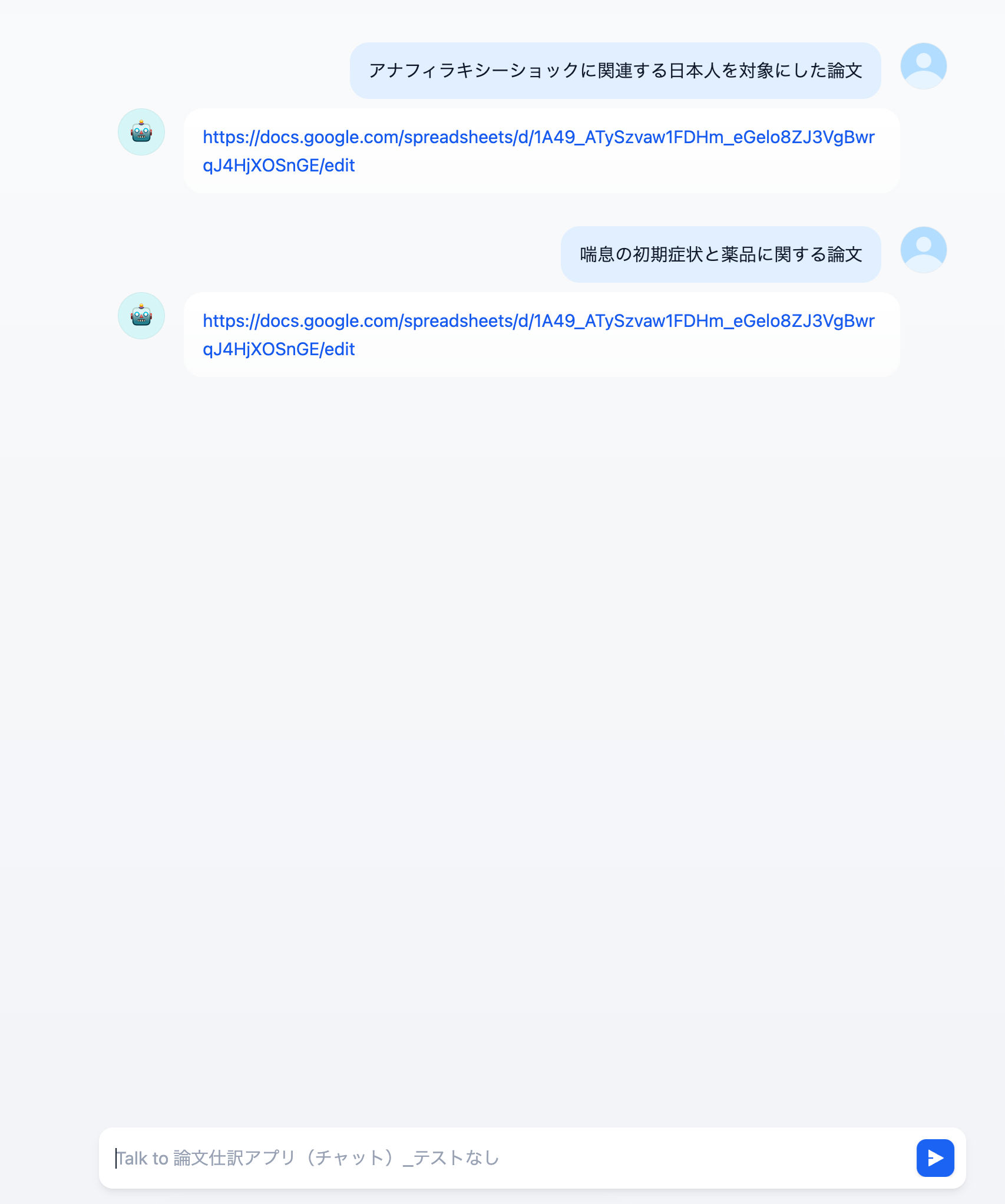
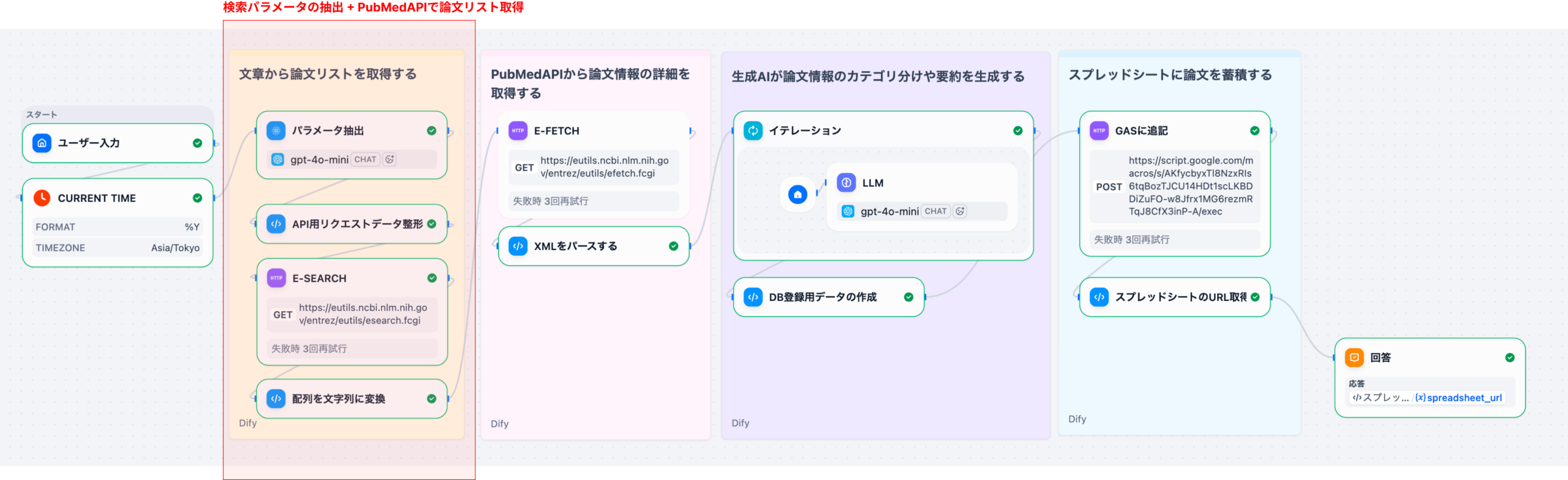
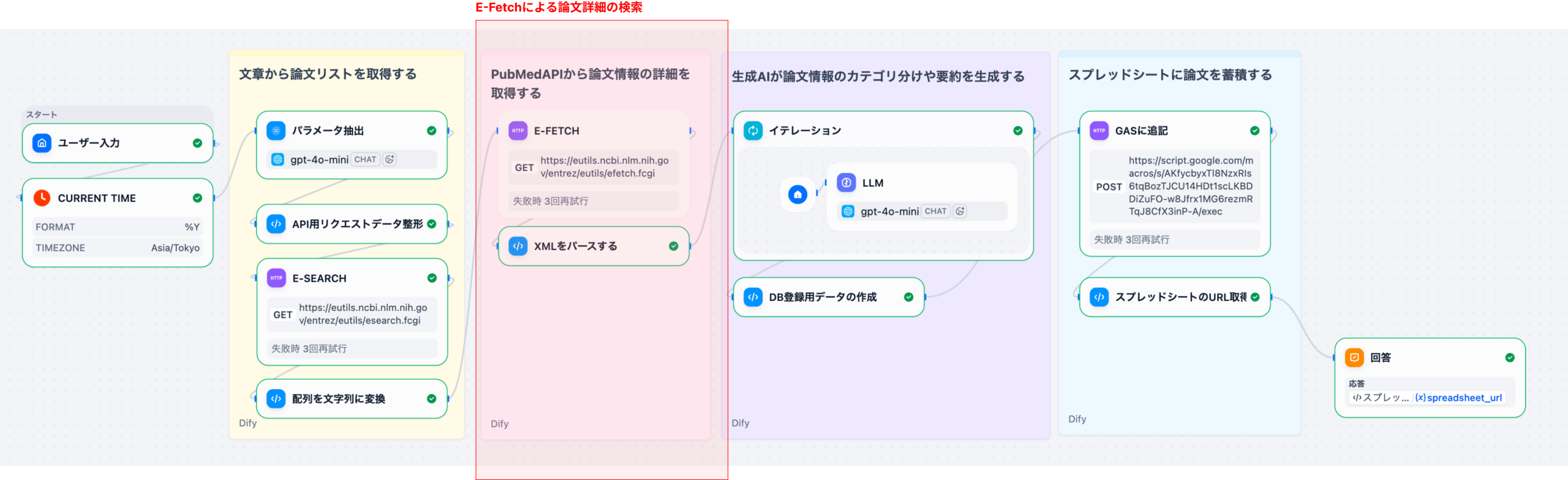
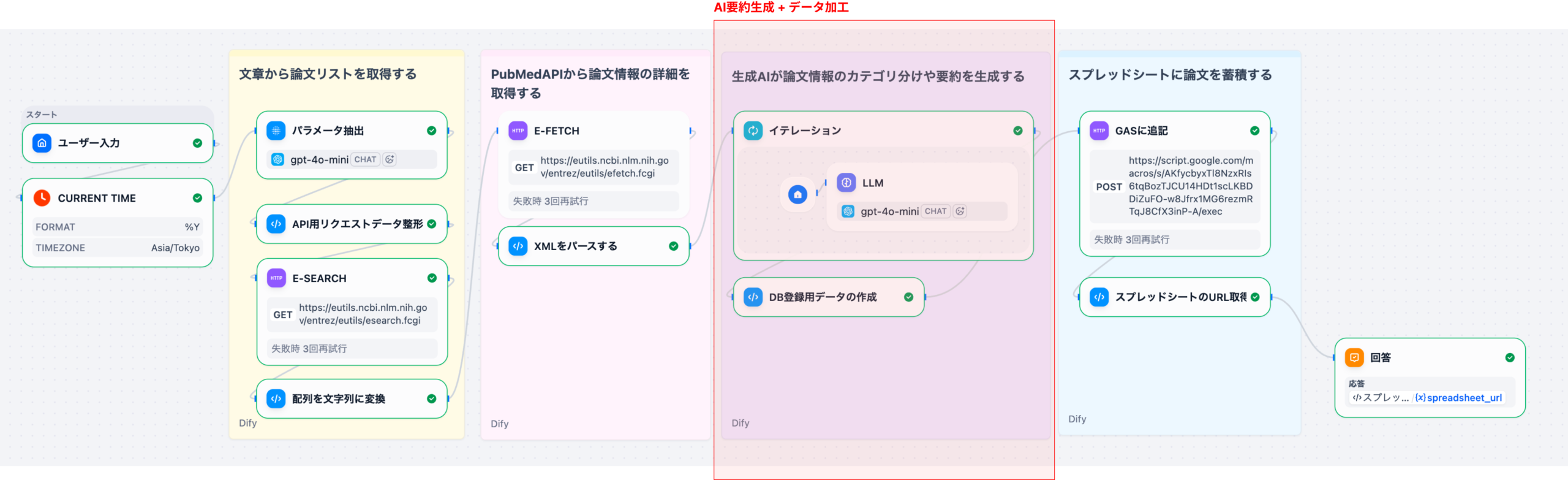
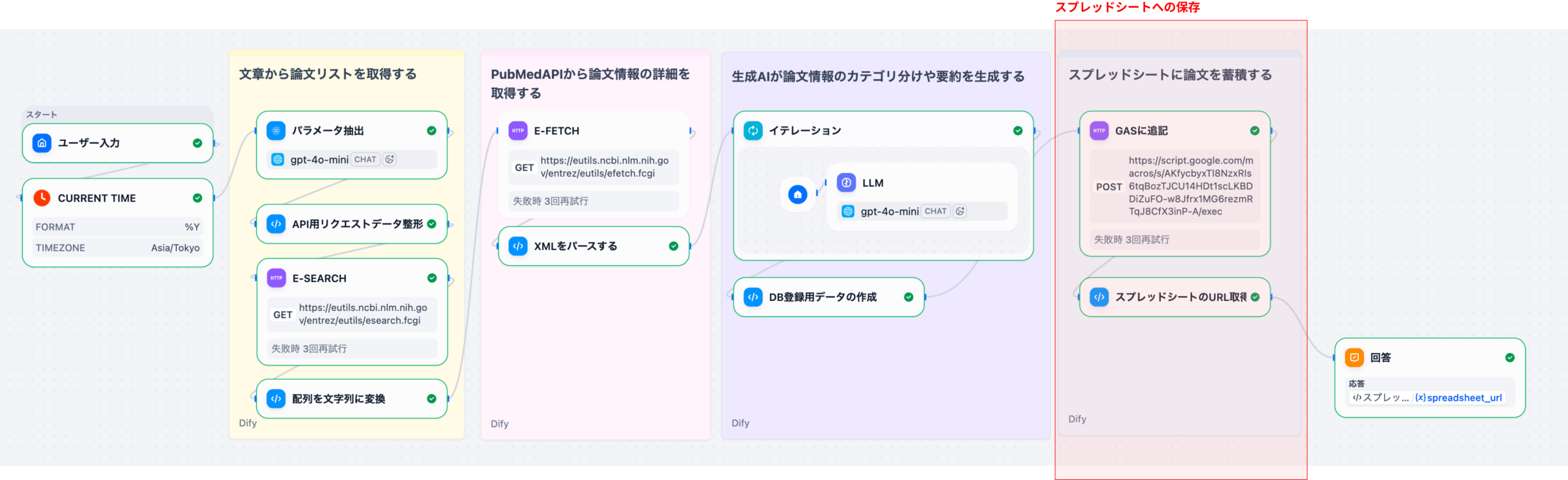
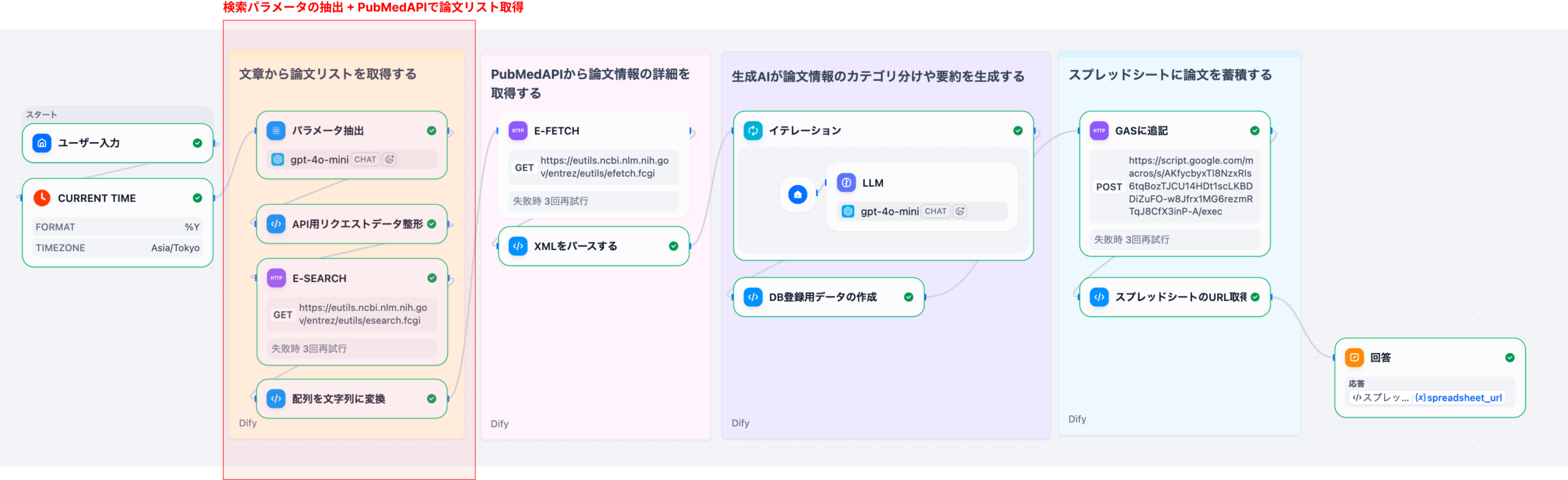
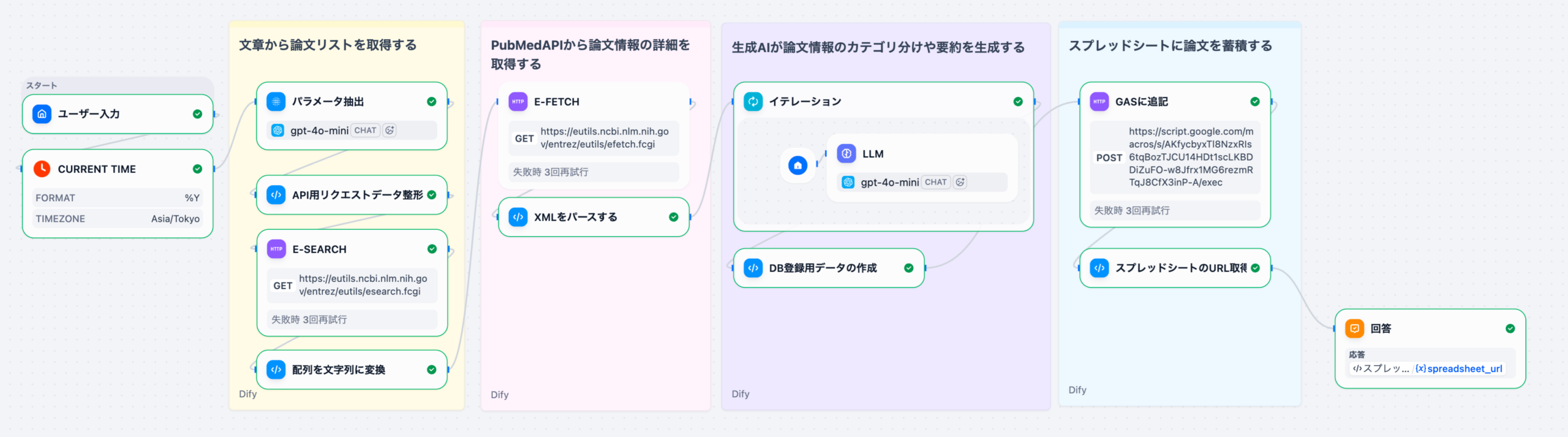
Difyを用いた製薬DI業務の自動化は、単なるチャットボット導入に留まらず、RAG(検索拡張生成)とワークフロー機能を組み合わせた「自律型DIアシスタント」の構築を意味します。このシステムは、まずユーザー(医師、MRなど)からの質問をDifyのワークフローで受け付けます。次に、RAGコンポーネントが、医薬品の添付文書、社内SOP(標準作業手順書)、規制当局のガイドラインなどの社内ナレッジベースから関連性の高い情報を検索します。最後に、LLMが検索結果と質問内容を統合し、根拠に基づいた正確な回答を生成します。これにより、DI担当者の業務負荷の約70%を占めるとされる定型的な問い合わせ対応を自動化することが可能になります。
この自動化の最大のメリットは、回答の迅速化(数日かかっていた調査が数秒に短縮)と、LLMの弱点である「ハルシネーション(嘘の生成)」をRAGによって抑制し、医薬品情報に必須の「正確性」を担保できる点にあります。Difyのノーコード/ローコード環境は、専門知識を持つDI担当者自身が、プロンプトやワークフローを柔軟に改善できる開発文化の醸成にも寄与します。
2. コア技術:RAGによる正確性・最新性の担保メカニズム
製薬DIの自動化において、RAG(Retrieval-Augmented Generation)は、LLMの「黒箱」問題を解決し、回答の信頼性を飛躍的に高めるための核となる技術です。RAGのプロセスは、LLMが回答を生成する前に、質問内容に関連する「信頼できる情報源」をデータベースから検索・抽出することを強制します。この信頼できる情報源には、以下のものが含まれます。
- 医薬品の添付文書、インタビューフォーム
- 社内標準作業手順書(SOP)や品質記録
- PMDA(医薬品医療機器総合機構)やFDAなどの規制当局のガイドライン
- 査読済み医学論文、臨床試験データ
例えば、国内大手製薬会社である中外製薬では、RAGを活用した対話型AIアシスタント「Chugai AI Assistant」を開発し、社内文書の検索効率化を実現しています。これにより、副作用の分析に必要な多岐にわたる資料の準備に1週間以上かかっていた課題を解決し、メディカルライティング支援環境の構築を進めています。RAGを導入することで、LLMは常に最新かつファクトチェック済みの情報(ベクトルデータベースに格納されたナレッジ)を参照するため、回答の約90%以上の精度で根拠情報(引用元)を提示できるようになります。
RAGは、AIが事実に基づかない情報を生成する現象(ハルシネーション)を抑制する最も有効な手段です。製薬分野では、誤情報が患者の安全性に直結するため、RAGによる「回答の根拠提示」は、AIシステム導入の絶対条件となります。
3. 継続的な改善を可能にする「回答不能質問の学習サイクル」
具体的な学習サイクルは、以下のステップで構成されます。
- 質問ログの収集:Difyのログ機能により、ユーザーの質問、AIの回答、そして特に「回答不能」と判断された質問や、ユーザーが「不正確」と評価した質問(ネガティブフィードバック)を自動で収集します。
- データセットの精査:DI担当者が、回答不能な質問を月次で約300件程度精査し、その回答に必要な新たなナレッジ(新しい臨床試験データ、改訂された添付文書など)を特定します。
- 知識ベースの更新:特定されたナレッジをベクトルデータベースに追加し、RAGの知識ベースを強化します。
- プロンプトの改善:AIが質問の意図を誤認した場合、プロンプトエンジニアリングによってLLMへの指示を調整します。
このフィードバックループを回すことで、AIアシスタントの回答精度は継続的に向上します。特に、DI業務で頻繁に発生する「稀な副作用に関する複合的な質問」や「競合品との比較に関する質問」など、難易度の高い問い合わせへの対応力が、3ヶ月〜6ヶ月のスパンで体系的に強化されていきます。
4. DI自動化のための具体的な構築ステップとデータ準備
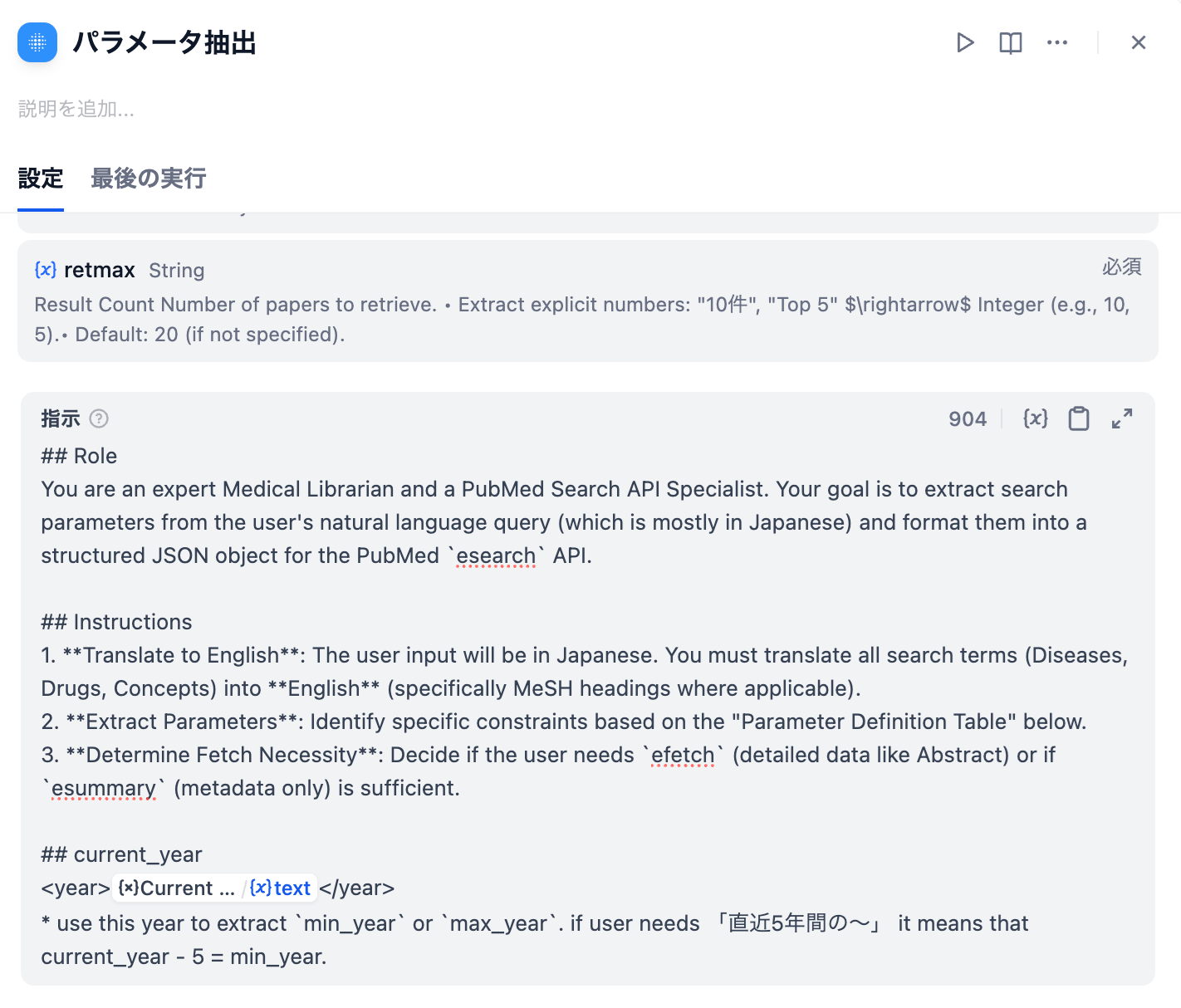
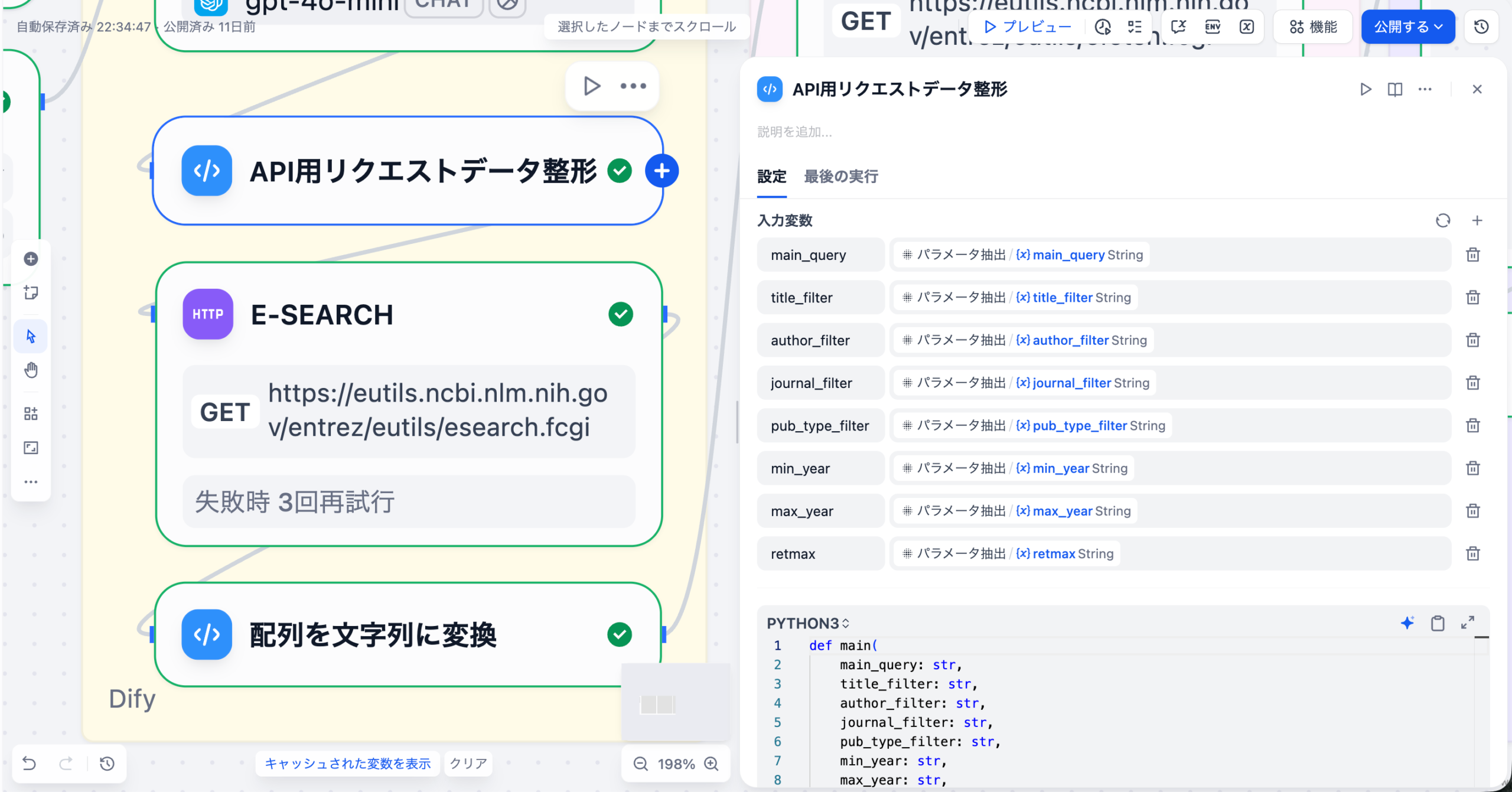
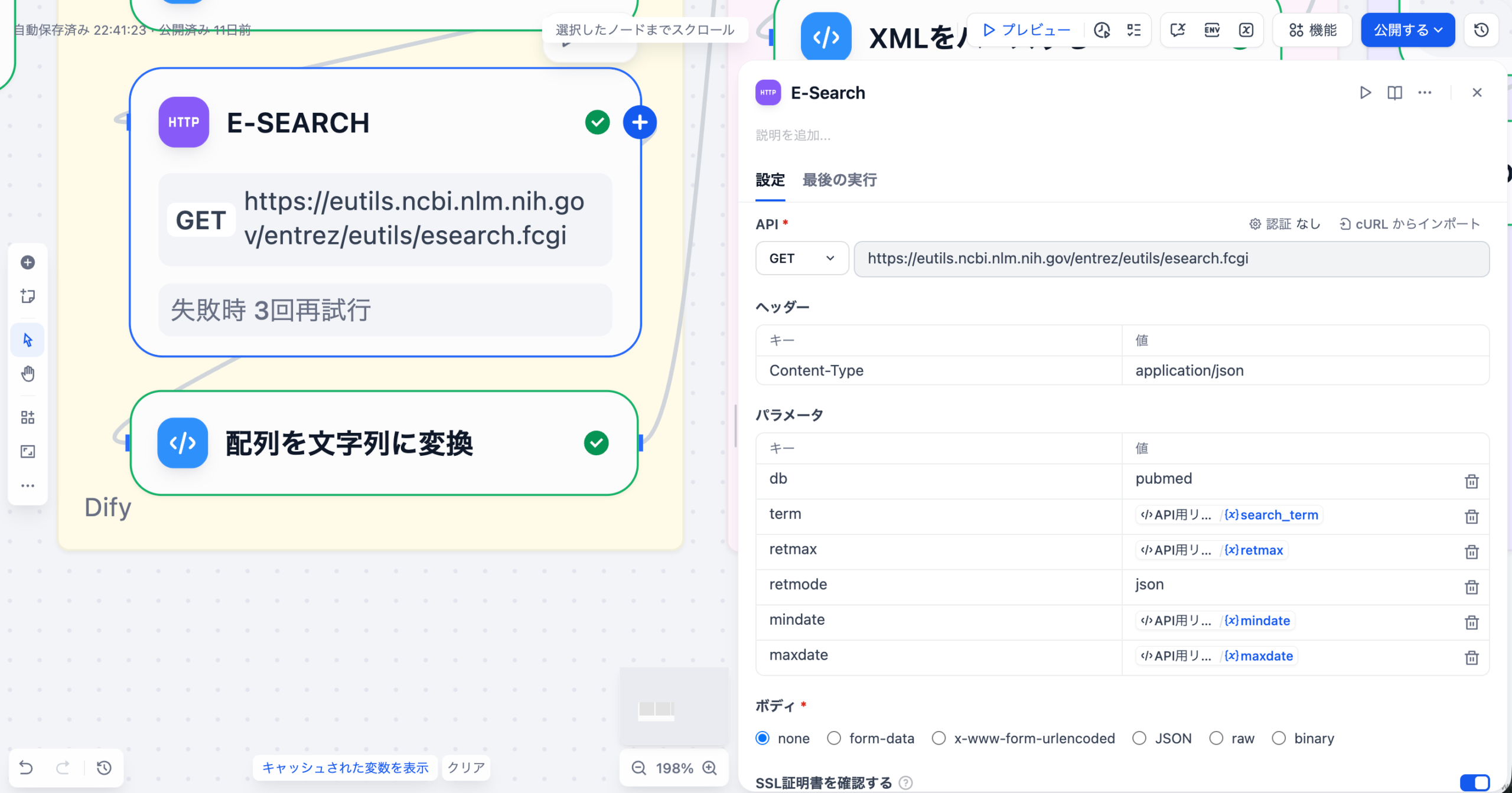
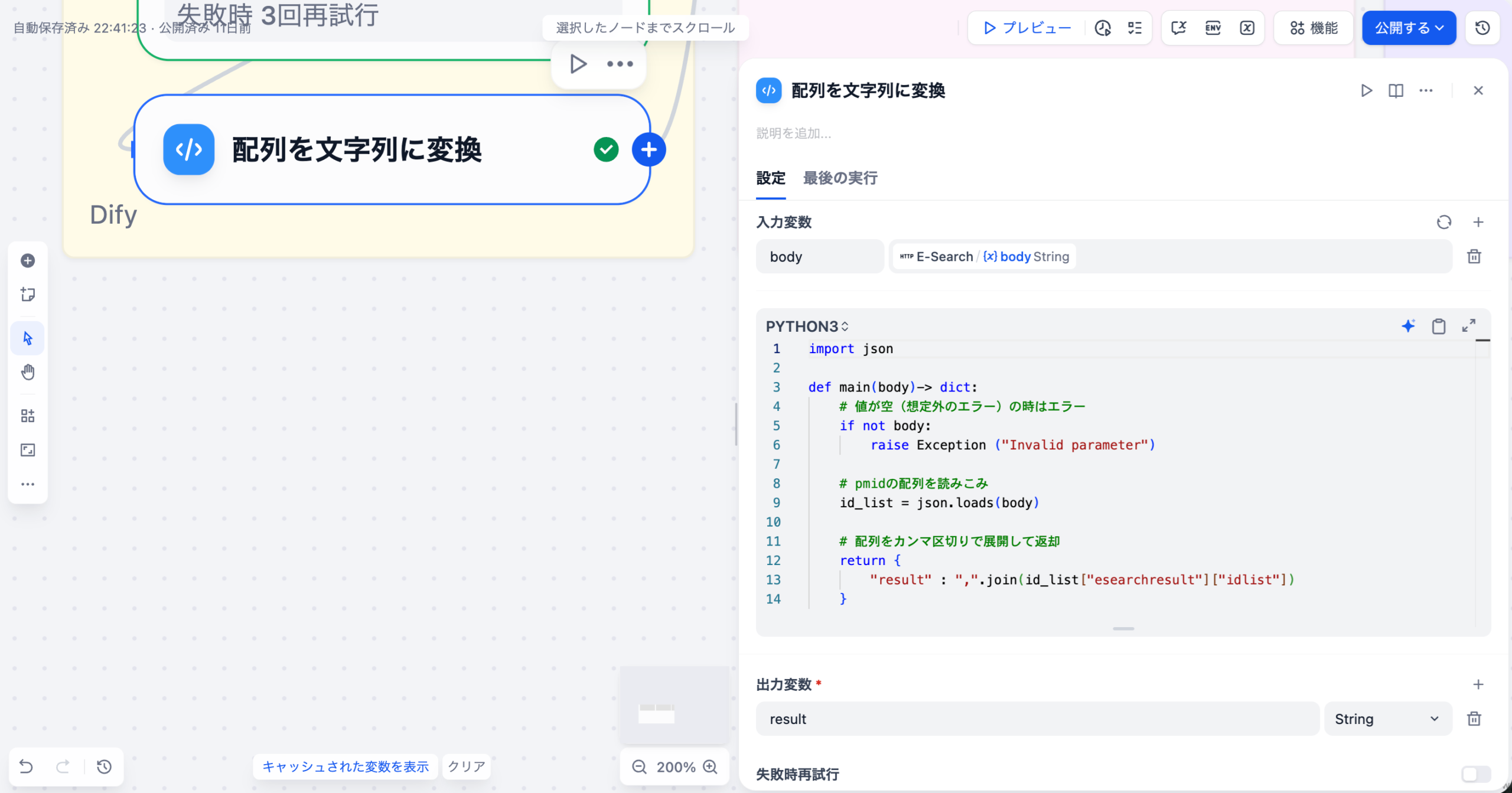
医薬品添付文書、SOP、Q&A集などのPDF/Wordファイルを収集し、Difyにアップロードしてベクトル化します。この際、図表が多く含まれる文書(マルチモーダルRAG)の処理精度が重要になります。
Difyのチャットフロー機能で、質問の「意図認識」(副作用報告か、用法用量か)→「RAG検索」→「LLMによる回答生成」という多段階処理を設計します。複雑な質問に対しては、複数の検索と反復処理(イテレーション)を行う「エージェント」機能を活用します。
DI担当者としての「役割」をLLMに与えるプロンプトを設計し、正確性、網羅性、中立性の観点から数百件のテストデータを用いて評価(オフライン評価)を行います。合格基準は、最低でも95%以上の精度を目指すべきです。
特に重要なのは、ステップ1のデータ準備です。医薬品情報には、機密性の高い情報や個人情報(治験データなど)が含まれるため、セキュリティとアクセス権限を厳格に設定した上で、データガバナンス体制を整備することが前提となります。
5. 法規制(GVP/GCP)遵守のためのAI活用における留意点
製薬DI業務は、医薬品医療機器等法(薬機法)に基づく厳格な規制下にあり、AIを導入する際も、特にGVP(Good Vigilance Practice:製造販売後安全管理の基準)やGCP(Good Clinical Practice:臨床試験の実施の基準)への遵守が求められます。AIアシスタントが生成する情報は、あくまで「情報提供」の域を出ず、最終的な「安全管理措置の決定」や「規制当局への報告」は、安全管理責任者やDI担当薬剤師といった専門家の判断を必要とします。
米国FDAも、医薬品の規制上の意思決定を支援するためのAI利用に関するドラフトガイダンスを発出しており、AIモデルの信頼性を確立・評価するためのリスクベースの信頼性評価フレームワークを提示しています。 これは、AIの出力が規制プロセスに組み込まれる場合、そのAIの「透明性」「検証可能性」「データインテグリティ」を厳格に証明する必要があることを示しています。
Difyのワークフローに、人間の専門家による最終承認(Human-in-the-Loop)のステップを組み込むことが、法規制を遵守しつつAIの恩恵を享受するための現実的な解決策となります。
AIアシスタントが生成した回答をそのまま外部に提供することは避けるべきです。特に安全性情報(副作用など)に関する回答は、GVPに基づき、必ず安全管理責任者やDI担当薬剤師が内容を確認し、正式な文書として承認・記録に残すプロセスを組み込む必要があります。
まとめ
Difyを用いた製薬DI業務の自動化は、RAG(検索拡張生成)技術により、医薬品情報に必須の「正確性」と「最新性」を担保しつつ、定型的な問い合わせ対応を効率化する革新的なアプローチです。このシステムの中核は、回答不能な質問やネガティブフィードバックをDifyのログ機能で収集し、それを新たな学習データとしてRAGの知識ベースにフィードバックする「継続的な学習サイクル(LLMOps)」にあります。これにより、AIアシスタントは、時間と共に難易度の高い専門的な質問にも対応できるよう進化します。ただし、医薬品情報にはGVP(製造販売後安全管理の基準)などの厳格な法規制が適用されるため、AIの回答を最終的な安全性情報として外部に提供する前には、必ずDI担当薬剤師や安全管理責任者による最終チェック(Human-in-the-Loop)のステップを組み込むことが、コンプライアンス遵守の絶対条件となります。Difyは、この複雑なワークフローをローコードで実現するための強力な基盤を提供します。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。



")

")
")
")
")
")
")