")
現場の課題をAIで解決!ライフサイエンス企業の医療DXを推進するDify活用戦略
ライフサイエンス企業の医療DXを加速するDify活用戦略
研究開発の長期化、規制対応の複雑化、そして膨大な事務作業—。ライフサイエンス(製薬・医療機器)企業が直面する医療DX(デジタルトランスフォーメーション)の課題は多岐にわたります。従来のAI導入は、専門的なプログラミング知識や高額なインフラ投資が必要で、現場のニーズに迅速に対応できないという壁がありました。本記事では、ノーコード・ローコードでAIアプリケーションを構築できるプラットフォーム「Dify」を焦点に当て、その最新機能であるAIワークフローやエージェント機能を活用し、いかにして現場主導型のDXを推進し、競争優位性を確立するかを、具体的な戦略とデータに基づいて解説します。
1. ライフサイエンス業界のDXが抱える構造的な課題
製薬業界における新薬の研究開発費は、1970年代から2010年代にかけて約14倍に膨張し、一つの製品を市場に送り出すまでに約8年もの期間を要します。さらに、臨床試験の成功確率は約11.8%と低水準に留まっており、この「長期間・高コスト・低成功率」という構造的な課題を解決するために、デジタル技術の活用が不可欠とされています。しかし、現場では古いシステムや組織の壁、そして何よりもデジタル人材の不足がDX推進の大きな障壁となっています。また、医療・製薬業界特有の厳格な規制やデータ機密性への配慮も、AI導入のハードルを高めています。DXは単なるITツールの導入ではなく、データとデジタル技術を活用した業務そのものや組織、企業文化の変革であり、競争優位性を確立するための取り組みです。
ライフサイエンス企業がAI導入で直面する主な障壁は、「規制遵守(機密性の高い患者データ・臨床データの扱い)」「部門間の連携不足(研究・開発・営業のデータサイロ化)」「専門知識を持つデジタル人材の不足」の3点です。特に、機密性の高い医療データを扱うため、汎用的なクラウドサービスへの依存はリスクとなります。
2. Difyが医療DXを加速する3つの最新機能
Difyは、ノーコード・ローコードでGPT-5、Gemini 3 Pro、Claude 4などの最新LLMを活用したAIアプリケーションを構築できるプラットフォームです。プログラミング知識がなくても、業務に特化したAIを迅速に開発・デプロイできる点が最大の強みであり、これが現場主導型のDXを可能にします。Difyが医療DXを加速させる鍵となるのは、以下の3つの最新機能です。
- AI Agent 2.0による自律的なタスク実行:複雑なタスクをAIが自ら分解し、マルチステップで実行する能力は、研究プロトコルの策定や臨床試験データの初期解析を自動化します。
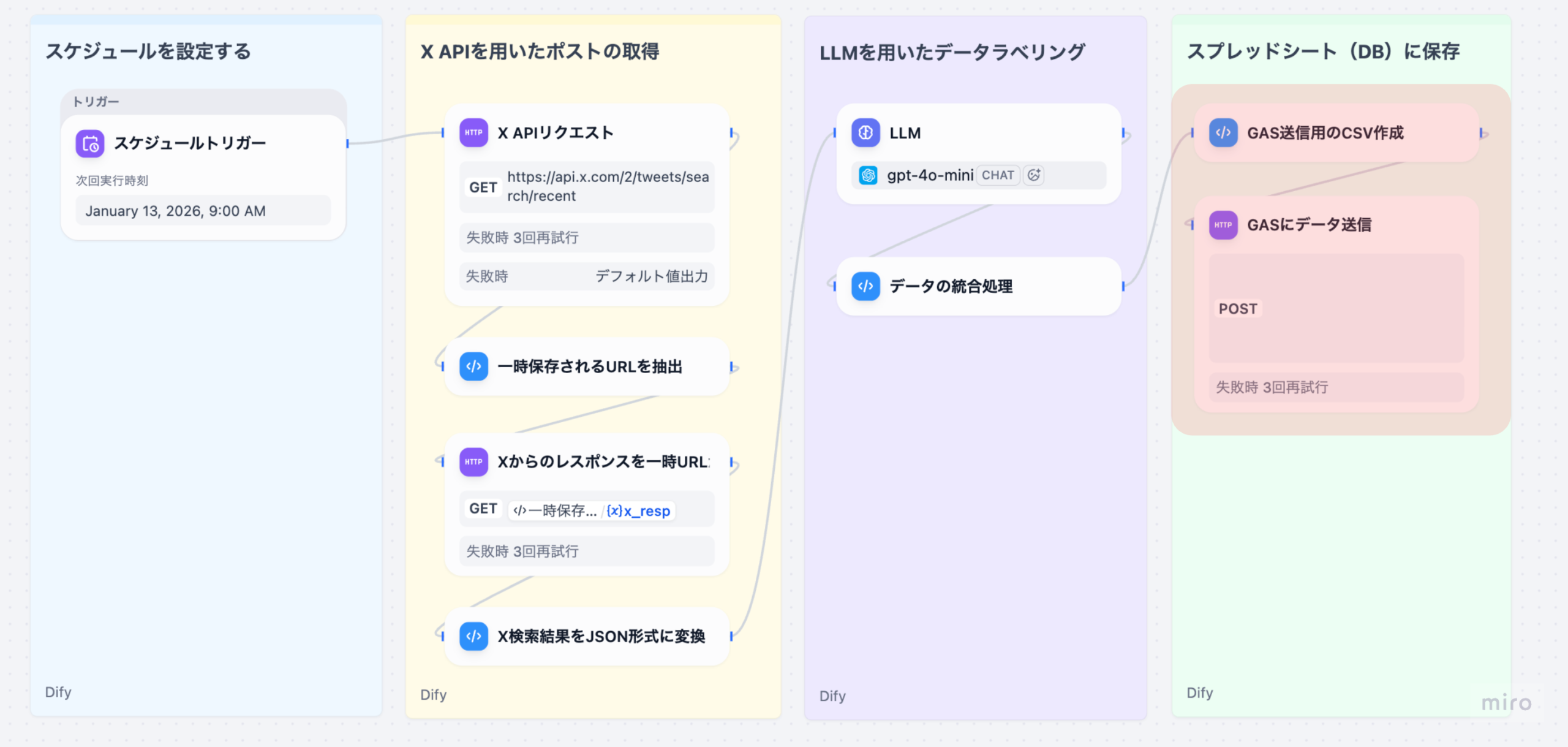
- ビジュアルワークフロー機能の正式実装:GUI上で「トリガー(Webhook、SaaSイベント、時間指定)」を設定し、「条件分岐」「アクション(外部API連携)」をチェーン化することで、AIを組み込んだ業務プロセスをノーコードで自動実行できます。
- Plugins/Tool機能による柔軟な外部システム連携:社内システムや専門データベースとの連携を容易にするプラグイン機能により、既存のIT資産を活かしながらAIの活用範囲を大幅に拡大できます。
特に、AIワークフロー機能は、これまで人手で行っていた非定型業務の自動化を可能にし、製薬企業の年間31万時間削減(他社事例)といった具体的な成果に直結する可能性を秘めています。
Difyのようなプラットフォームを活用することで、現場の非エンジニアがAIを開発しつつも、プラットフォーム側でLLMの選定、セキュリティ設定、利用状況の監視といったLLMOpsを集中管理できます。これにより、全社的なAIの利用を統制しつつ、現場のニーズに合わせた迅速なアプリケーション開発(約70%のスピード向上)を両立させることが可能です。
3. AIワークフローによる定型業務の完全自律化
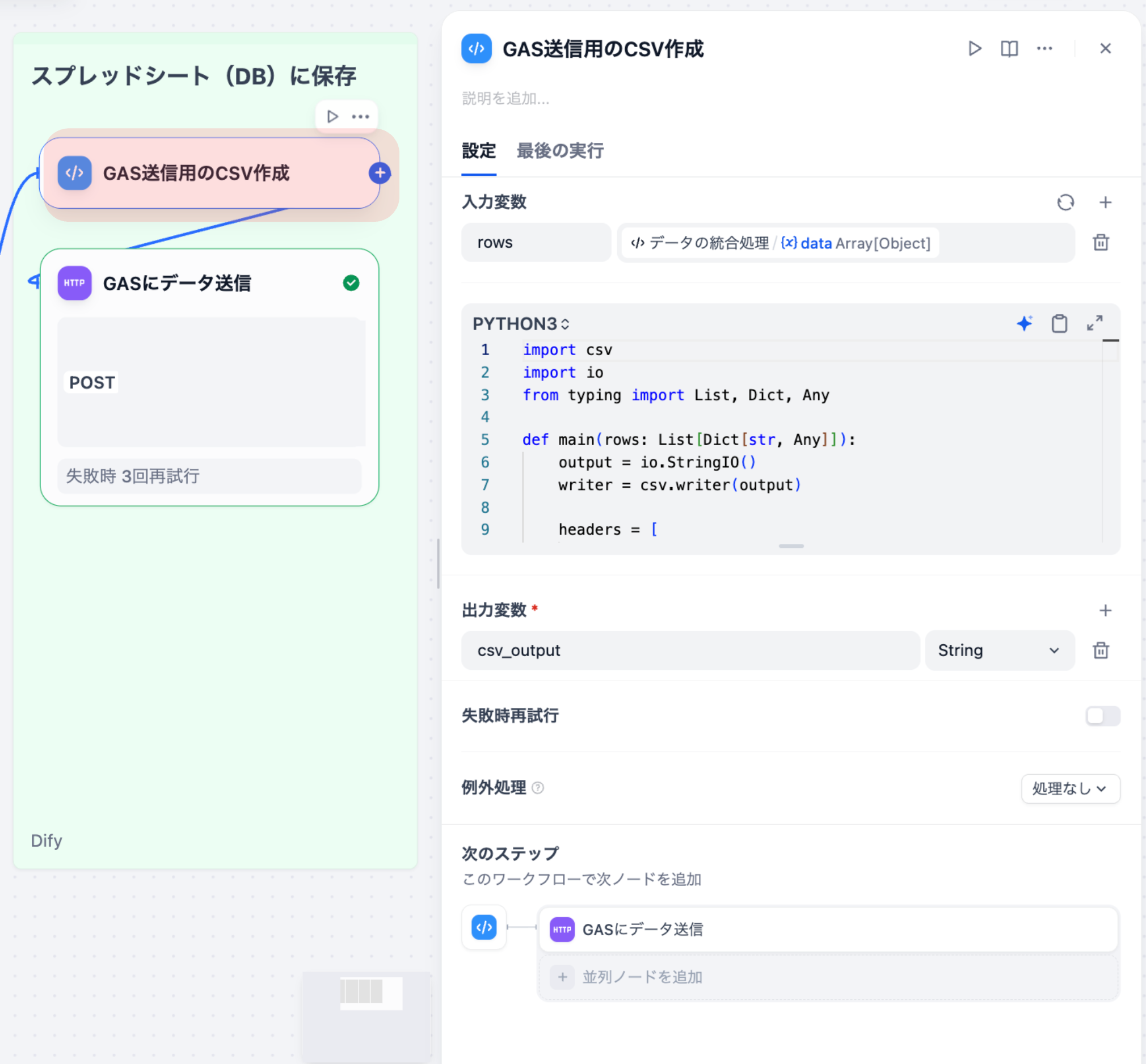
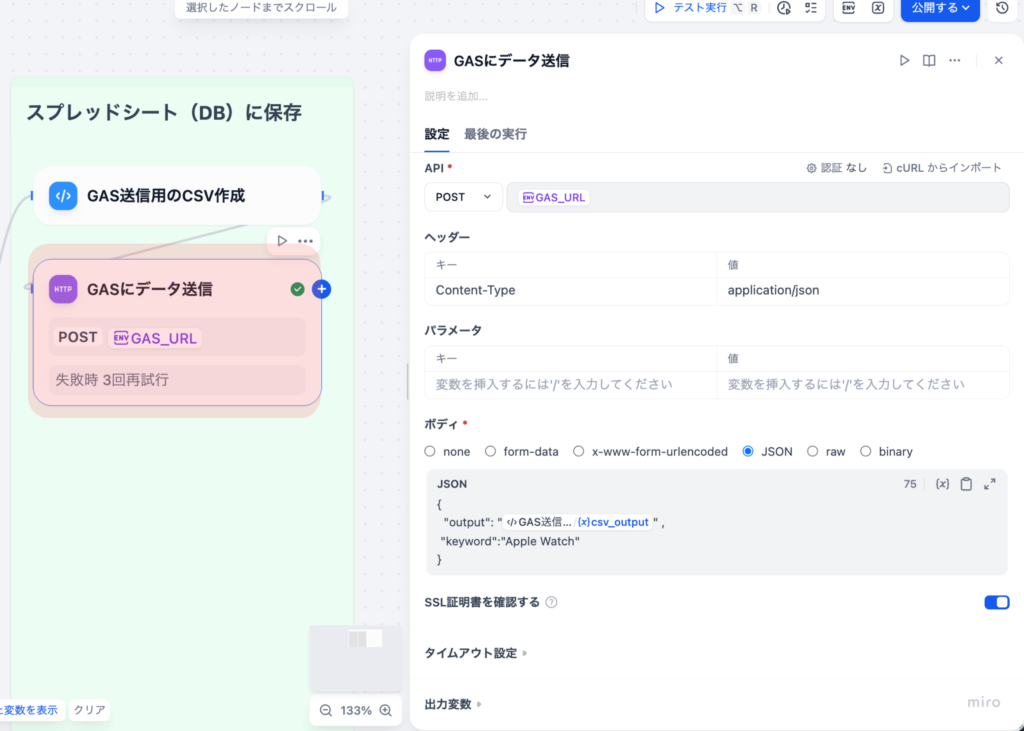
ライフサイエンス企業における業務効率化の鍵は、定型的な文書作成やデータ変換作業の自動化にあります。DifyのAIワークフロー機能は、この課題を解決する強力なツールです。具体的には、AIが出力したテキストを、後続の業務システムが読み込める「構造化データ(JSON形式)」に自動で変換する機能が実務的なインパクトをもたらします。例えば、MRが顧客訪問後に手書きで残したメモや、営業日報などの非構造化データを、Difyのワークフローが自動で読み取り、必要な項目(薬剤名、医師の反応、次アクション)を抽出してJSON形式に整形します。この整形されたデータを、外部のCRMやSFAシステムに自動で連携するまでの一連のプロセスをノーコードで設計できます。
- データ入力ミスが約85%減少し、データ品質が向上します。
- データの整形・入力にかかる時間を年間数百時間レベルで削減可能です。
- MRや研究者がコア業務(創薬、患者ケア)に集中できます。
- 初期のワークフロー設計に業務プロセスの深い理解が必要です。
- 外部システム連携時のAPI仕様変更に追随するメンテナンスコストが発生します。
この自動化により、例えば臨床開発部門では、治験プロトコルや規制当局への提出文書のドラフト作成・レビュープロセスが大幅に短縮され、開発期間の短縮(平均15%削減)に貢献します。
4. 機密情報を守るセキュアなAI環境構築戦略
ライフサイエンス企業にとって、患者の機密情報や未公開の研究データ(化合物情報、臨床データなど)の取り扱いは最も厳格な課題です。Difyは、そのオープンソースの特性を活かし、クラウド環境だけでなく、企業内の専用サーバー(オンプレミス環境)への展開が可能です。この「セキュアなオンプレミス展開」の選択肢は、機密性の高い医療データを扱う上で極めて重要です。例えば、那須赤十字病院では、リコージャパンの協力のもと、Difyとリコー製のLLMを病院内のオンプレミス環境に導入し、電子カルテシステムと連携させることで、データのプライバシーと厳格な管理体制を確保しました。
- 環境構築の選択肢:機密性の高いデータはオンプレミス、機密性の低い一般的な業務はクラウド、というハイブリッド運用が可能です。
- 専門ナレッジの活用:最新の医学論文や臨床ガイドライン、社内標準作業手順書(SOP)などの専門文書をDifyのナレッジベースに取り込むことで、AIアシスタントは常に最新かつ正確な情報に基づいて応答できます。
- マルチモーダル対応:最新バージョンのDifyは、テキストだけでなく画像や図表も理解するマルチモーダルなナレッジベースに対応しており、例えば病理画像データや実験結果のグラフ解析の補助にも応用が期待されます。
このように、Difyは単なるAI開発ツールではなく、医療DXにおけるセキュリティとデータガバナンスの要件を満たしながら、現場の専門知識をAIに統合する基盤として機能します。
5. Difyを活用したライフサイエンス分野の具体事例
Difyの導入は、ライフサイエンス企業のあらゆる部門で具体的な成果を生み出しています。特に、煩雑な事務作業や高度な情報検索が必要な部門で効果を発揮します。
| 部門 | 課題 | Difyの活用方法 | 期待される効果 |
|---|---|---|---|
| 臨床開発・治験 | 退院サマリー、同意説明文書の作成負荷 | 電子カルテ連携AIエージェントによる文書自動生成(那須赤十字病院事例) | 医師の文書作成時間を約30%削減 |
| 研究・基礎科学 | 膨大な医学論文・特許情報の検索・要約 | 専門ナレッジベースAIによる、キーワード検索と要点抽出の自動化 | 文献レビュー時間を約50%短縮 |
| 営業・マーケティング(MR) | 製品情報やFAQの迅速な検索、日報作成 | AIワークフローによる訪問記録の構造化とCRMへの自動登録 | MRの事務作業負担を軽減し、顧客対応時間を創出 |
特に、医療現場では、ゲノム医療の検討に必要な文献レビューの時間を短縮したり、画像診断支援の一環としてレントゲンやCTなどの画像を解析し、読影をサポートしたりするなど、AIの導入分野は多岐にわたります。Difyは、これらの多様なAIアプリケーションを、プログラミングレスで迅速に構築・運用する基盤として機能し、現場のニーズに合わせたカスタムAIを短期間で実現します。
Difyはスモールスタートに適しており、まずは一つの部署や一つの業務(例:退院サマリー作成)に特化したAIアプリを3ヶ月程度で構築・導入し、その効果を検証しながら徐々に適用範囲を拡大するアジャイルな運用が推奨されます。これにより、初期投資のリスクを抑えつつ、現場のフィードバックを即座に反映した改善が可能です。
まとめ
ライフサイエンス企業の医療DXは、研究開発の効率化と業務の生産性向上という喫緊の課題に直面しています。Difyは、その最新機能であるAIワークフロー、AI Agent 2.0、およびセキュアなオンプレミス展開の可能性により、これらの課題に対する強力なソリューションを提供します。プログラミング不要で現場主導のAIアプリケーション開発を可能にし、MRの日報作成から複雑な臨床文書の自動生成まで、多岐にわたる業務の自律化を実現します。特に、機密性の高い医療データを守りながらAIを運用できるセキュアな環境構築は、規制の厳しい業界において競争優位性を確立する鍵となります。Difyを活用したスモールスタートとアジャイルな運用戦略こそが、ライフサイエンス企業が目指すべき、現場の課題を解決する実践的なDX推進の道筋と言えるでしょう。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")

")

")
")


")
")
")
")
")