")
Difyは日本語で使える?インストールからRAG構築までの基本ガイド
Difyは日本語で使える?インストールからRAG構築までの基本ガイド
Dify(ディフィー)は、プログラミングスキルがなくても高品質なAIアプリケーションを開発できる、オープンソースのプラットフォームです。RAG(検索拡張生成)機能の組み込みが容易なことから、特に社内ナレッジを活用したチャットボット開発ツールとして注目を集めています。本記事では、「Difyは日本語で利用できるのか」という疑問から、セルフホストでのインストール方法、そしてDifyの最大の特長であるRAGアプリケーションの基本的な構築手順までを、メディカル・テクニカルライターの視点から徹底的に解説します。
Dify(ディフィー)とは?その特徴と主要機能
Difyは、ノーコード(No-code)やローコード(Low-code)でAIアプリケーションを開発できるオープンソースのプラットフォームです。大規模言語モデル(LLM)の活用を容易にし、専門知識がなくても独自のAIサービスを迅速に構築できる点が最大の魅力です。
- ノーコード・ローコード開発: プログラミングの知識が少なくても、直感的なインターフェース(UI)操作だけで、チャットボットやコンテンツ生成システムなどのAIアプリを作成できます。
- RAG(検索拡張生成)エンジンの標準搭載: 外部のナレッジベース(業務マニュアル、PDF、Webサイトなど)を参照し、より正確で最新の情報に基づいた回答を生成するRAG機能が標準で組み込まれています。これにより、AIの「ハルシネーション(幻覚)」の削減と、ドメイン特化の知識活用が可能になります。
- 多様なLLMへの対応: OpenAIのGPTシリーズ、AnthropicのClaude、さらにはローカルモデルなど、多様なLLMと柔軟に接続・切り替えが可能です。
- オープンソース: Apache License 2.0で公開されており、クラウド版(SaaS)と自社サーバーにデプロイするセルフホスティング版の選択が可能です。企業のセキュリティ要件に応じて利用環境を選べる柔軟性を持っています。
Difyの日本語対応状況と利用上のメリット
ユーザーが最も気になる「Difyは日本語で使えるか」という点について、結論から言うと、Difyは日本語に完全に対応しています。
まず、作成するAIアプリケーション自体は、LLMが日本語に対応していれば、高い精度で日本語の入出力に対応可能です。これにより、敬語や文脈を理解した自然な日本語での対話やコンテンツ生成を実現できます。
さらに、Difyの管理画面(UI)についても、日本語対応が進んでおり、日本語での操作が可能です。これにより、英語のドキュメントやインターフェースに不慣れな日本のビジネスユーザーや非エンジニアでも、安心してAIアプリケーションの開発・運用を進めることができるのが大きなメリットです。
また、日本国内では大手IT企業がDifyの正規代理店として販売・サポートを行っている事例もあり、日本語での導入サポート体制も整ってきています。
セルフホスト環境の構築:Dockerを使ったインストール手順(概要)
Difyを自社のセキュリティ環境下で利用したい場合や、クラウド版の制限を受けたくない場合は、セルフホスティング版(ローカル環境や自社サーバーへのデプロイ)が選択肢となります。Difyのセルフホストは、DockerおよびDocker Composeを利用した方法が最も一般的で推奨されています。
基本的なインストール手順は以下の通りです。
- 事前準備: Git、およびDocker Desktop(Docker EngineとDocker Composeを含む)を、利用するOS(Windows/Mac/Linux)に合わせてインストールします。Difyの推奨動作環境として、CPU 2コア以上、RAM 4GB以上などが目安とされます。
- ソースコードのクローン: DifyのGitHubリポジトリからソースコードをローカル環境にクローンします。
- 設定ファイルの準備: クローンしたディレクトリ内のDocker関連フォルダに移動し、環境変数のサンプルファイル(
.env.example)をコピーして、実際に利用する環境ファイル(.env)を作成します。 - Docker Composeの起動: ターミナルで
docker compose up -dコマンドを実行し、Difyに必要なAPI、Web、DB(PostgreSQL)、Redis、Weaviate(ベクトルDB)などの全コンテナを一括で起動します。 - 初期設定: 起動後、ブラウザから指定されたローカルホストのURL(例:
http://localhost/install)にアクセスし、管理者アカウントの設定と初期ログインを行います。
この方法により、Difyに必要な複数のコンポーネントがコンテナ技術によって一括管理され、スムーズな導入が可能となります。
Difyの基本的な使い方:RAGアプリケーションを構築する流れ
Difyの利用目的の多くは、独自の知識に基づいたRAGチャットボットの構築です。ここでは、データを取り込み、チャットボットとして公開するまでの基本的な手順を紹介します。
- 新規アプリケーションの作成: ログイン後、「スタジオ」画面から「最初から作成」を選択し、アプリケーションタイプとして「チャットボット」または「テキスト生成器」を選びます。
- ナレッジベースの作成: アプリケーションとは別に、RAG機能で参照させたい情報源(ナレッジ)を登録します。画面上部の「ナレッジ」タブから「ナレッジの作成」へ進みます。
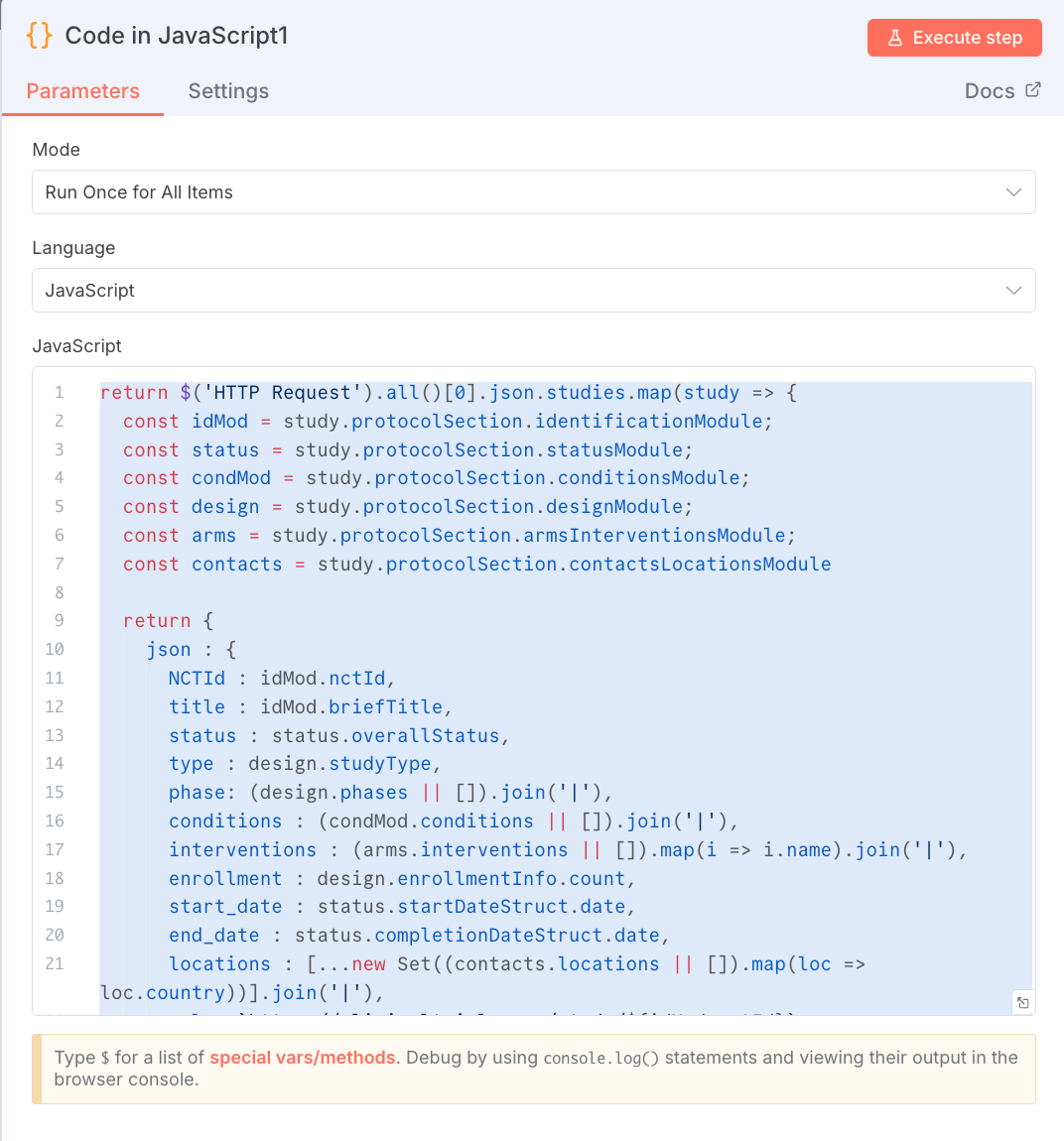
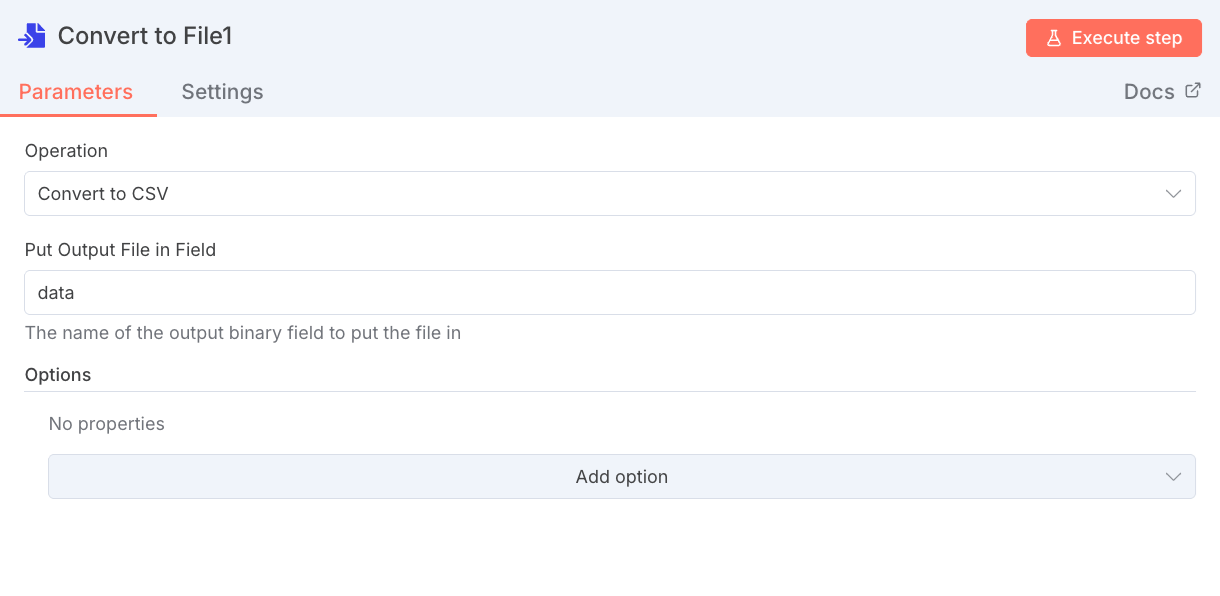
- ドキュメントのアップロードとインデックス化: 参照させたいPDFファイル、テキストファイル、Webページなどをアップロードします。アップロード後、Difyはデータを細かく区切る「チャンク分割」と、それをベクトルデータに変換する「インデックス化」を自動で行います。この際、チャンクサイズや重複率などの設定を調整することで、RAGの精度を向上させることが可能です。
- アプリケーションへのナレッジの組み込み: 作成したチャットボットの編集画面に戻り、「コンテキスト(ナレッジ)」設定で、作成済みのナレッジベースを有効化します。これにより、ユーザーからの質問に対し、登録したナレッジベースを参照して回答する仕組みが完成します。
- 公開と利用: プロンプトやモデル設定を調整した後、作成したアプリケーションを公開します。公開されたアプリはWebリンクやAPI経由で利用可能となり、社内での問い合わせ対応や情報検索などに活用できます。
このようにDifyは、高度なRAGシステム構築を、ノーコードの直感的なUIで実現できるため、AI開発のハードルを大きく下げています。
まとめ
Dify(ディフィー)は、ノーコード・ローコードでAIアプリを開発できるオープンソースプラットフォームであり、日本語に完全対応しています。UIの一部で英語表示が残る可能性はあるものの、管理画面、そして作成されるAIアプリ自体は高い精度で日本語に対応可能です。セルフホスティングを行う場合は、Docker Composeを使った方法が最も一般的で、比較的容易に環境構築ができます。Difyの最大の強みは、業務マニュアルなどの独自データを活用するRAG(検索拡張生成)機能を、非エンジニアでも直感的な操作で組み込める点にあり、社内のDX推進を強力にサポートするツールとして期待されています。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")
")
")

")
")





")
")
%20and%20an%20elderly%20Japanese%20male%20patient%20(70s)%20are%20in%20a%20bright%20clinic.%20The%20therapist%20is%20pointing%20at%20a%20digital%20tablet%20screen%20that%20displays%20AI-generated%20data%20(graphs%2C%20gait%20analysis)%20while%20the%20patient%20listens%20intently.%20The%20scene%20emphasizes%20human%20expertise%20combined%20with%20AI%20analysis.?width=800&height=500&nologo=true)
