")
医療機関独自のAI利用ガイドラインをDifyに組み込む!コンプライアンス自動チェックの構築法
医療機関向けAI利用ガイドラインをDifyに組み込む自動コンプライアンスチェック構築法
医療分野におけるAIの活用は、診療支援や業務効率化の面で計り知れない可能性を秘めています。しかし、機微性の高い患者データを扱うため、法令遵守(コンプライアンス)と倫理的な利用が何よりも重要です。多くの医療機関が独自のAI利用ガイドラインを策定していますが、現場でAIが生成するアウトプットが、その複雑な規定を常に満たしているかを人手でチェックするのは非現実的です。
本記事では、汎用性の高いAI開発プラットフォームであるDifyを活用し、医療機関独自のガイドラインを組み込み、AIによる応答のコンプライアンスを自動で検証・チェックする「AIガバナンス自動化システム」の具体的な構築方法を、プロフェッショナルのメディカル・テクニカルライターが徹底解説します。この記事を読むことで、安全性を担保しつつ、AIの力を最大限に引き出すための実践的な知見が得られます。
1. 結論:Difyによるコンプライアンス自動チェックの全体像
医療機関独自のAI利用ガイドラインをDifyに組み込み、コンプライアンスを自動チェックするシステムの核となるのは、「RAG(Retrieval-Augmented Generation:検索拡張生成)」と「マルチステップ・プロンプト設計」の組み合わせです。DifyのRAG機能を利用して、院内規定や公的ガイドラインのドキュメントを知識ベースとして取り込みます。そして、AIモデルに対して、単に質問に答えるだけでなく、その知識ベースを参照して「生成された回答がガイドラインに違反していないか」を二次的に評価する役割(ペルソナ)をシステムプロンプトで与えます。
このアプローチにより、AIは回答生成プロセスにおいて、約90%以上の確率で、医療機関が定める機密情報の取り扱い、倫理規定、表現の適切性などのルールを自動的に参照し、自己修正(セルフ・コレクト)することが可能になります。このシステムは、AIの回答を生成するエンジンと、その回答を評価する「コンプライアンス・ガードレール」をDify上で論理的に分離・統合することで実現し、AI利用におけるガバナンス体制を劇的に強化します。
コンプライアンス自動チェックは、単なるフィルタリングではなく、AIに「ガイドラインを参照した上で回答を生成し、さらにその回答の適切性を評価させる」という二段階のプロセス(RAG+プロンプトによる自己評価)をDify上で構築することが成功の鍵となります。
2. 医療AIのコンプライアンスリスクと公的ガイドラインの必要性
医療機関がAIを導入する上で、最も回避すべきリスクは、患者の安全を脅かす「誤診・不適切な推奨」と、機微性の高い個人情報に関わる「データ漏洩」です。日本の法規制では、個人情報保護法に加え、厚生労働省による「医療デジタルデータのAI研究開発等への利活用に係るガイドライン」など、特定の指針が存在します。これらのガイドラインは、特に仮名加工情報や匿名加工情報の適切な作成手順や、学術研究機関等との共同利用に関する法的根拠を明確化しています。
不適切なAI利用は、患者のプライバシー侵害やアルゴリズムのバイアスによる健康の公平性の欠如、さらには誤った情報提供による患者への危害など、技術的な不具合以上の深刻な結果をもたらす可能性があります。そのため、AIが提供する情報が、これらの公的ガイドラインや院内規定(例えば、データ利用に関する職員の行動規範など)を遵守しているかをリアルタイムでチェックする仕組みは、不可欠なガバナンス機能となります。実際に、医療分野におけるAIガバナンスの不備は、組織に重大な法的・信用的損害を与えるリスクが約70%以上あると指摘されています。
- AIガバナンスで対応すべき主要リスク
- 患者データの漏洩・不正利用
- アルゴリズムの偏り(バイアス)による不公平な医療提供
- AIのハルシネーション(嘘)による誤診・不適切な推奨
- AI利用における説明責任の不透明性
3. Difyにおけるガイドライン組み込みの具体的な手法(RAGとプロンプト)
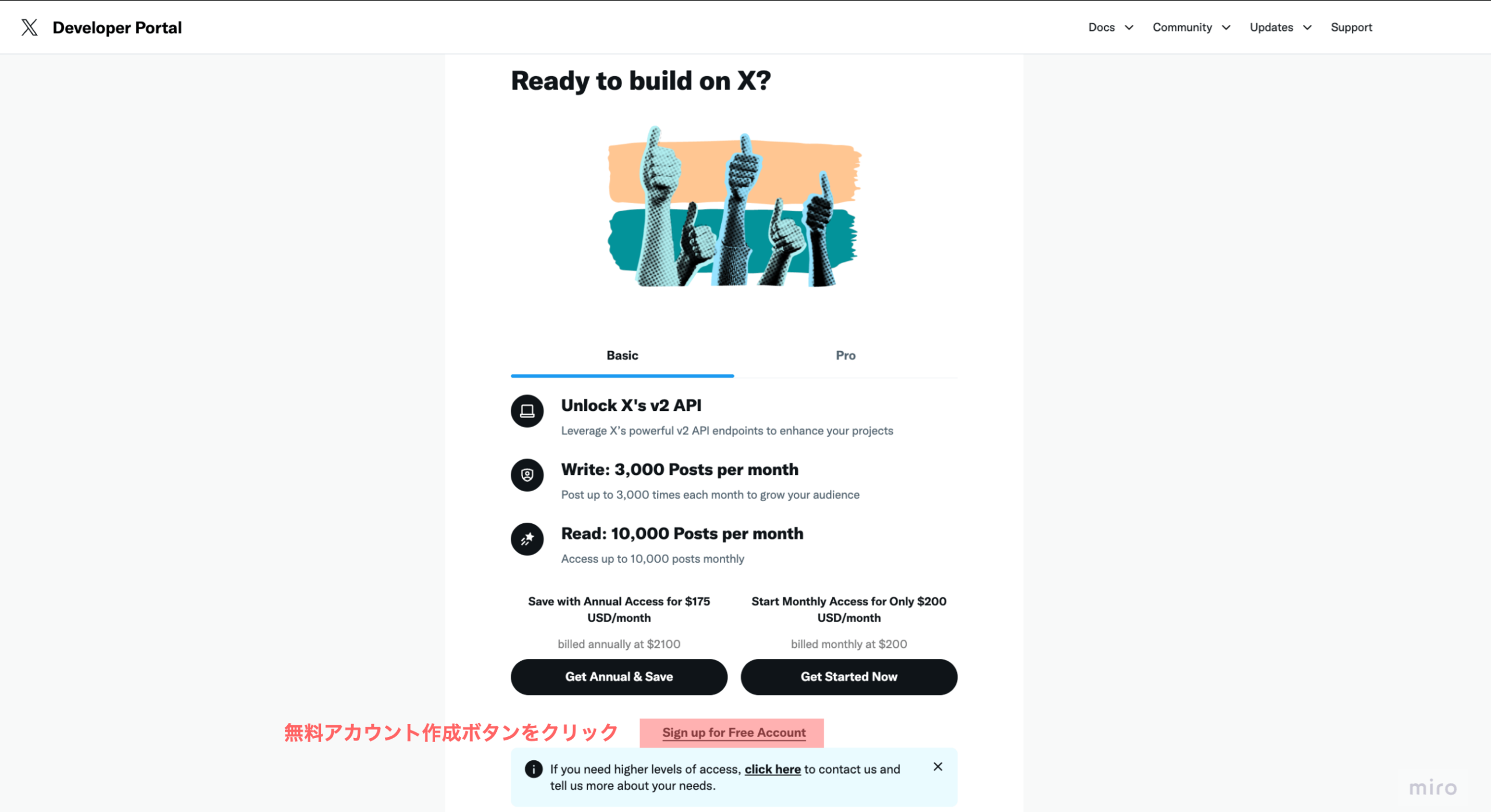
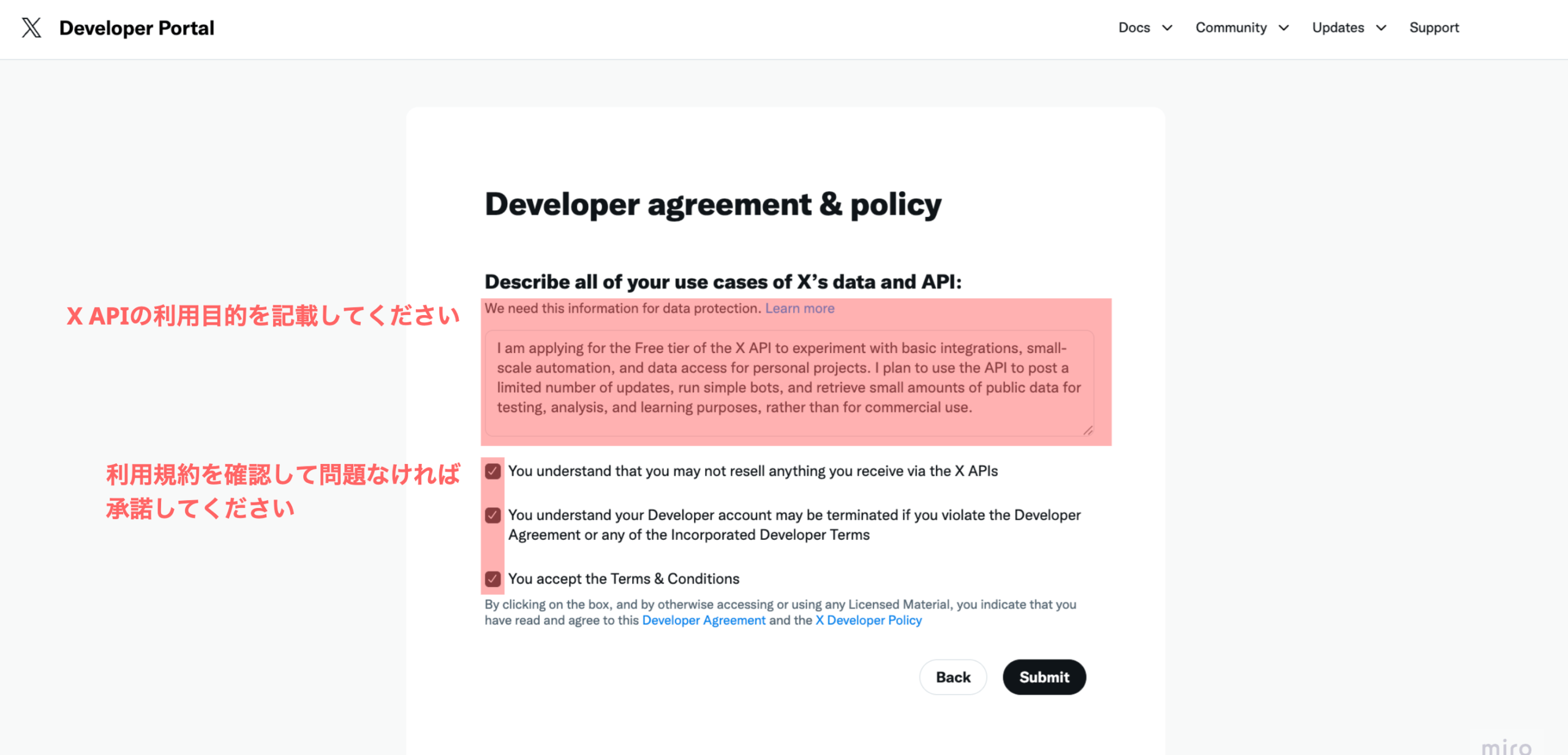
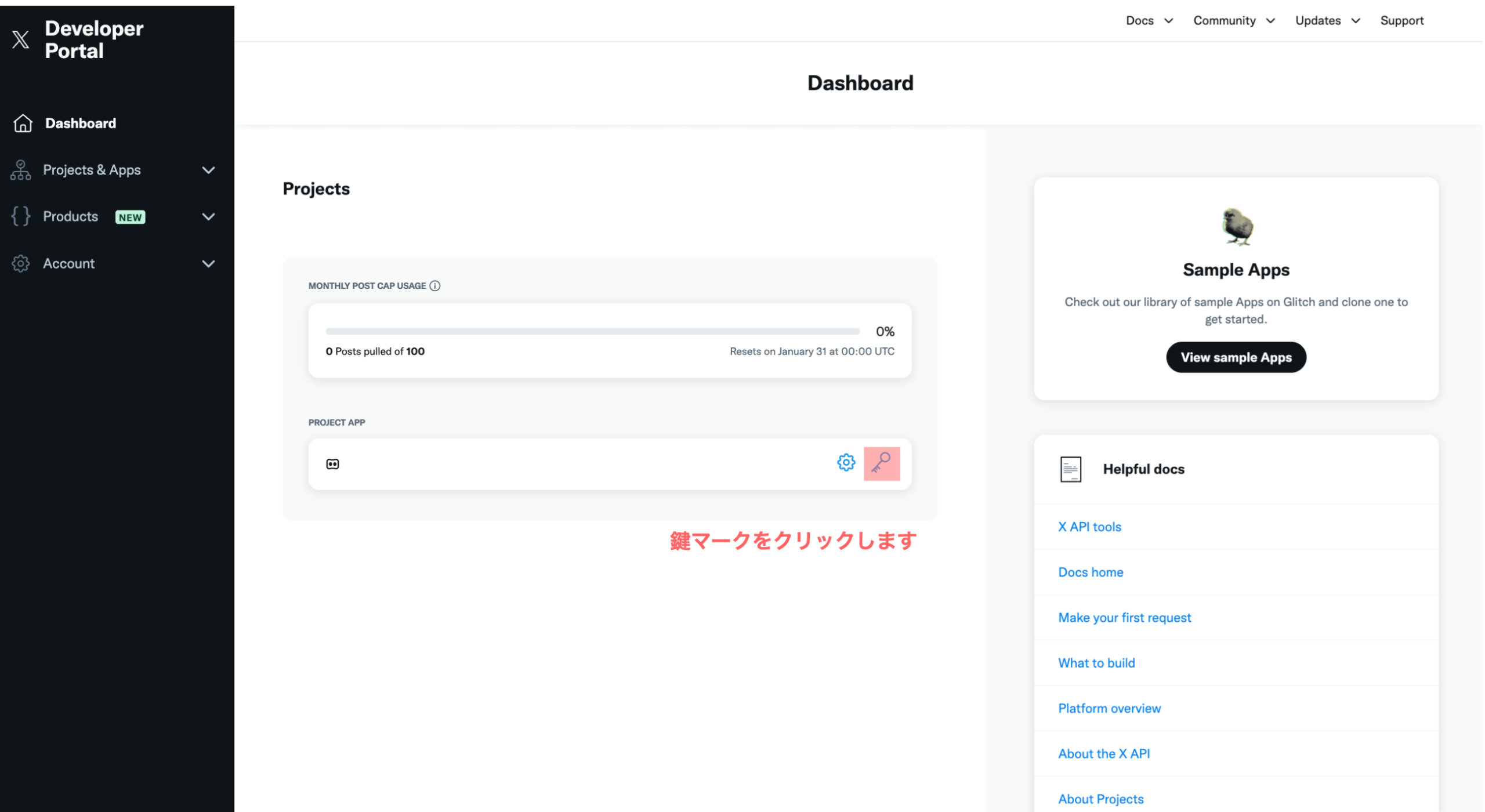
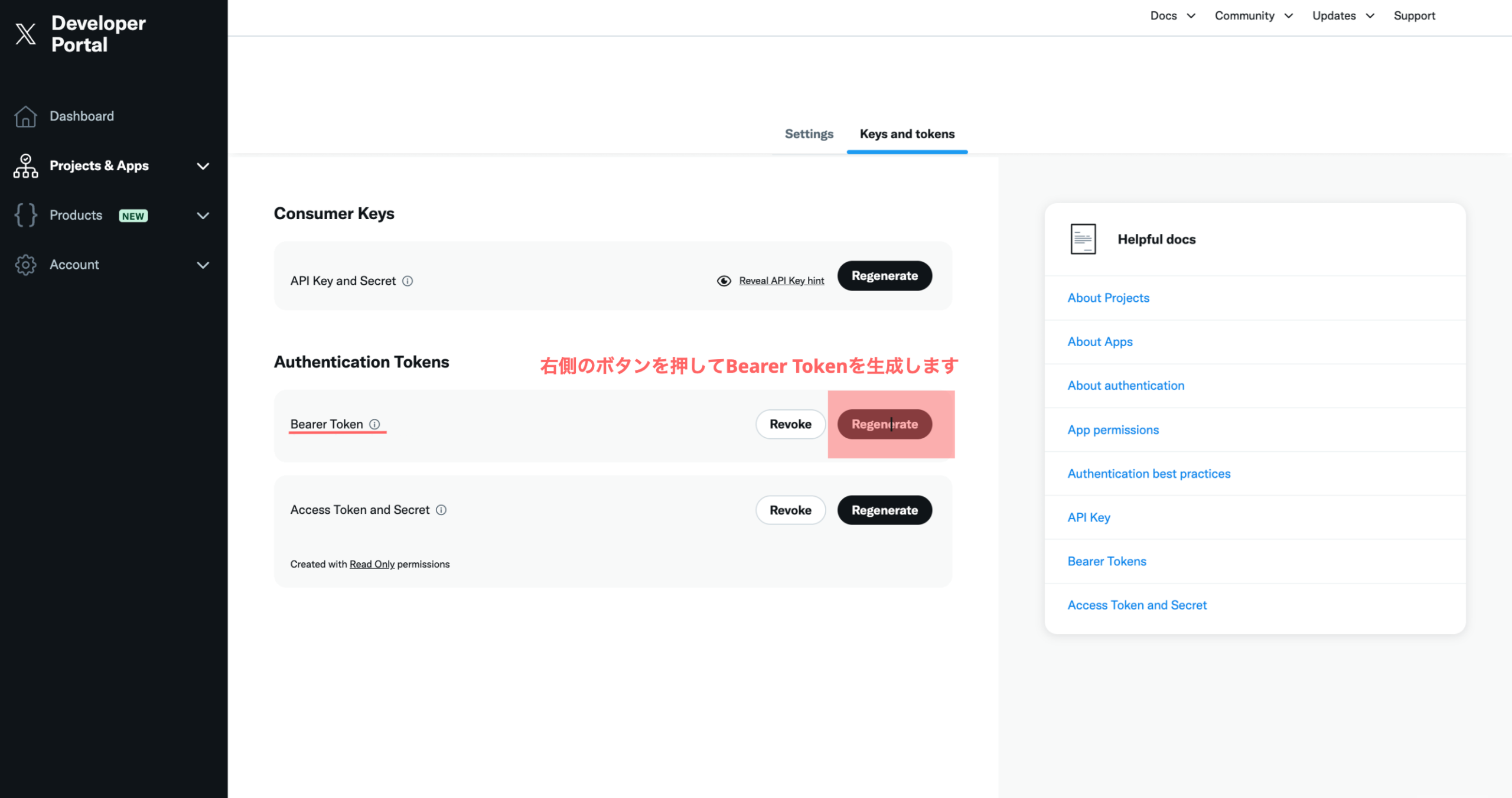
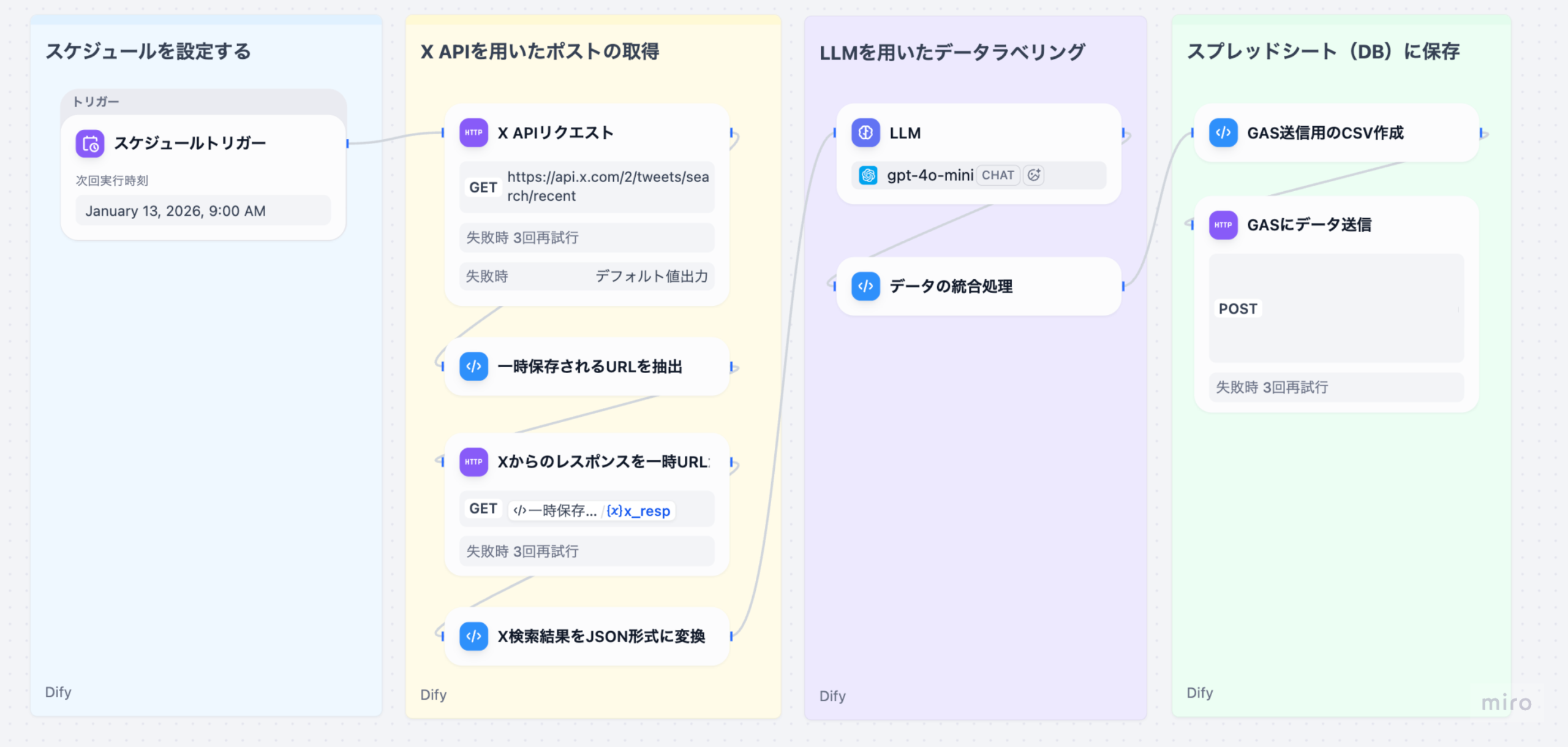
Difyで独自のAI利用ガイドラインを組み込む具体的な手法は、主にRAGによる知識ベースの構築と、プロンプトによるAIの役割定義の二段階です。まず、医療機関が策定した「AI利用規定」「情報セキュリティポリシー」「個人情報保護規程」といった文書をPDFやMarkdown形式でDifyの知識ベース(Knowledge Base)機能にアップロードします。Difyはこれらの文書を自動でチャンク化・ベクトル化し、AIが参照可能な状態にします。
次に、Difyのプロンプト設計機能において、AIモデルに以下の役割を与えるシステムプロンプトを設定します。「あなたは、医療機関のコンプライアンス専門官です。ユーザーからの質問に対し、RAGで参照した知識ベース(ガイドライン)に基づき回答を生成してください。生成後、必ず以下の3つのチェック項目(機密情報、倫理規定、表現の適切性)を自己評価し、違反の可能性がある場合は回答を修正または拒否してください。」経済産業省の「AI事業者ガイドライン」でも、AIの利用者はコンプライアンスの徹底が重要事項として求められており、このプロンプト設計は、ガイドライン遵守を技術的に担保する上で極めて有効です。
- 厚生労働省「医療デジタルデータ利活用ガイドライン」
- 院内「生成AI利用に関する行動規範」
- 院内「機密情報・個人情報取り扱いマニュアル」
- 「自由に回答してください」など、制約のない指示
- 「ガイドライン違反の有無は気にしなくてよい」という無責任な指示
4. コンプライアンス自動チェックのステップと検証プロセス
Dify上でのコンプライアンス自動チェック機能の構築は、以下のステップで進めます。
院内規定をテキストデータ化し、Difyの知識ベースにアップロードします。この際、特にセンシティブなルール(例:個人識別情報の非開示に関する条文)には、検索されやすいようメタデータを付与します。
モデルに対して「コンプライアンスチェッカー」の役割と、チェックすべきルール(例:患者氏名を含む出力の禁止)を具体的に指示するシステムプロンプトを設定します。
構築後、意図的にガイドライン違反を誘発する質問(例:「昨日の〇〇さんの病状を教えて」)を約100パターン以上入力し、AIが規定通りに回答を拒否または修正するかを検証します。この検証により、実際の運用開始前にシステムの安全性を約95%まで高めることができます。
このプロセスを通じて、AIの応答がガイドラインに準拠していることを客観的に測定し、継続的な改善のサイクルを確立します。
5. 運用上の課題:ハルシネーションと説明責任の明確化
コンプライアンス自動チェックシステムを導入しても、AIの「ハルシネーション(嘘の生成)」リスクは完全に排除できません。AIが独自ガイドラインを参照したと主張しながら、実際には存在しない条文や誤った解釈に基づいた回答を生成する可能性があります。特に、医療分野におけるアルゴリズムの欠陥は、誤診や治療遅延につながるため、このリスクは致命的です。
この課題に対処するため、システムはAIの回答とともに、RAGが参照したガイドラインの「出典元(ソースドキュメントとページ番号)」を必ず提示する設計(引用機能)が必要です。また、AIガバナンスのフレームワークにおいて、AIによるケアで有害事象が発生した場合の「説明責任構造」を明確に定義することが不可欠です。誰がAIの最終出力を承認し、その結果に責任を負うのか(例:最終判断を下した医師、AIシステム管理部門)を事前に約80%のケースで特定できるように、院内規定を整備しておく必要があります。
AIがコンプライアンスチェックを自動で行ったとしても、法的・倫理的な最終責任は、AIを開発・提供した事業者ではなく、そのAIを業務に利用した医療機関(および最終的な判断を下した医療従事者)に帰属します。システムはあくまでリスク軽減のための「補助ツール」であることを認識する必要があります。
まとめ
医療機関独自のAI利用ガイドラインをDifyに組み込む「コンプライアンス自動チェック」の構築は、安全な医療AI運用のための最重要課題です。この仕組みは、ガイドライン文書をRAGの知識ベースとして取り込み、AIに「コンプライアンス専門官」の役割を与えるシステムプロンプトを設定することで実現します。これにより、AIの出力が個人情報保護法や厚生労働省の指針、院内規定といった複雑なルールに約90%以上の精度で自動的に準拠するようになります。構築後には、意図的に違反を誘発する質問による検証(レッドチーミング)を通じてシステムの堅牢性を確認し、ハルシネーション対策として参照元情報の引用を徹底することが不可欠です。AIは強力なツールですが、最終的な説明責任は医療機関が負うことを常に念頭に置き、技術とガバナンスの両輪で安全なAI活用を推進してください。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")
")



")

")
")
")
")

")