1. はじめに
この記事を読むと、以下のことができるようになります:
X API の基 本的 な仕組み を 理 解 でき る :X APIの使い⽅や、基本的なエンドポイントについて理解できますX API の トークンを 取得でき る :Difyで使うために必要なBearer Tokenを取得する⼿順が分かります
重要 :この記事では、X APIの仕組みを理解するために、簡単なPythonコードの例を紹介します。ただし、コードを書くこと⾃体が⽬的ではありません。実際のソーシャルリスニングアプリは、次回のPart2で紹介するDifyというツールを使って作成します。
シリーズ構成
Part0 : X APIを⽤いたソーシャルリスニング概要Part1(本記事): X APIの基礎 Part2 : Difyを⽤いてX APIから直近のポストを取得するPart3 : LLMを⽤いて⾃動でデータラベルを付与するPart4 : スプレッドシートにデータを格納するPart5 : Streamlitを⽤いたデータの可視化例
2. X APIとは?
X API X(旧Twitter)のデータや機能にプログラムからアクセスするための公式インターフェース
特定のキーワードやハッシュタグを含むポスト(旧ツイート)を、条件付きでまとめて取得する
定期的にポストを取得して、世論の変化や話題の盛り上がりを追いかける
取得したポストをスプレッドシートやデータベースに保存し、可視化‧分析に回す
X APIにアクセスするためには、「開発者としてこのAPIを使う権限がある 」ことを証明するトークン(Bearer Token
3. X APIの料⾦プラン
2026年1⽉現在、X APIにはいくつかの料⾦プランがあり、それぞれで以下のような違いがあります。
3-1. 主なプランの違い 以下は、X APIの代表的なプランの簡単な⽐較表です。プランに応じて、使えるAPIの種類やリクエスト制限、取得上限などが細かく設定されています。
X APIの有料プランを契約する際は、X APIを⽤いて実現したい施策が、契約予定のプランで実現可能かどうかを⼗分に吟味することが重要です。
プラン名 ⽉額料⾦ 向いている⽤途 Free 無料 個⼈の学習やプロトタイプ Basic $200前後 ⼩規模なビジネス⽤途 Pro $5,000前後 ⼤規模な分析や本格運⽤ Enterprise 要問い合わせ ⼤企業‧本番システム向け
※料⾦や制限は変更される可能性があります。最新情報は X Developer Platform
3-2. 学習‧プロトタイプの観点からのおすすめ
学習‧検証フェーズ
まずはFreeプランで問題ありません。
一方で15分に1回リクエストしか送れないなどの制限が厳しく、分単位で実⾏したい場合などには不向きです。
簡単なソーシャルリスニングアプリを定期実⾏したくなったら
Freeプランだと、⽉間上限やレート制限にすぐ到達してしまいます。
定期実⾏を⾏う⽤途では、Freeプランだけでは不⼗分です。
X APIを⽤いて実現したい内容がある程度固まってきたタイミングで、より上位のBasicプランを検討すると良いでしょう。
3-3. X APIでできること ここでは、よく使われる代表的なエンドポイント
HTTP メソッド & パス 主な⽤途 ユーザーの取得 GET /2/users ユーザー ID や username を指定してユーザー情報を取得する。 特定ポストの取得 GET /2/tweets ツイート ID を指定して、1件〜複数件のツイートを取得する。 ポストの投稿 POST /2/tweets 新しいツイート(ポスト)を投稿する。 ポストの検索 GET /2/tweets/search/recent キーワードなどのクエリで、直近数⽇〜7⽇程度の公開ツイートを検索する。
X APIには他にも多様なエンドポイントが⽤意されています。さらに詳しく知りたい⽅は公式の開発者ドキュメントをご参照ください。
https://developer.x.com/en/docs/x-api
4. X APIを実際に使ってみる
ここからは、次の3ステップで実際にX APIを動かしてみる流れを説明します。
X Developer アカウント と アプリを 作成す る Bearer Tokenを取得する Pythonでポストを検索してみる
X APIが「どのようなリクエストを受け取り、どのようなレスポンスを返すのか」を⼀度体験しておくと、次回のDifyによるAPI操作がかなりスムーズになります。
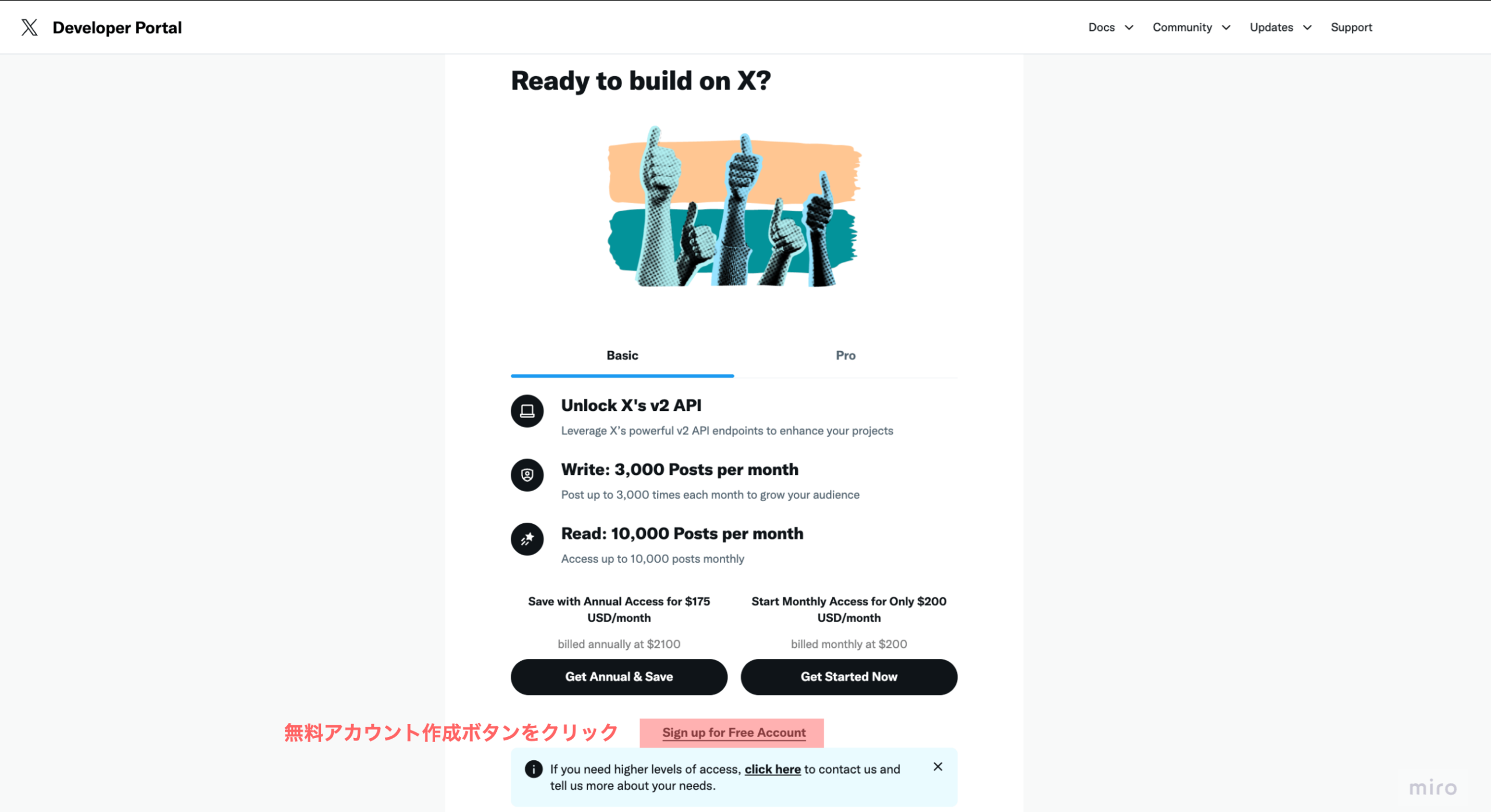
4-1. X Developerアカウントとアプリの作成 ステップ 1 : X Developer Portal に アクセス す る
X Developer Portal 無料アカウントの作成へと進みます。
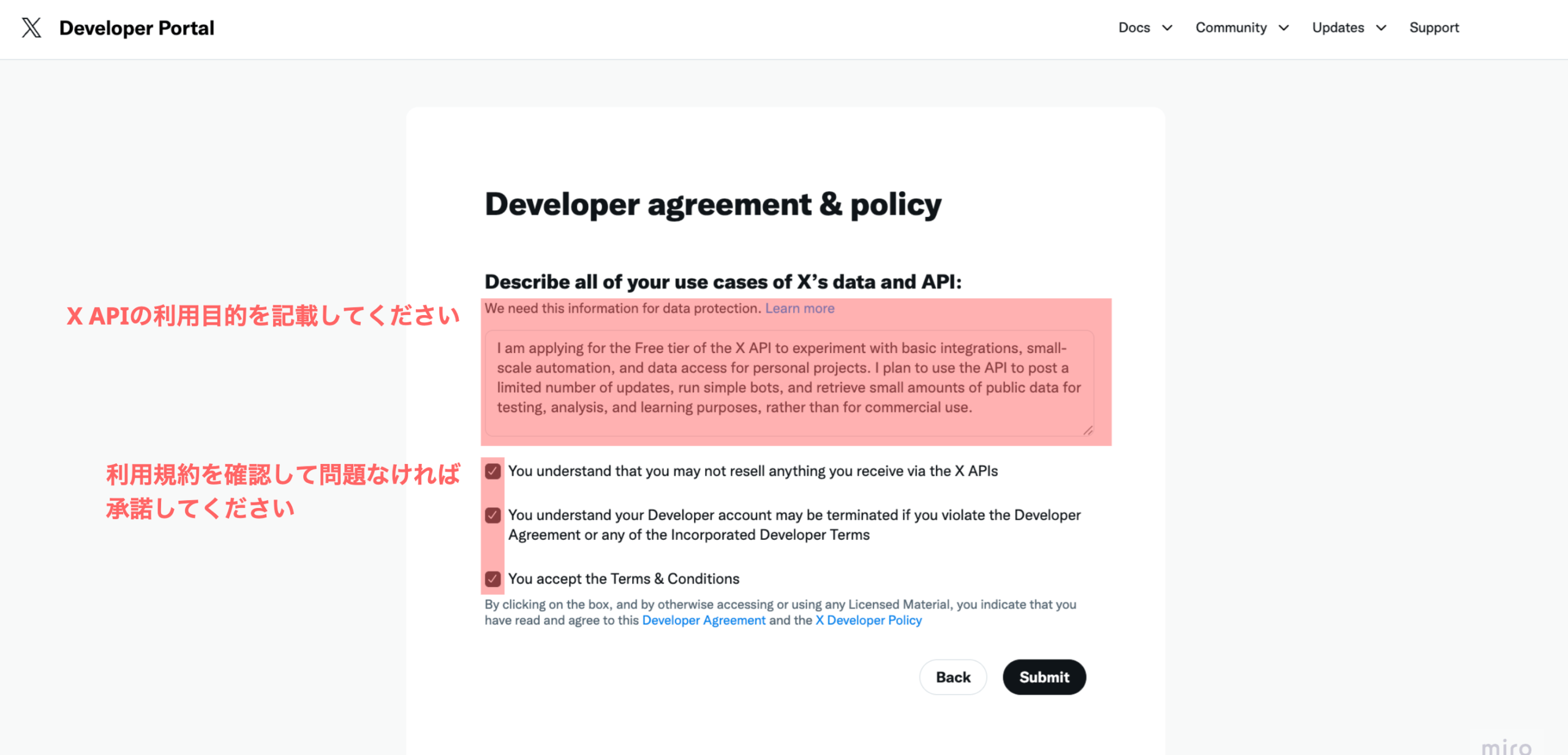
ステップ2: 利⽤⽬的や規約へのチェックボックスに承諾をつけます。X APIに関する詳しい説明を知りたい場合は、公式ドキュメントを参照してください。
X APIはAPI制限もそうですが、利用規約にも細かいルールが存在します。論文情報のように広く提供されるデータではありません。
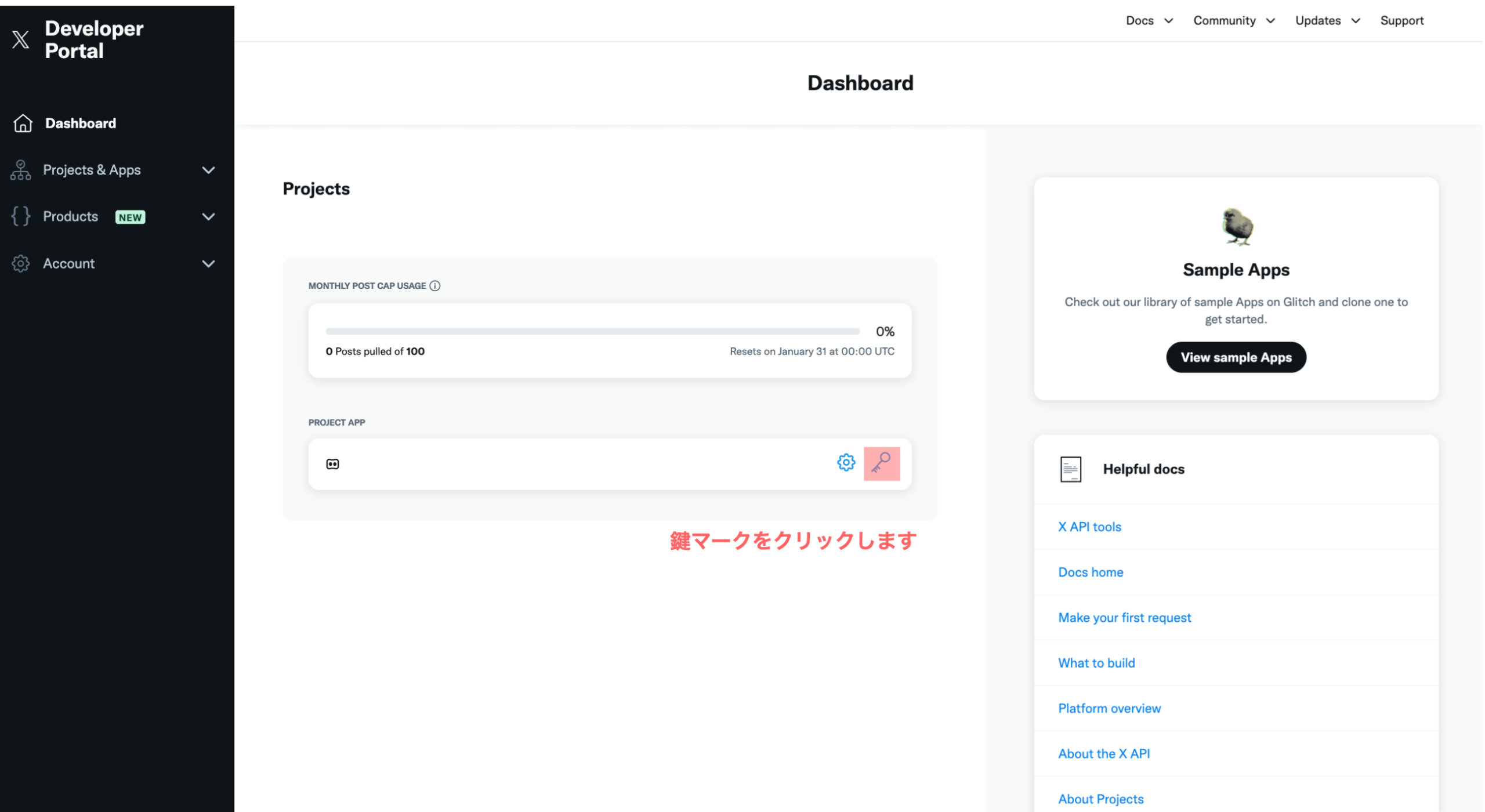
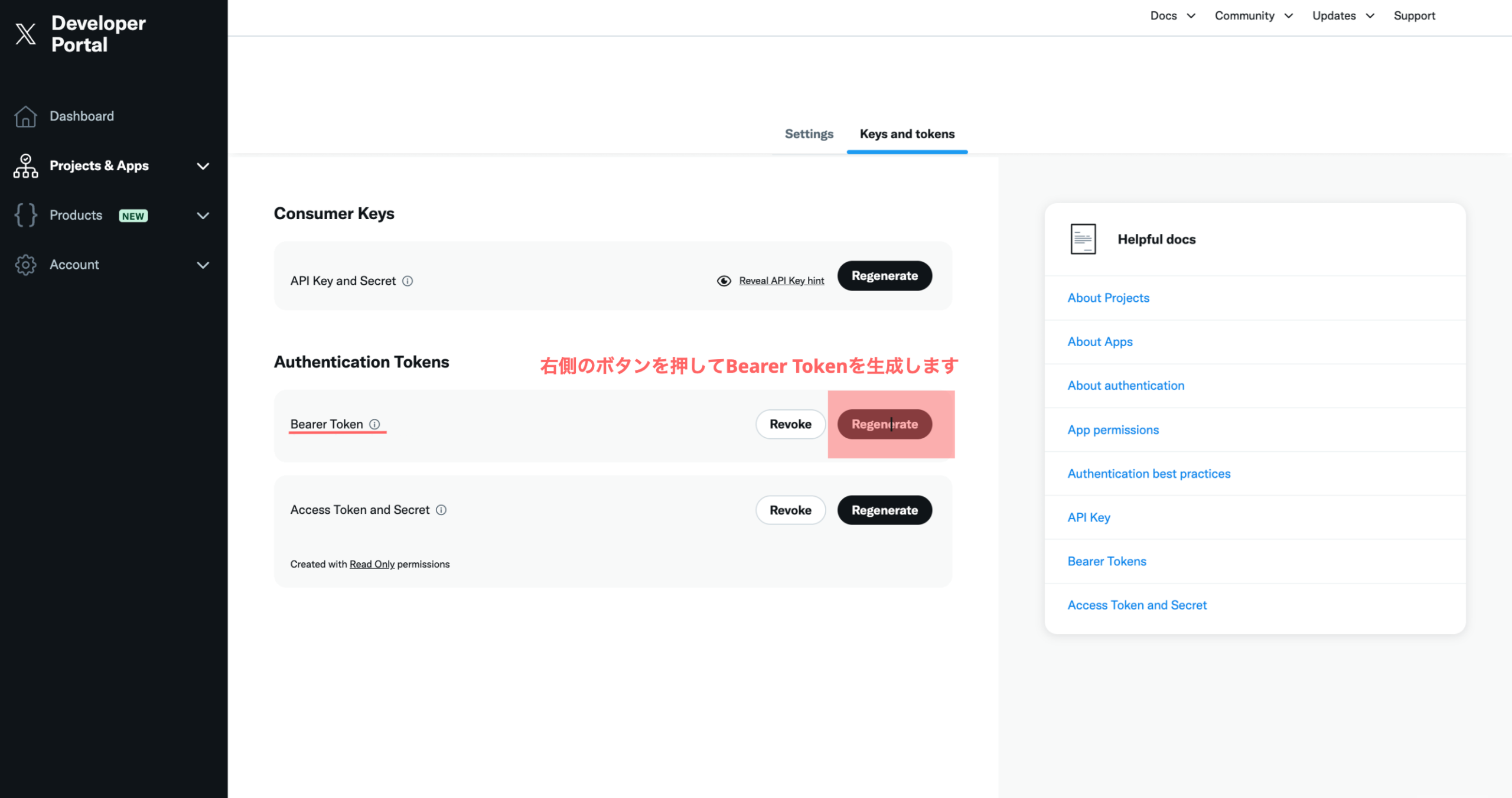
4-2. Bearer Tokenを取得する 続いて、X APIにアクセスするための鍵であるBearerToken
作成したアプリの詳細画⾯を開き、鍵マークをクリックします。
「Generate」もしくは「Regenerate」ボタンを押します。
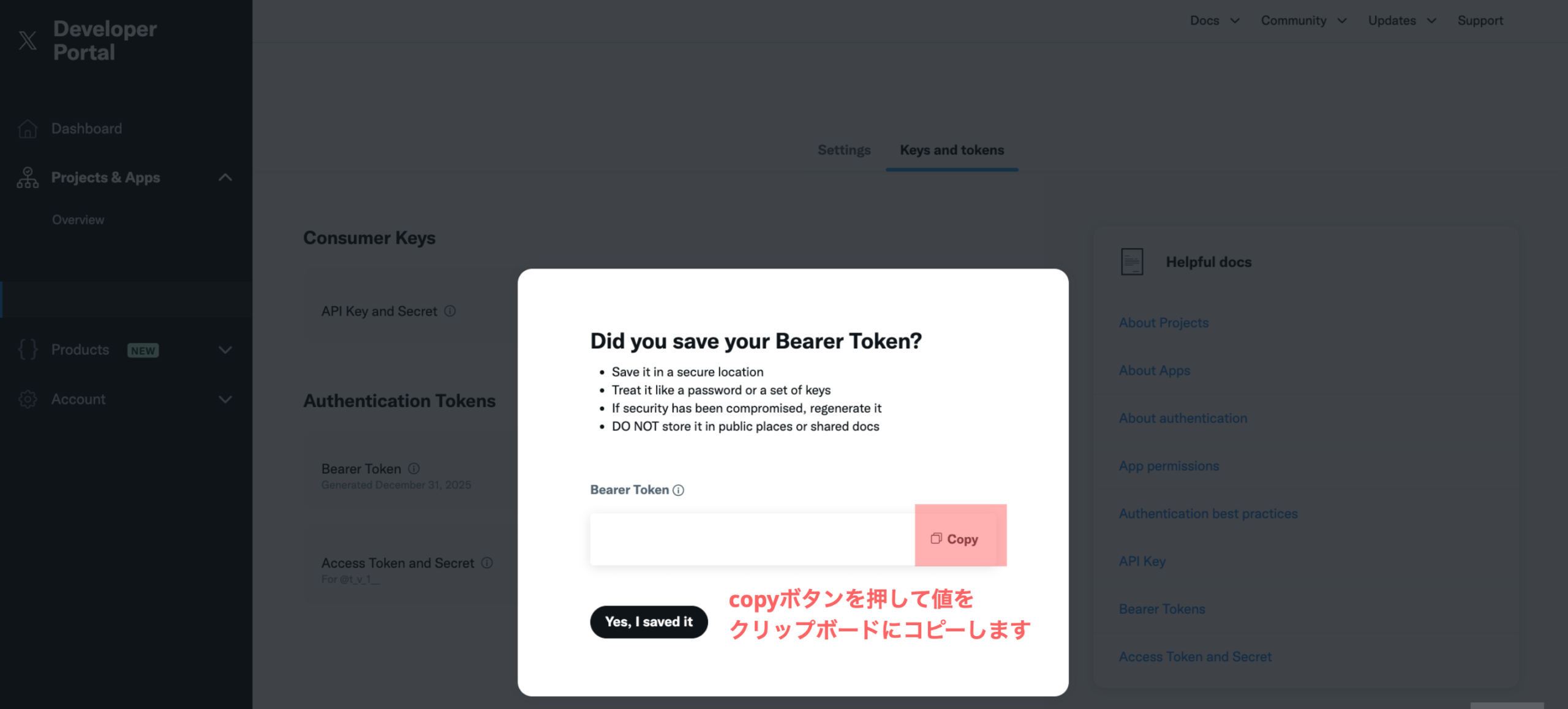
以下のような画⾯が出てくるので、コピーボタンを押してTokenをコピーします。
重要: ⼀度しか表⽰されない
■ 安全な場所への保管⽅法
例えば次のような⽅法で保管しておくと安⼼です。
パスワード管理ツールに保存する
ローカルPCの安全なテキストファイルに保存する
後でDifyの「環境変数」や「シークレット」に登録して使う
この記事では後ほど、Pythonコードの例の中で、環境変数からBearer Tokenを読み込む⽅法も紹介します。
4-3. Google Colabを⽤いてポストを取得する ここでは、Google Colab
ブラウザだけで完結する
無料で使える
すぐにコードを試して壊してやり直せる
といった理由から、初 回の「まず 触 ってみ る 環境」 として Colab は相性が良いです。
X公式のGitHubリポジトリでもAPIの叩き⽅について解説されています。Pythonコードを読むことに抵抗がない⽅は、公式のサンプルも合わせてご参照ください。
https://github.com/xdevplatform/samples/blob/main/python/posts/search_recent.py
ただし、公式サンプルはAPIへの複数リクエストを前提としており、Freeプランではそのまま実⾏するとレート制限でエラーになる可能性があります。
本記事のサンプルは、Google Colabに簡単なコードを貼り付けるだけでAPIリクエストを体験できるように調整しており、Freeプランでも問題なく動かせる想定です。ぜひご⾃⾝の環境で試してみてください。
ここからは次の流れで進めます。
Colab ノートブックを開く
Bearer Token を安全にノートブックに読み込む
Python で Recent Search エンドポイントを叩く
取得したポストのテキストと作成⽇時を表⽰してみる
■ Google Colab を開く
ブラウザで Google Colab
Google アカウントでログインします。
右上の「新しいノートブック」 をクリックします。
これで、ブラウザ上で Python コードを実⾏できる空のノートブックが⽤意できました。
■ Colab に Bearer Token を安全に読み込む
X API を叩く際、X Developer Portal で先ほど発⾏した Bearer Token を利⽤します。ここでは、コードに直書きせずに Colab の「環境変数」として読み込む⽅法を紹介します。
Colab の先頭セルに、次のコードを貼り付けて実⾏します。
"""
step1. X APIのDeveloper PortalからBEARER_TOKENを設定する
"""
import os
# 環境変数としてX APIのBEARER_TOKENを設定する
os.environ['BEARER_TOKEN'] = input('表示される箇所に、先ほど取得したX API用のBEARER TOKENを貼り付けてください')
# もし未入力であればエラーで処理を中断する
if not os.environ['BEARER_TOKEN']:
raise ValueError('BEARER_TOKENが入力されていません')
# 環境変数として設定した値を、変数に格納する
bearer_token = os.environ['BEARER_TOKEN']
print('正しく設定できましたので、次のステップを実行してください')
セルを実⾏すると、ノートブックに⼊⼒欄が表⽰されます。
X Developer Portal でコピーした Bearer Token
⼀度実⾏して先ほど取得した Bearer Token を貼り付けてからEnterを押します。⾚い⽂字でエラーが表⽰されなければ次のステップに進めます。もしエラーが表⽰された場合は、 Bearer Token の⼊⼒ができていない可能性があるため、再度再⽣ボタンからセルを実⾏し、値をペーストし直してください。
■ Recent Search エンドポイントを叩く Python サンプル
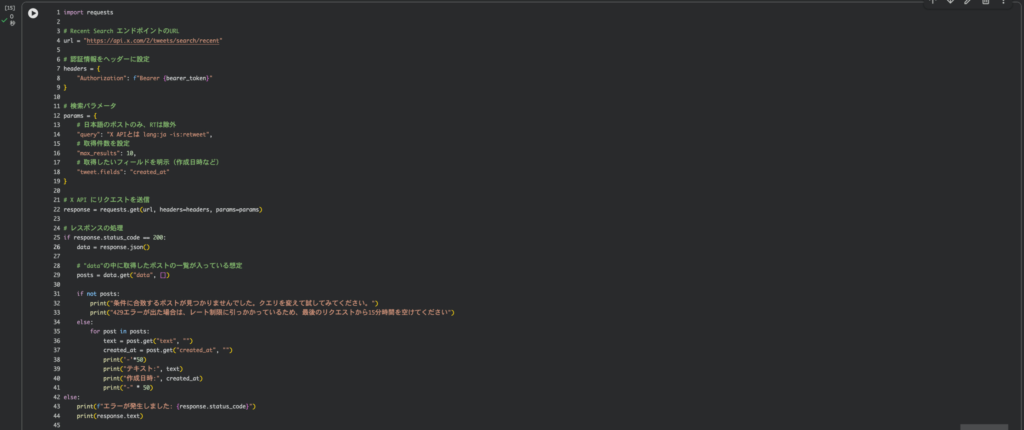
ここまで準備ができたら、いよいよ X API を叩いてみます。以下は、Recent Search を使って、特定キーワードを含む直近のポストを取得する最⼩限のコード例です。
import requests
# Recent Search エンドポイントのURL
url = "https://api.x.com/2/tweets/search/recent"
# 認証情報をヘッダーに設定
headers = {
"Authorization": f"Bearer {bearer_token}"
}
# 検索パラメータ
params = {
# 日本語のポストのみ、リポストは除外
"query": "X APIとは lang:ja -is:retweet",
# 取得件数を設定
"max_results": 10,
# 取得したいフィールドを明示(作成日時など)
"tweet.fields": "created_at"}
# X API にリクエストを送信
response = requests.get(url, headers=headers, params=params)
# レスポンスの処理
if response.status_code == 200:
data = response.json()
# "data"の中に取得したポストの一覧が入っている想定
posts = data.get("data", [])
if not posts:
print("条件に合致するポストが見つかりませんでした。クエリを変えて試してみてください。")
print("429エラーが出た場合は、レート制限に引っかかっているため、最後のリクエストから15分時間を空けてください。")
else:
for post in posts:
text = post.get("text", "")
created_at = post.get("created_at", "")
print("-" * 50)
print("テキスト:", text)
print("作成日時:", created_at)
print("-" * 50)
else:
print(f"エラーが発生しました: {response.status_code}")
print(response.text)
■ コードの要点を解説(簡単に)
Bearer Token の扱い
bearer_token = os.environ.get(“BEARER_TOKEN”) 前のセルでos.environ[“BEARER_TOKEN”] = input(…) としているため、ノートブックの中でos.environ.get(“BEARER_TOKEN”) で安全に参照できます。
認証ヘッダー
headers = {“Authorization”: f”Bearer {bearer_token}”}
HTTP ヘッダーにAuthorization: Bearer … を付与することで、X API に対して「このユーザーとしてアクセスする」ことを⽰しています。
検索クエリ
params[“query”] が検索条件を表す⽂字列です。例えば次のように書くことで、⽤途に応じたソーシャルリスニングができます。
“ソーシャルリスニング lang:ja”
⽇本語のポストのみを対象に、「ソーシャルリスニング」を含むものを取得
“⼦宮頸がんワクチン -is:retweet lang:ja”
指定キーワードを含み、リポストを除外し、⽇本語のみを対象にするクエリ
レスポンスとエラーハンドリング
response.status_code == 200 のときが「リクエスト成功」です。それ以外のステータスコード( 401 や 429 など)の場合は、
認証エラー(Token 設定ミス)
レート制限超過response.text をそのまま表⽰して原因を確認します。
4-4. このサンプルで体験できること ここまでの Colab + Python のサンプルを⼀度でも動かしてみると、
Bearer Token を 使って 認証 す る query パラメータ で 検 索 条 件 を 指 定 す る JSON で 返 ってきた結果 を Python で 処 理す る
という X API 利⽤の基本パターンを⼀通り体験できます。
実際のソーシャルリスニングアプリでは、ここで⾏っている処理とほぼ同じことを、次回紹介する Dify のワークフロー上で組み⽴てていきます。
5. まとめ
5-1. 本記事で学んだこと 本記事(Part1)では、以下の内容を学びました:
X API とは :Xのデータや機能にプログラムからアクセスするためのインターフェースBearer Token の取得 ⽅ 法 :X Developer Portalでアプリを作成し、Bearer Tokenを取得する⼿順RecentSearchエンドポイント :過去7⽇間のツイートを検索できるエンドポイント 料⾦プラン :まずはFreeプランから始めることをおすすめ
5-2. Difyを⽤いたローコード開発 今回、Pythonコードを直接書いてX APIからツイートを取得する⽅法を紹介しました。これは、X APIの仕組みを理解するうえで重要なステップです。
ただし、実際のソーシャルリスニングアプリを構築する際は、Difyのようなワークフロー⾃動化ツール
直感 的 な ブロック 操作 :ブロックを配置していくことで処理を実装可能定期実⾏ の ⾃ 動 化 :スケジュールトリガーで定期的にツイートを取得LLM との連携 :取得したツイートに対して、LLMで⾃動的に感情分析やラベリングを実⾏
次回のPart2では、Difyを⽤いてX APIから最新のツイートを⾃動取得する⽅法について詳しく解説します。具体的には、次のようなテーマを扱う予定です:
Difyのワークフローエディタの使い⽅
HTTPリクエストノードでX APIを呼び出す⽅法
スケジュールトリガーによる定期実⾏の設定
データの整形と後続処理への受け渡し
シリーズ構成
Part0. X APIを⽤いたソーシャルリスニング概要
Part1. X(旧Twitter) APIの基礎(本記事)
Part2. Difyを⽤いてX APIから直近のポストを取得する(←次の記事) Part3. LLMを⽤いて⾃動でデータラベルを付与する
Part4. スプレッドシートにデータを格納する
Part5. Streamlitを⽤いたデータの可視化例
ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
提供サービスの例
製薬・医療機器業界での提案活動や調査業務の自動化支援
アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。お問い合わせフォームはこちら
監修者 株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中
")

")
")
")
")

")



")
")
")
")