")
【Text-to-SQLの衝撃】DifyでSQL不要の患者数抽出は可能か?
Text-to-SQLの衝撃:DifyでSQL不要の患者数抽出は可能か?
医療・製薬業界のマーケターにとって、データベース(DB)から必要な患者数や疾患動向のデータを抽出する作業は、常にSQLの知識という高い壁に阻まれてきました。必要な情報が目の前にあるにもかかわらず、IT部門やデータエンジニアに依頼しなければアクセスできないというボトルネックは、迅速な意思決定を妨げる大きな要因となっています。しかし、大規模言語モデル(LLM)の進化により、「Text-to-SQL」という、自然言語の質問をSQLクエリに自動変換する技術が実用化されつつあります。本記事では、このText-to-SQLの仕組みと、DifyのようなLLMオーケストレーションプラットフォームを活用することで、SQL知識ゼロのマーケターが医療データを自由に活用できるのかどうかを、技術的な観点から徹底的に解説します。この革新的な技術が、どのようにデータ活用の民主化を推進し、医療マーケティングの未来を変えるのか、その可能性と限界を探ります。
1. 結論:Text-to-SQLは「条件付きで可能」なデータ民主化の鍵
SQLを知らないマーケターがText-to-SQL技術を使ってDBから患者数を抽出することは、現在の技術レベルにおいて「条件付きで可能」であると結論付けられます。Text-to-SQLは、自然言語処理(NLP)とLLMの能力を組み合わせることで、従来のデータベース操作の障壁を劇的に低くしました。これにより、非技術者でも「過去3ヶ月間にA疾患で新規に受診した患者数を教えて」といった口語的な質問を直接データベースに投げかけられるようになります。しかし、医療データ特有の複雑性がこの「条件」を構成します。
具体的には、患者コホートの定義には疾患コード(ICD-10など)や時系列のイベント(初診日、投薬期間など)の正確な理解が不可欠です。この複雑なドメイン知識をLLMに正しく理解させるためには、Difyのようなプラットフォームを用いて、データベースのスキーマ情報だけでなく、ビジネスルールや専門用語を事前にプロンプトやセマンティックレイヤーとして組み込む高度な準備(オーケストレーション)が必要です。この準備が整えば、データ活用の民主化は大きく前進し、データ抽出にかかる時間は従来の約80%削減される可能性を秘めています。
Text-to-SQLの成功は、単なるLLMの性能ではなく、「ドメイン知識」「データベーススキーマ」「ビジネスルール」の3要素をいかに正確にプロンプトとしてLLMに提供できるか、というオーケストレーション能力に依存します。
2. Text-to-SQLの基本メカニズムとデータ民主化の衝撃
Text-to-SQLは、ユーザーが入力した自然言語のクエリ(例: 「東京支社の今月の売上トップ10の顧客リスト」)を、データベースが解釈できる正確なSQL文に変換する技術です。この技術の核となるのは、LLMの持つ高度な自然言語理解とコード生成能力です。Text-to-SQLは、単なるテキスト生成ではなく、自然言語処理(NLP)、データベース(DB)、知識表現(KR)といった複数分野の技術を融合した、特に多層的な理解と論理的整合性が求められる領域であると言えます。
この技術が注目される背景には「データ活用の民主化」があります。従来、データベースへの問い合わせにはSQLの知識が必須であり、非エンジニアのビジネスユーザーにとって大きな障壁でした。Text-to-SQLはこの壁を取り払い、誰もが自然言語でデータの取得・集計・比較・分析を行えるようにします。データ分析の民主化が促進されることで、組織全体のデータ活用率が向上し、意思決定の迅速化に貢献します。近年では、高性能LLMの登場により、ゼロショットやフューショットのプロンプトによって、従来のルールベース手法よりもはるかに柔軟で汎用的なSQL生成が可能になっています。
- SQL知識の障壁撤廃: 非技術者でもデータベースに直接アクセス可能になる。
- 分析の迅速化: データエンジニアへの依頼待ち時間が解消され、分析サイクルが短縮される。
- 業務効率化: データ探索に費やされていた時間が削減され、約70%の業務効率向上が期待される。
- 専門知識の活用: 複雑なデータ構造を理解するための専門知識が不要になる。
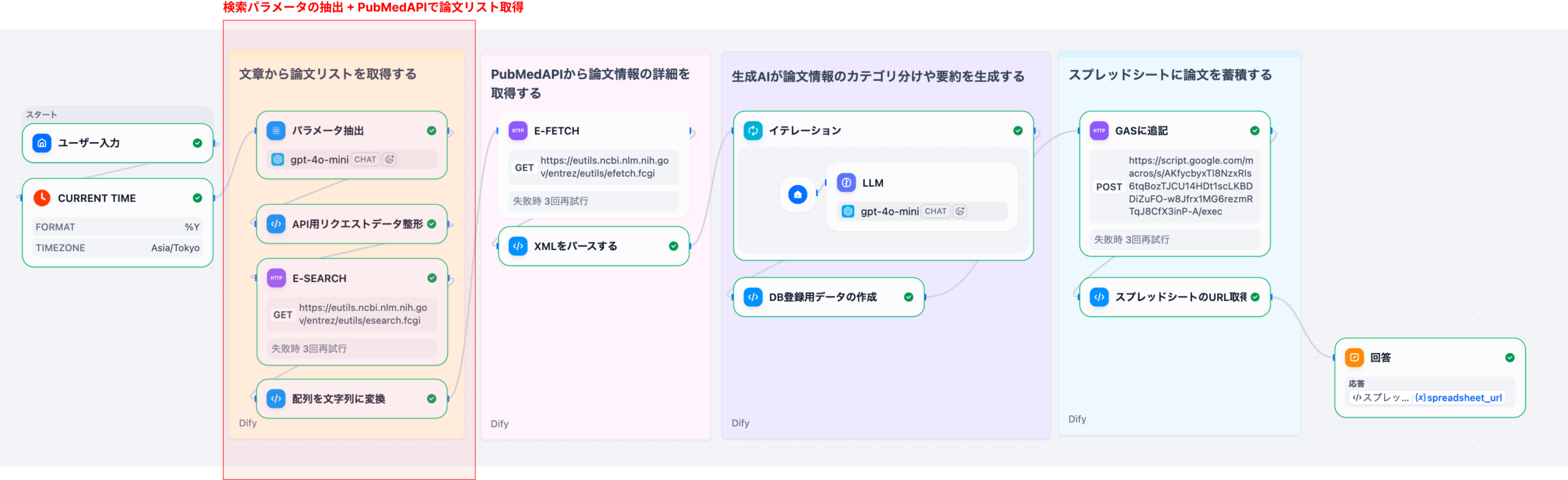
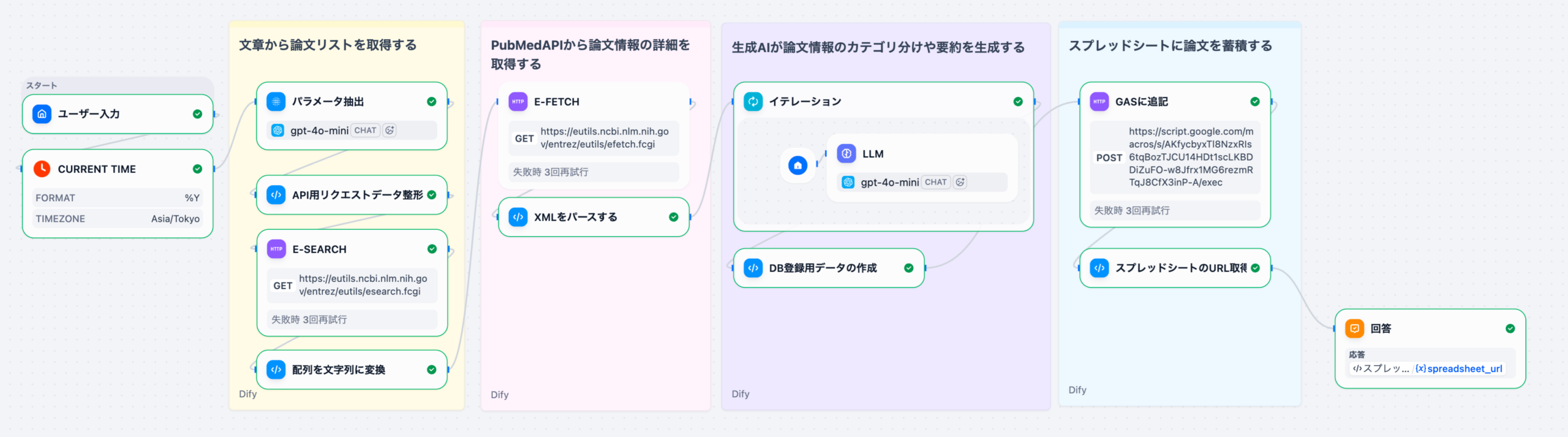
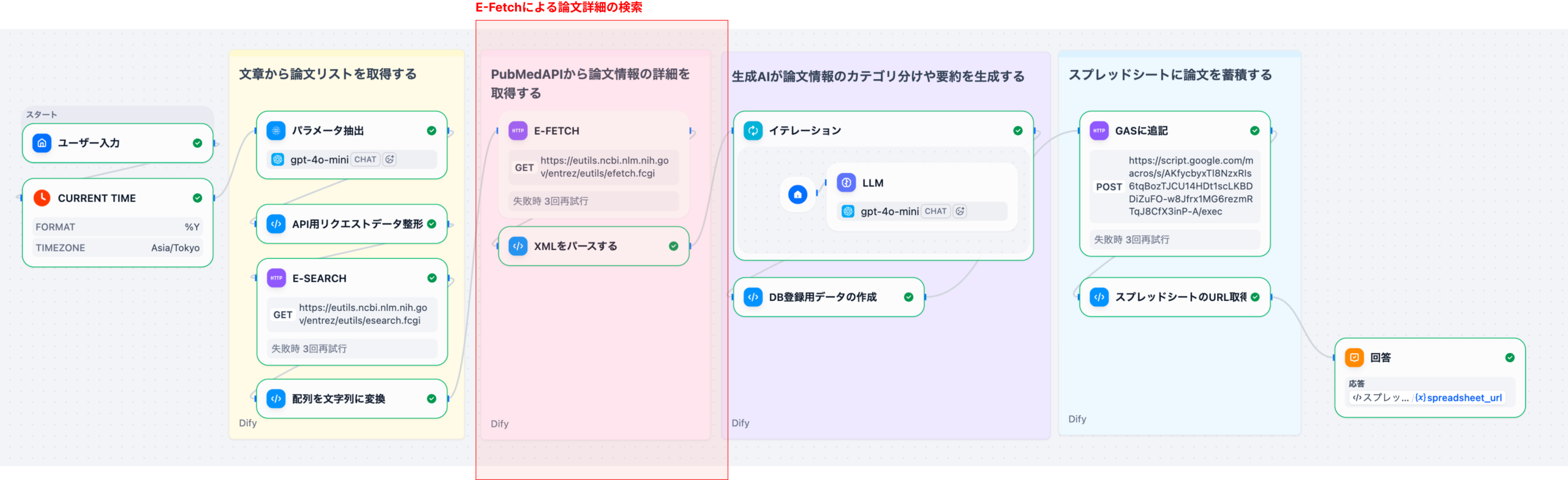
3. Difyを活用したText-to-SQLワークフローの構築手順
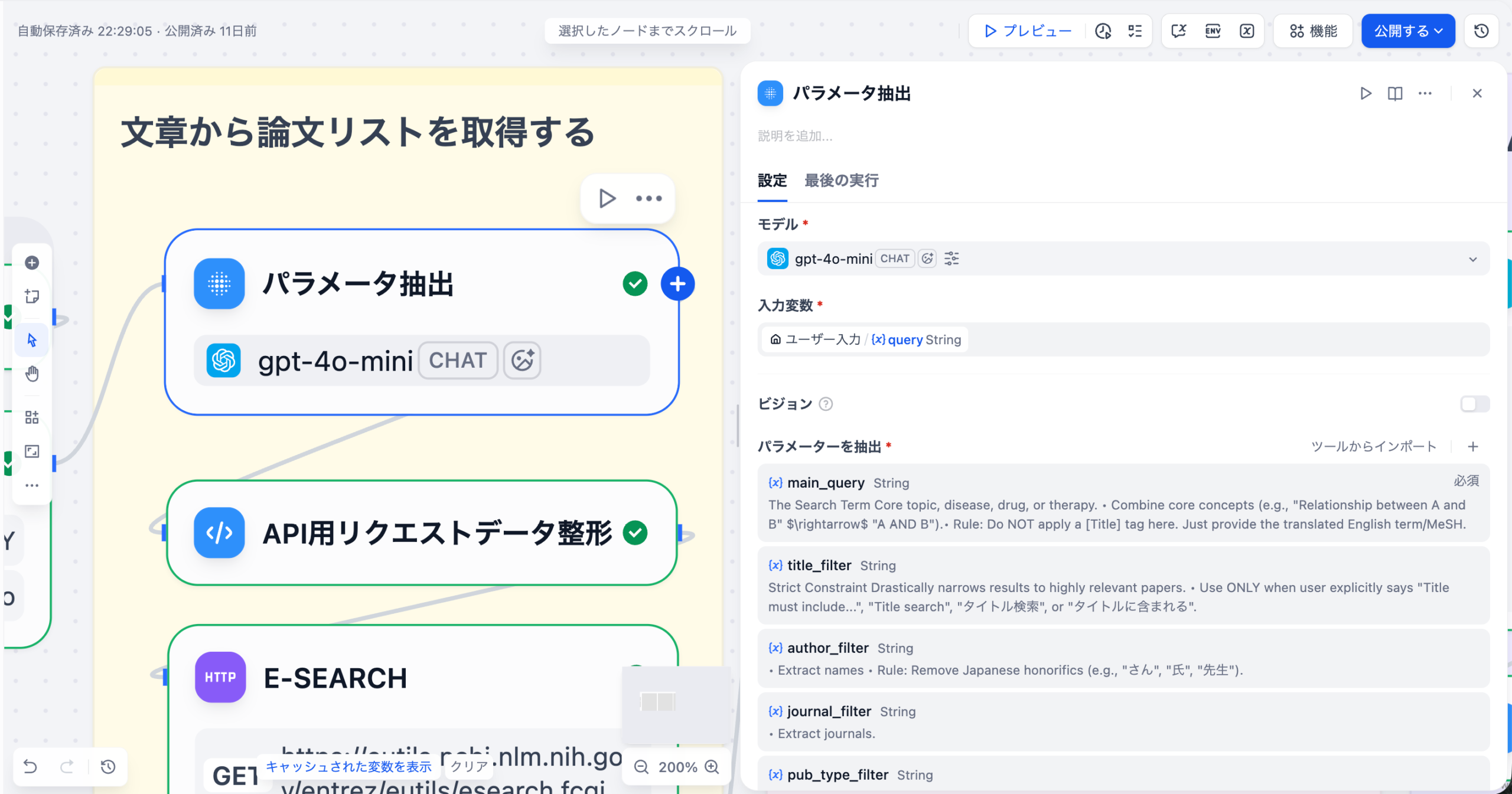
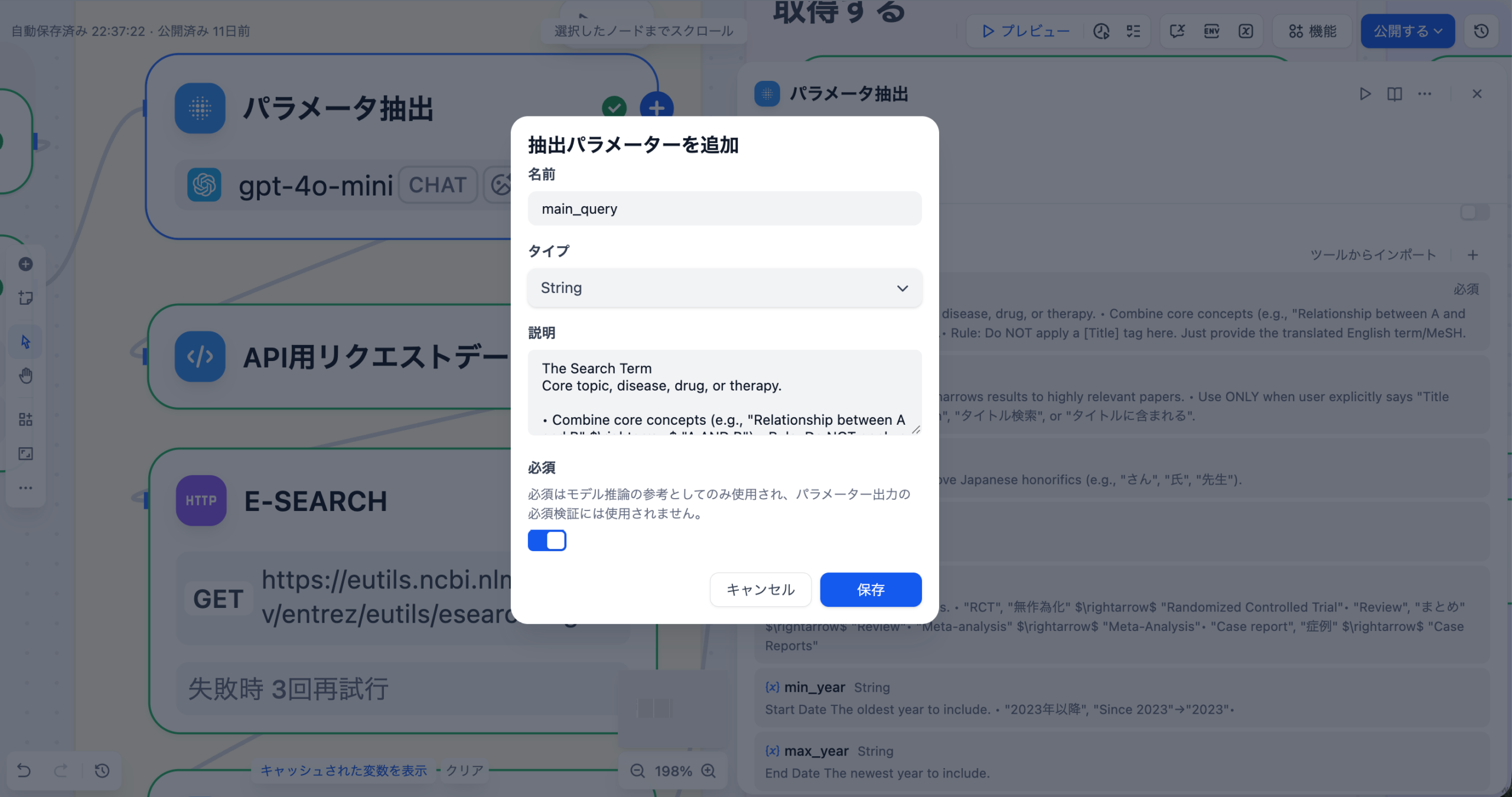
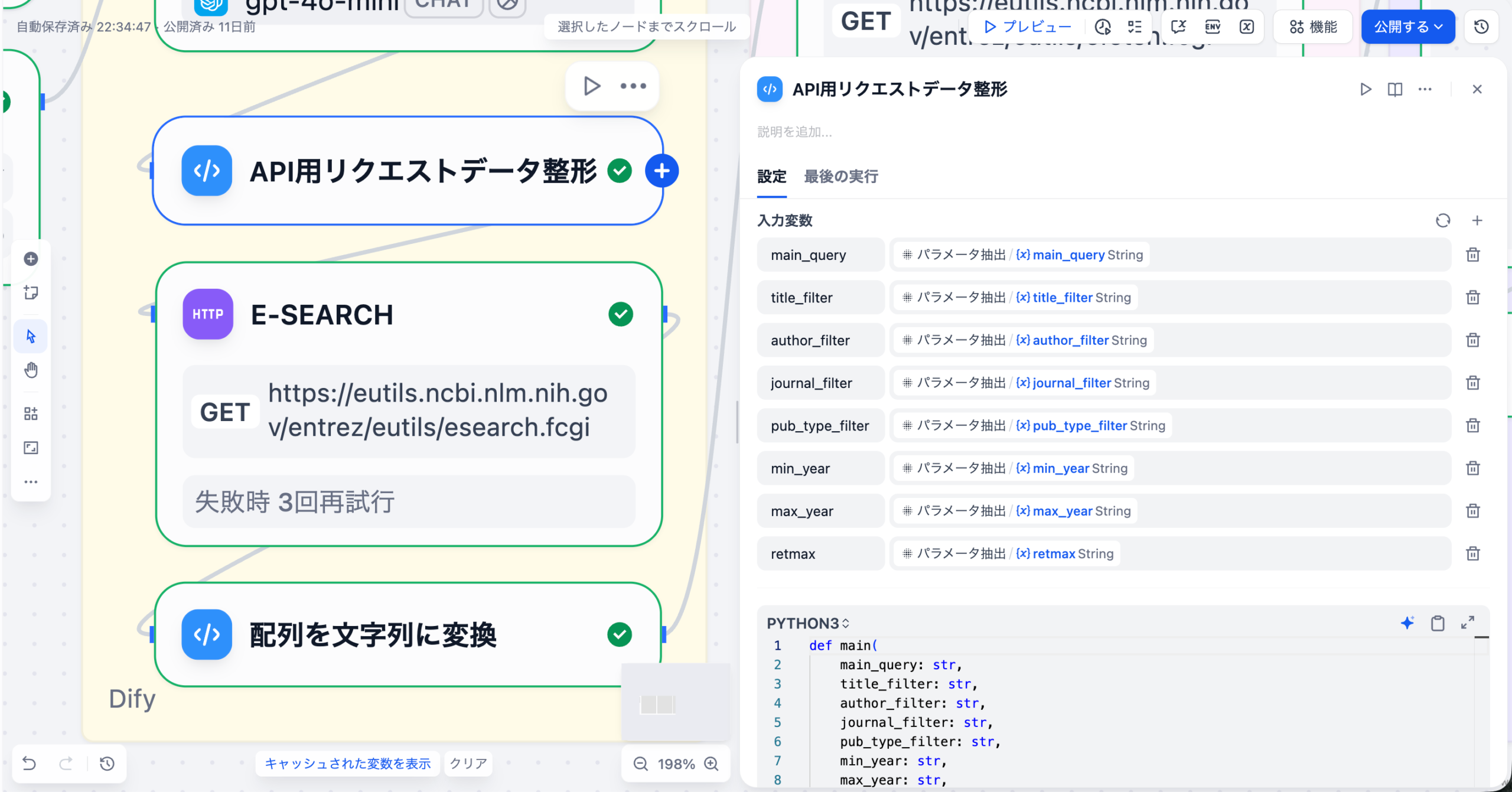
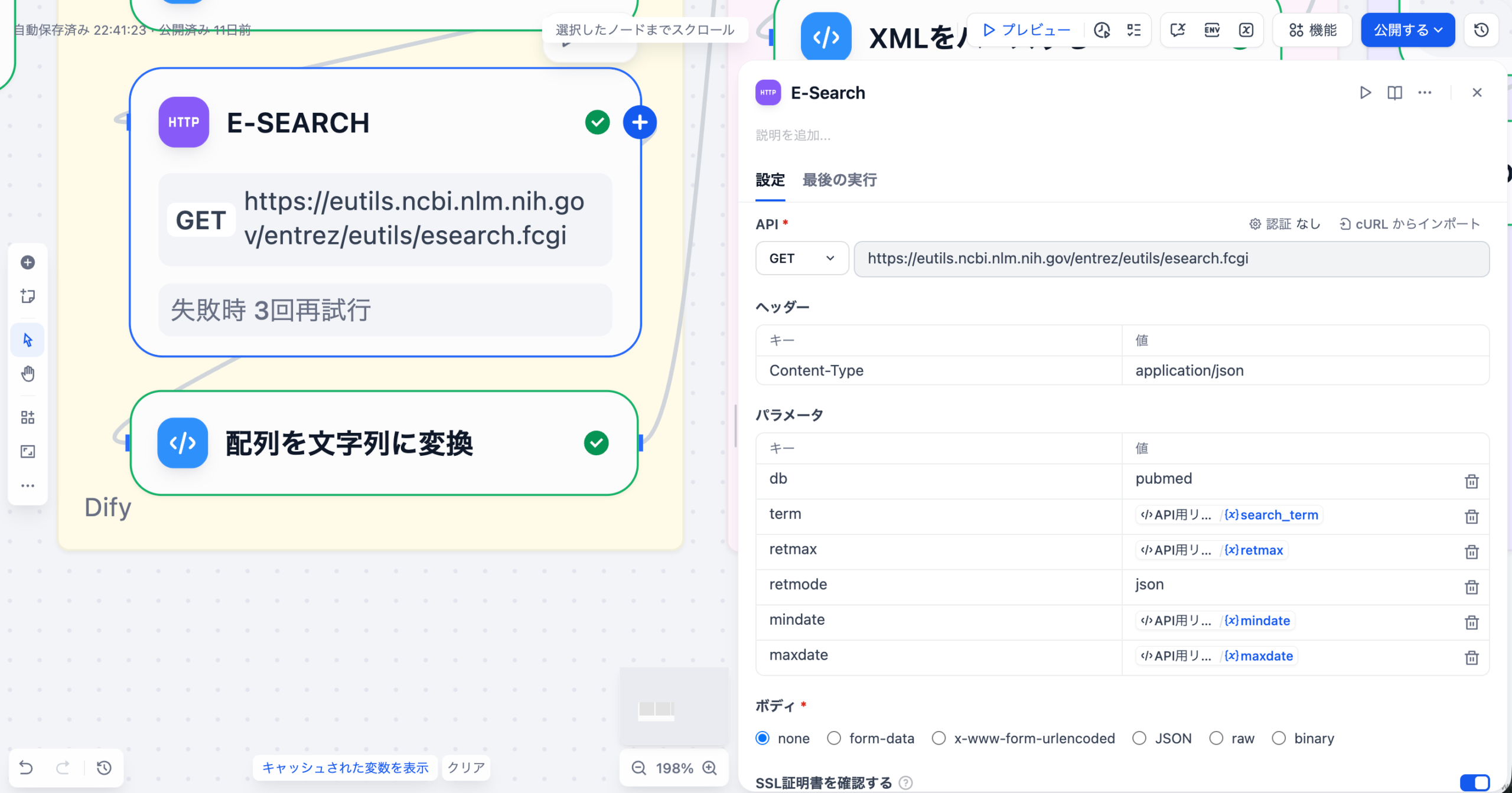
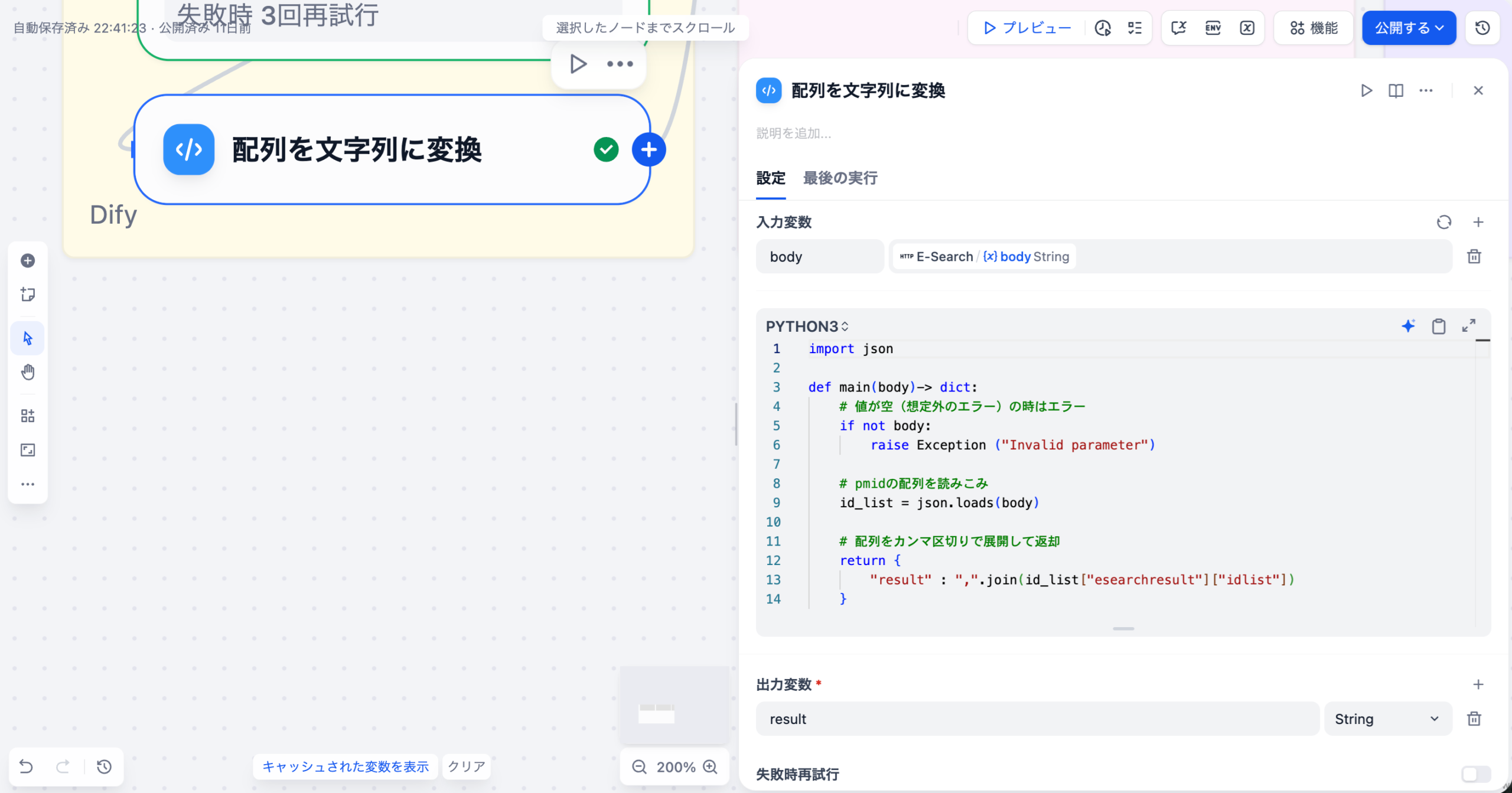
DifyのDatabaseツールを介して、対象となる患者データベースに接続します。LLMノードの前に「Get Table Schema」アクションを配置し、質問に関連するテーブルの定義情報(カラム名、データ型など)を動的に取得します。
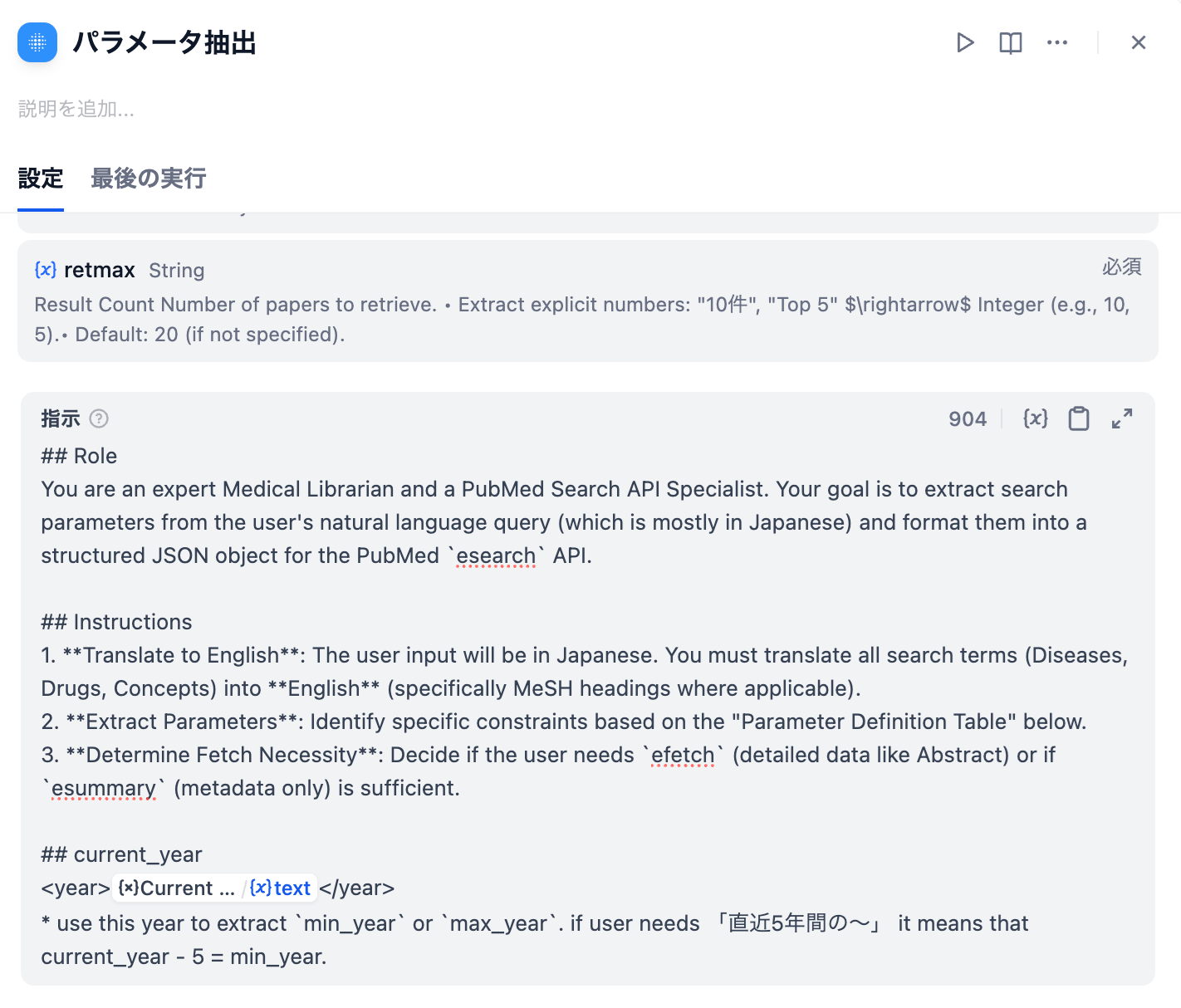
LLMノードに、ユーザーの自然言語クエリとステップ1で取得したスキーマ情報を入力します。SYSTEMプロンプトとして「あなたは医療データに特化したSQL専門家です」といった役割と、正確なSQLを生成するための厳密な要件を定義します。
生成されたSQLをDatabaseツールに戻して実行します。結果として得られた生データを、Codeノードや別のLLMノードで整形(例: JSONからテーブル表示への変換)し、マーケターが理解しやすい形でチャットインターフェースに出力します。
このアプローチにより、マーケターは複雑なSQL構文を意識することなく、チャットボットに話しかけるだけで、必要な患者データを取得できるようになります。Difyの柔軟なワークフロー設計は、複雑なデータ分析プロセスを非技術者向けに抽象化する上で非常に強力なツールとなります。
4. 医療データ特有の課題とRAG/セマンティックレイヤーによる解決策
医療データ(特に電子カルテやレセプトデータ)の活用において、Text-to-SQLの精度を確保するには、通常のビジネスデータよりも高度な対応が必要です。主な課題は、ドメイン知識の不足と複雑なクエリ構造です。例えば、「心血管疾患」という自然言語の質問は、データベース上では複数の疾患コード(例: I20〜I25)として表現されていることがあります。LLMがこれらのドメイン固有の用語とデータ構造の対応関係を正確に把握できなければ、誤ったSQLが生成され、結果として患者数が不正確になるリスクがあります。
この課題を克服する鍵となるのが、RAG(検索拡張生成)とセマンティックレイヤーの導入です。RAGを活用したText-to-SQL 2.0では、ユーザーの質問に対し、過去の類似質問とそれに対応する正確なSQLクエリのペアを検索し、それをLLMへのプロンプトとして追加します(Few-shot学習)。これにより、LLMは特定のドメインや状況に適応し、クエリの文脈を深く理解できるようになります。また、セマンティックレイヤー(ビジネスドメインの質問や指示文を高精度なSQLクエリに変換するためのメタデータ定義層)を事前に定義することで、ビジネスユーザーの質問を信頼性の高い回答に変換することが可能になります。
RAGとセマンティックレイヤーを組み合わせることで、ドメイン特化の問い合わせに対する精度低下の問題を克服し、正確なデータ抽出を実現します。これにより、複雑な医療データでも、約90%以上の精度で正確なSQLを生成することが技術的に可能になります。
医療分野の検証事例では、RAGなどのプロンプト改善により、特定のコホート定義に対して「期待通りの結果(例:66人の患者数)」を正確に返すことに成功しています。この精度向上のためには、単なるSQL生成に留まらず、ドメイン知識を組み込むための高度な事前準備が不可欠です。
5. マーケターが知っておくべきText-to-SQLの倫理的・技術的限界
Text-to-SQLは強力なツールですが、SQL知識のないマーケターが利用する際には、その限界とリスクを理解しておくことが不可欠です。最も重大な限界は、LLMが生成するSQLの「非決定性」と「予測不可能性」です。高品質なLLMを使用しても、生成されたSQLが常に正確である保証はなく、特に複雑な結合や集計を含むクエリでは、ユーザーの意図と異なる結果を返す可能性があります。また、LLMはデフォルトの状態で、クリエイティブな文章作成には優れますが、厳密な仕様(例: データベース特有の関数や構文)に従うことが苦手な場合があり、誤ったSQLが生成されるリスクが残ります。
このリスクを軽減するため、Google CloudなどのText-to-SQLソリューションでは、LLM-as-a-Judgeという手法を用いて生成されたSQLの品質を評価したり、セルフレビュー機能を持たせて間違ったSQLを自動で修正させたりする取り組みが進められています。マーケターは、システムが返す結果を鵜呑みにせず、常にその背景にあるデータ構造やビジネスロジックと照らし合わせる「データリテラシー」が求められます。
- 非決定性リスク: LLMの性質上、同じ質問でも異なるSQLが生成される可能性がある。
- セキュリティとガバナンス: ユーザーが意図しない機密情報へのアクセスや、無駄な全件検索クエリの生成を防ぐための制御が必要。
- 解釈可能性の欠如: なぜそのSQLが生成されたのか(WHERE条件の根拠など)が不明瞭な場合があり、信頼性の担保が難しい。
医療データ活用においては、誤ったSQLが生成されると、患者数の過少・過大評価につながり、市場戦略の失敗だけでなく、倫理的な問題を引き起こす可能性があります。そのため、Text-to-SQLの導入初期段階では、必ずデータエンジニアや専門家による「SQL実行前の生成クエリレビュー」と「結果データの検証」のプロセスを組み込むべきです。
6. Text-to-SQLがもたらす医療マーケティングの未来
Text-to-SQL技術は、医療マーケティングのあり方を根本から変える可能性を秘めています。データ活用の障壁が取り払われることで、マーケターはデータエンジニアのボトルネックに依存することなく、リアルタイムで市場の動向や患者のインサイトを直接把握できるようになります。これにより、施策の立案から実行、効果測定までのPDCAサイクルが大幅に加速されます。
例えば、特定のプロモーションを実施した際、「施策実施期間中にウェブサイト経由で来院した新規患者の属性と、過去の治療歴の関連性」といった、従来のSQLでは複雑すぎてすぐに実行できなかった質問も、自然言語で瞬時に実行可能になります。これは、年間で約15%のデータ探索時間の削減と、それに伴う施策実行数の増加に直結するでしょう。Text-to-SQLは、単にデータを抽出するツールではなく、マーケターの「データ駆動型意思決定」を可能にするための戦略的な基盤です。この技術の導入は、医療機関や製薬企業が競争優位性を確立するための必須戦略となりつつあります。今後、Difyのようなプラットフォームの進化により、事前学習された医療ドメイン特化モデルの組み込みが容易になれば、さらに高い精度と信頼性でText-to-SQLが実用化されるでしょう。
- インサイトの瞬時把握: 複雑なコホート分析や市場分析が数秒で完了する。
- プロモーション効果のリアルタイム測定: 施策と患者行動の関連性を即座に検証可能。
- データリテラシー向上: マーケターがデータ構造を意識せず、よりビジネスロジックに集中できる環境が実現する。
まとめ
Text-to-SQL技術は、DifyのようなLLMオーケストレーションプラットフォームと組み合わせることで、SQLの知識がない医療マーケターでもデータベースから患者数を抽出することを「条件付きで可能」にします。この技術は、自然言語の質問をLLMが正確なSQLに変換することで、データ活用の民主化を劇的に促進します。しかし、医療データ特有の複雑性(疾患コード、コホート定義)に対応するためには、RAG(検索拡張生成)やセマンティックレイヤーによるドメイン知識の事前定義が不可欠です。特に、Difyのワークフロー内で、データベースのスキーマ情報と、過去の正確なクエリ例をLLMにフューショットとして提供する高度なプロンプト設計が成功の鍵となります。導入の際は、生成されたSQLの正確性を担保するため、初期段階でのエンジニアによるレビュー体制を構築し、倫理的なリスク管理を徹底することが重要です。Text-to-SQLは、医療マーケティングの意思決定を迅速化し、データ駆動型戦略を加速させる強力な基盤となるでしょう。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")
")

")



")
")
")
")
")