")
DPCデータ分析をDifyが言語化。「改善提案書」作成アシスタント
DPCデータ分析をDifyが言語化:病院経営を加速するAI改善提案書アシスタント
DPC(診断群分類別包括評価)データは、病院経営の「羅針盤」として極めて重要ですが、その膨大なデータを分析し、経営層や診療科に響く具体的な「改善提案書」として言語化するには、高度な専門知識と多くの時間を要します。この「分析」と「提案」の間のギャップこそが、多くの病院で経営改善が停滞する最大のボトルネックです。本記事では、この課題を解決するために、Difyのような大規模言語モデル(LLM)を活用し、DPCデータ分析結果を即座に具体的な提案書へと変換するAIアシスタントのメカニズムと、それが病院経営にもたらす劇的な効果を、具体的なデータに基づいて解説します。
医療DXが加速する現代において、データ分析の「最終工程」である言語化をAIに任せることで、人間はより高度な意思決定と現場での実行に集中できるようになります。このAIアシスタントが、いかにして病院の収益改善、医療の質向上、そして医師の働き方改革を同時に実現するのか、その全貌をご覧ください。
1. DPCデータ分析の現状と「言語化」のボトルネック
DPCデータは、病院の収益構造、診療プロセス、医療資源の投入状況などを詳細に把握するための「宝の山」です。しかし、多くの医療機関では、このデータの真価を十分に引き出せていません。課題は大きく分けて2つあります。1つは、Excelなどの汎用ツールでは、データ量増加や多角的なクロス集計といった高度な分析に限界があることです。2つ目のより大きな課題は、分析結果を具体的なアクションに繋げる「言語化」のプロセスにあります。
DPCデータ分析の重要な指標には、全国平均やベンチマーク病院と比較した「平均在院日数」、クリニカルパスの見直しに直結する「手術・処置の実施状況」、そしてコスト管理に欠かせない「薬剤費・材料費」の分析が含まれます。これらの分析結果を「なぜその課題が発生しているのか」「どのような改善策が必要か」という論理的な提案書に落とし込むには、経営分析の専門家や医師の深い理解が必要です。この専門人材の不足と、提案書作成にかかる膨大な時間こそが、病院経営改善の最大のボトルネックとなっています。
DPC分析は、単なる「集計」ではなく、他院との比較(ベンチマーキング)や時系列での変化を捉える「深掘り分析」が不可欠です。分析結果を業務改善に繋げるには、診療科・疾患レベルでの課題の「見える化」と、それを具体的な改善策として言語化する作業が成功の鍵を握ります。約8,000の病院が存在する中で、DPCシステムを採用する急性期病院は1,786施設(2024年4月時点)であり、データ活用は病院競争力を左右します。
2. AIアシスタントがもたらす結論:経営改善の加速化
実際、電子カルテシステムに搭載された生成AIによる医療文書作成支援の実証実験では、文書に記載する要約文章の新規作成時間を平均47%削減できたという結果が報告されています。これは、DPC分析に基づく経営提案書のような複雑な文書においても、同様の効率化が期待できることを示唆しています。AIは、分析ツールが出力した大量の数値データ(例:在院日数が全国平均より2日長い疾患群)をインプットとして受け取り、その背景にある可能性のある要因(例:クリニカルパスの未整備、退院支援の遅れ)を論理的に結びつけ、経営層が理解しやすいビジネス文書の形式で出力します。これにより、データ分析から改善実行までのリードタイムが劇的に短縮され、病院の収益改善スピードが加速します。
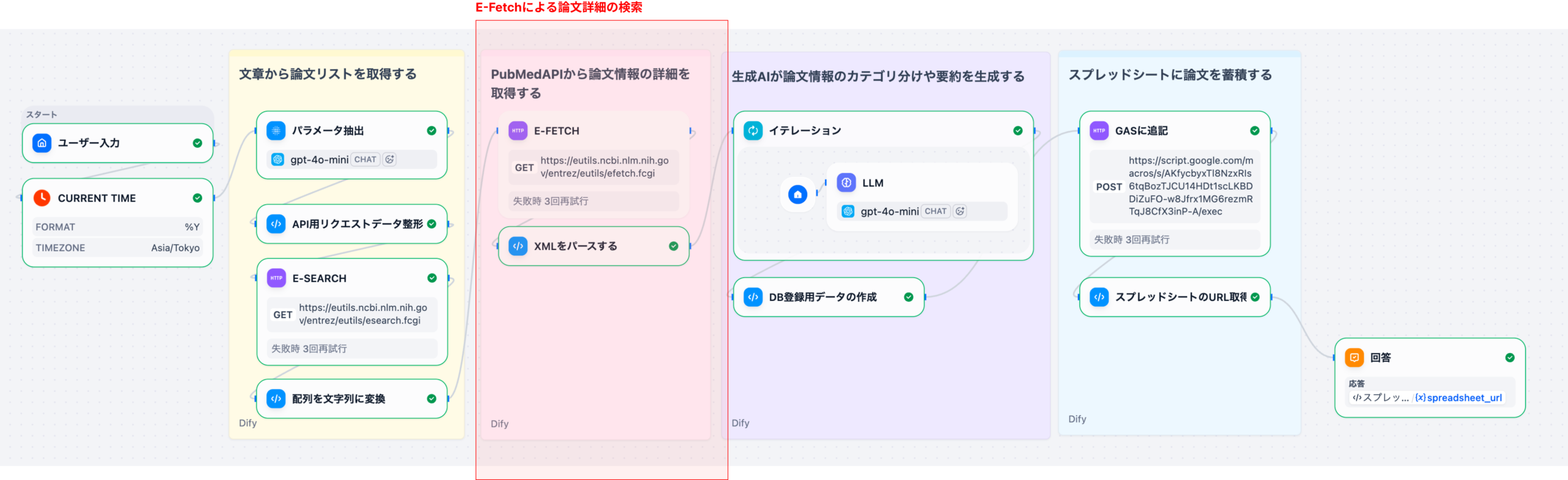
3. DifyによるDPCデータ言語化のメカニズムとプロセス
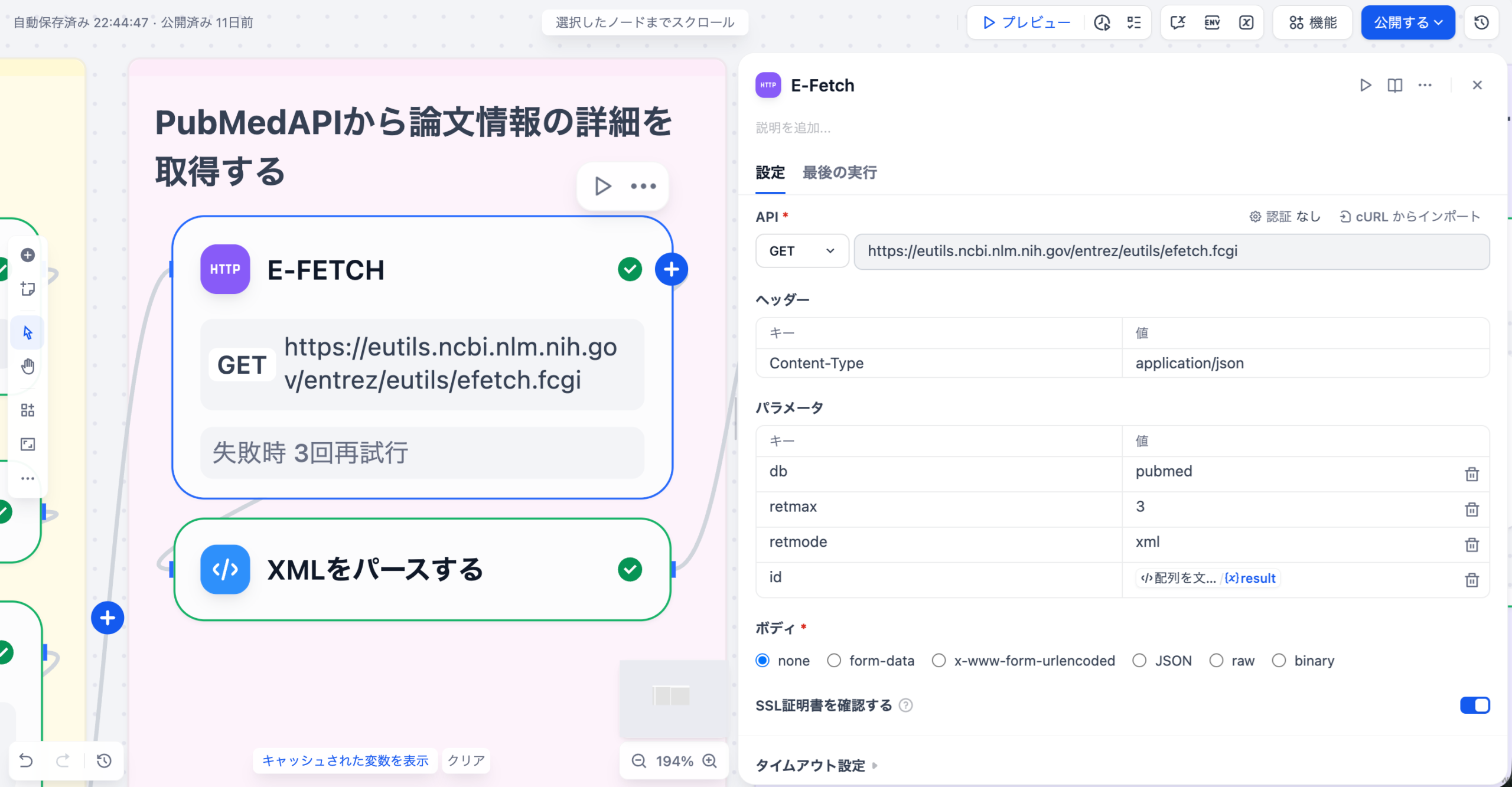
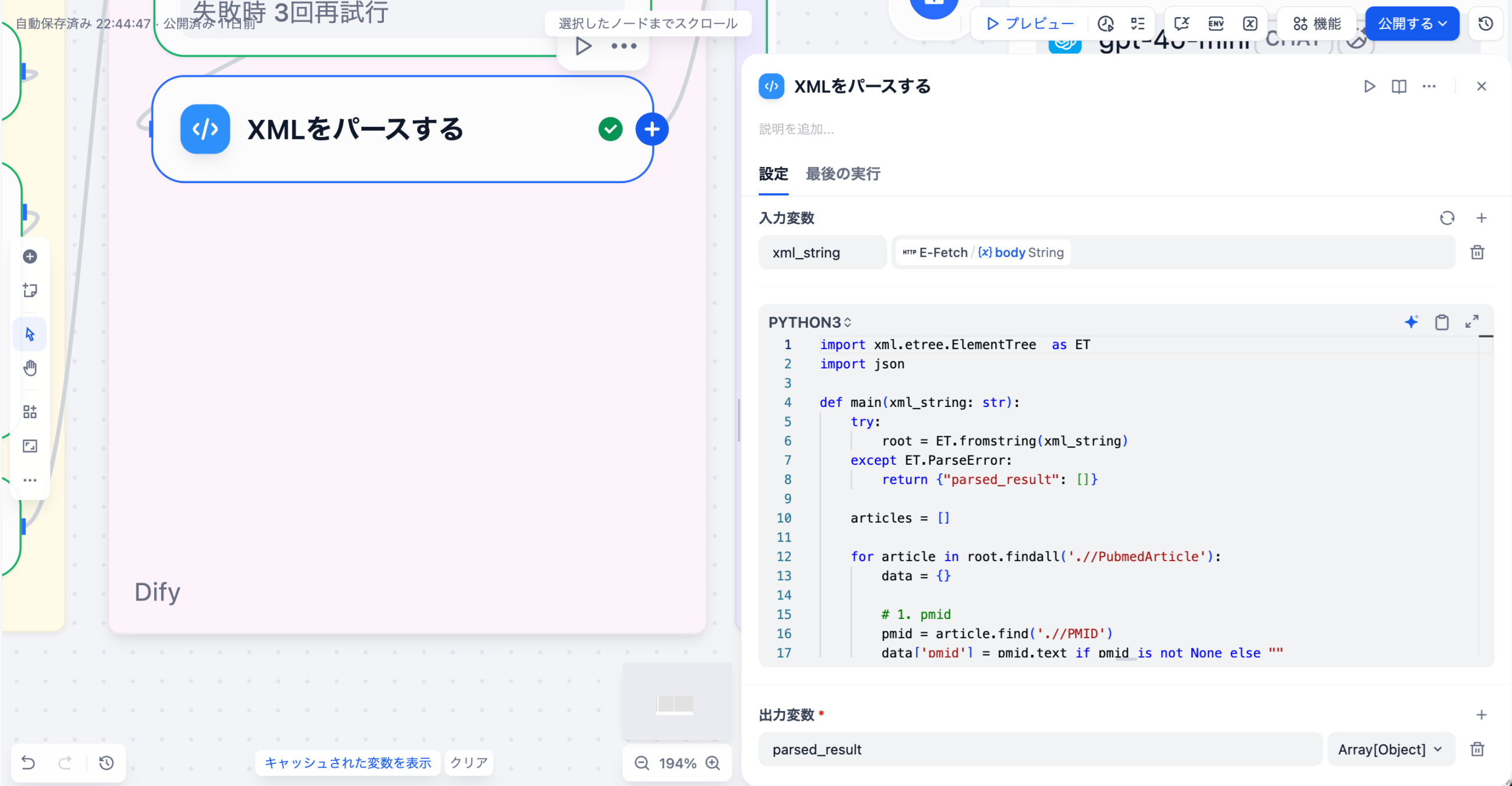
DifyなどのAIプラットフォームがDPCデータを言語化するプロセスは、高度なプロンプトエンジニアリングとデータ連携によって成り立っています。まず、DPC分析ツールが出力した集計データやベンチマーク結果(CSV、JSON形式など)をAIの入力データとして取り込みます。このデータは、特定の疾患群(例:脳梗塞、大腿骨頸部骨折)における平均在院日数、医療資源投入量、DPC入院期間II未満の比率といった具体的な数値情報です。
DPC分析結果(数値)と、提案書作成の目的(例:在院日数短縮、薬剤費削減)をLLMに入力。「病院経営層向けに、具体的な数値目標を含む提案書を作成せよ」といった明確な指示(プロンプト)を与える。
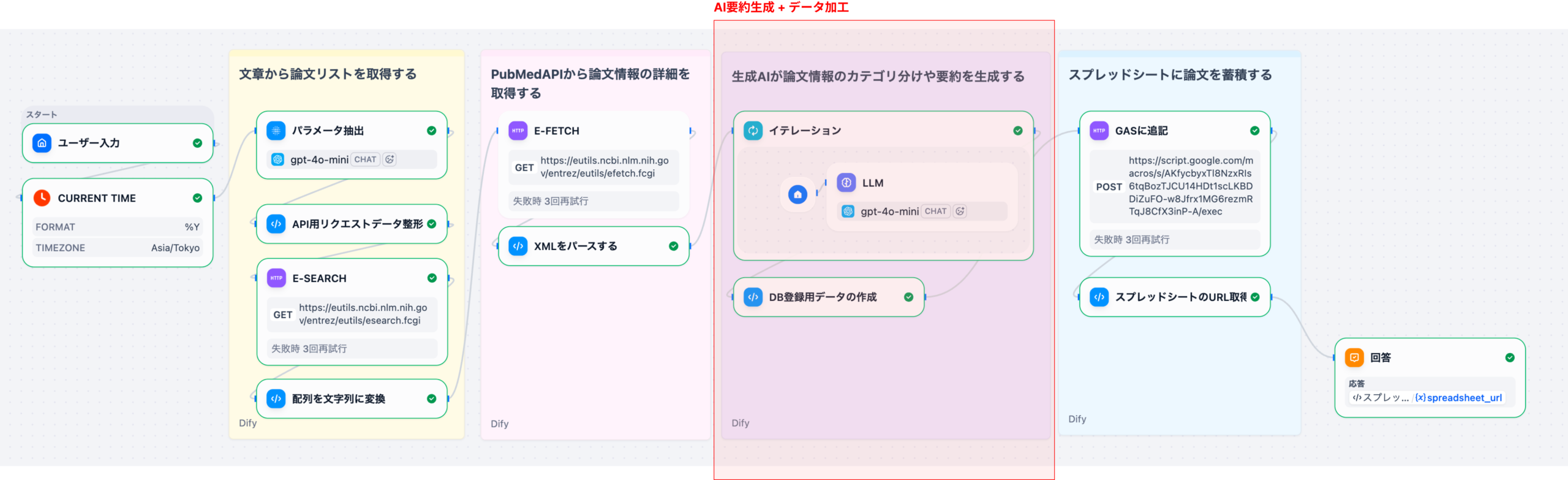
LLMが、入力データに基づき「現状分析(データ引用)」「課題の深掘り(論理的考察)」「改善策の提示(クリニカルパス見直しなど)」「期待される効果(数値目標)」という提案書の論理構造を自動的に構築する。
生成された提案書ドラフトを、病院の専門家が最終チェック。生成AIの機能には、引用元となる電子カルテ情報(DPCデータの元情報)を関連付けて表示する機能もあり、ハルシネーション(尤もらしい嘘)対策として信頼性を高めます。この検証フェーズが、最終的な文書の品質を保証します。
この一連のプロセスにより、人間はデータ収集や文書構造の構築といった定型作業から解放され、AIが出した論理構造の調整や、現場に合わせた具体的な数値の微調整といった、より付加価値の高い作業に集中できるようになります。
4. AIが生成する「改善提案書」の具体的な構成要素と品質
AIアシスタントが生成する改善提案書は、単なる分析結果の羅列ではなく、実行可能なアクションプランを含む、説得力の高いビジネス文書としての品質を確保します。その構成要素は、病院経営の意思決定を支援するために最適化されています。
- 現状分析と課題特定:ベンチマーク分析に基づき、自院の平均在院日数が全国平均より長い疾患群(例:肺炎、心不全など)を特定。具体的な日数差(例:2.5日超過)を明記し、収益への影響額を試算します。
- 課題の深掘り(Why):DPCデータの詳細(手術・処置の実施時期のばらつき、薬剤費の診療科間格差など)を引用し、在院日数超過の背景にある要因(例:術前日数の長期化、退院支援の遅れ)を論理的に提示します。
- 具体的な改善策とアクションプラン:「クリニカルパスの見直し」や「地域連携室の強化」など、課題に直結する具体的な解決策を提案。実施スケジュールや担当部署を盛り込み、実行可能性を高めます。
- 期待される効果(KPI):改善策の実施により見込まれる数値的効果(例:平均在院日数の3ヶ月後の1日短縮、年間約2000万円の収益改善)を定量的に示し、投資対効果を明確にします。
このAIが生成する文書は、論理構造が明確で、根拠となるデータが明示されるため、多忙な経営層や医師会での議論を円滑に進めるための強力なツールとなります。特に、分析結果から「クリニカルパスの見直しを含め早急の対策を要する」疾患群を自動的に特定できる点は、専門家による手動分析の負荷を劇的に軽減します。
5. AI活用による病院経営改善の事例と数値的効果
DPCデータ分析に基づいたAIによる言語化支援は、既に様々な形で病院経営に具体的な効果をもたらし始めています。特に、分析結果の「実行への接続」がスムーズになることで、経営改善のスピードが向上します。
例えば、ある病院ではDPCデータ分析の結果、疾患別に入院期間II未満の比率を解析したところ、特定の疾患で入院期間II未満の比率が減少傾向にあることが判明しました。このデータをAIが言語化し、「クリニカルパスの見直しを含め早急の対策を要する」という具体的な提案書を作成した結果、迅速な対応が可能となり、診療効率の改善に繋がりました。また、診療科によって入院期間II未満の比率に明らかな格差があることも重要課題として浮き彫りになり、AIが作成した提案書を通じて、診療科間の是正に向けた議論を加速させることができました。
また、AIによる文書作成支援は、医師の働き方改革にも直結します。医師が医療文書作成にかける時間を年間数十時間単位で削減できるという試算もあり、これにより、医師は本来のコア業務である患者ケアや医療の質向上に集中できるようになります。DPCデータ分析、AI言語化、改善実行という一連のサイクルを確立することで、病院は単なるコスト削減に留まらず、医療の質と収益性の両立を実現することが可能です。
6. 導入・運用における補足情報とデータセキュリティ
DifyのようなAIアシスタントをDPCデータ分析に導入する際には、医療情報を取り扱う上での厳格なセキュリティと運用ルールを遵守することが不可欠です。DPCデータは、厚生労働省が定める「匿名診療等関連情報」として、医療の質向上や病院経営の改善に役立てるために匿名加工後のデータが第三者に提供されています。そのため、AI活用においても、データの匿名性と安全性を確保する必要があります。
導入初期には、AIが生成する提案書の品質を担保するため、特定の疾患や診療科に特化したプロンプトのチューニング(調整)が重要となります。また、将来的には、他の情報と照合しない限り特定の個人を特定できないよう加工した「仮名化情報」の二次利用も可能とする方針が示されており、より高度なデータ連携と分析が可能になる見込みです。AI導入は、単なるツールの導入ではなく、データ活用文化の定着とセキュリティ体制の強化を伴う、全病院的なDXの取り組みとして位置づけるべきです。
DPCデータをAIにインプットする際は、個人が特定されないよう、厚生労働省の「匿名診療等関連情報の提供に関するガイドライン」を厳格に遵守することが必須です。データは暗号化され、利用目的が制限された環境下で取り扱う必要があります。AIが生成した提案書は、必ず医師や経営専門家が最終的な内容確認と承認を行うプロセスを設けるべきであり、AIの出力をそのまま最終決定とすることは避けてください。
まとめ
DPCデータ分析をDifyのような大規模言語モデル(LLM)が言語化し、具体的な「改善提案書」を作成するアシスタントは、病院経営におけるデータ活用の課題を根本から解決するソリューションです。分析結果を経営層に響く論理的な文書に変換するボトルネックを解消することで、提案書作成にかかる時間を大幅に短縮し、データ分析から業務改善実行までのリードタイムを劇的に短縮します。これにより、平均在院日数の短縮や薬剤費の適正化など、具体的な数値目標達成に向けたPDCAサイクルが加速されます。導入にあたっては、厚生労働省のガイドラインを遵守した匿名化・仮名化情報の厳格なセキュリティ管理が必須ですが、このAI活用は、医師の働き方改革と病院の収益性向上を同時に実現する、医療DXの新たな基盤となるでしょう。今こそ、AIによるデータ言語化を取り入れ、データドリブンな病院経営へと転換を図るべきです。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")
")

")


")
")
")
")
")
")