")
膨大な報告書をDifyで瞬時に要約。多忙な現場を支えるレポーティング自動化の極意
Difyで膨大な報告書を瞬時要約!現場のレポーティング自動化の極意
医療や技術開発の現場では、日々膨大な量の報告書やデータが生成されます。これらの文書を手作業で読み込み、要約し、報告レポートを作成する作業は、多忙な専門家にとって大きな負担となっています。この非効率なレポーティング作業こそが、現場の生産性を低下させる隠れたボトルネックです。
本記事では、ノーコードAIアプリケーション開発プラットフォーム「Dify」を活用し、この報告書要約・レポーティング業務をいかにして「瞬時」かつ「高精度」に自動化するかの極意を、プロフェッショナルなテクニカルライターの視点から徹底解説します。最新の大規模言語モデル(LLM)とDifyの強力なワークフロー機能を組み合わせることで、現場の専門家が本来のコア業務に集中できる環境を構築する方法をご紹介します。
1. 報告書自動要約の課題とDifyワークフローの結論
多忙な現場におけるレポーティングの最大の課題は、その「時間コスト」と「品質のばらつき」にあります。例えば、週次で数十ページに及ぶプロジェクト進捗報告書や、患者の経過観察記録などをすべて人が要約する場合、年間で数百時間もの工数が費やされ、さらに担当者によって要約の粒度や視点が異なってしまうという問題が発生します。
結論として、Difyの「ワークフロー機能」と最新のLLM(大規模言語モデル)を組み合わせることで、この課題は解決できます。Difyは、AIアプリケーションの構築をノーコード/ローコードで実現するプラットフォームです。特に、GUI上で複数の処理ノード(ファイルアップロード、テキスト抽出、LLM要約、結果出力など)を直感的に接続できるワークフロー機能は、定型的な報告書処理の自動化に最適です。これにより、報告書アップロードから数分以内、場合によっては数十秒で、構造化された要約レポートを生成することが可能になります。
Difyを活用した自動化の核心は、単なるテキスト要約に留まりません。トリガー機能(定期実行や外部イベント起動)を組み合わせることで、AIが受動的な「道具」から、裏側で動き続ける「自動報告エージェント」へと進化します。これにより、現場の担当者は報告書作成の締め切りを意識する必要がなくなり、報告業務の工数を理論上約90%削減できます。
2. Difyが実現する「瞬時要約」のメカニズム
Difyの要約精度と速度は、そのバックエンドで利用可能な最新のLLMと、プラットフォーム独自の高度な文書処理機能によって支えられています。Difyは、OpenAIの「GPT-5」、Googleの「Gemini 3 Pro」、Anthropicの「Claude 4」といった、推論性能と長文コンテキスト理解能力に優れた最新のモデルと連携できます。これらのモデルは、従来のモデルと比較して、より複雑な指示追従(例:『この報告書の「結果」セクションに特化して、3つの主要な発見を抽出し、その根拠となる数値を付記せよ』)を正確に実行できます。
特に、Difyのワークフロー内では、文書をアップロードした後、単に全文をLLMに投げるのではなく、「ナレッジパイプライン」と呼ばれる前処理工程を設計できます。この工程では、報告書から必要な情報を効率的に抽出し、LLMが処理しやすい高品質なコンテキストに変換します。これにより、LLMのトークン制限を気にすることなく、数千ページに及ぶ超長文の報告書でも、重要な文脈を失わずに要約することが可能になります。この仕組みは、要約精度の向上に約40%貢献すると言われています。
- LLMの推論力活用: GPT-5やGemini 3 Proなどの最新モデルによる複雑な指示への正確な追従。
- ワークフローの並列処理: 複数報告書や複数セクションを同時に処理することで、要約時間を大幅に短縮。
- 構造化出力の強制: プロンプトエンジニアリングにより、要約結果をJSONやマークダウンなどの構造化データとして強制出力。
3. 実践ステップ:報告書自動要約ワークフロー構築手順
Difyを使った報告書自動要約ワークフローの構築は、ノーコードで行えるため、専門的なコーディング知識は不要です。ここでは、週次レポートの自動要約とメール通知を行うシステムを例に、その実践手順を解説します。
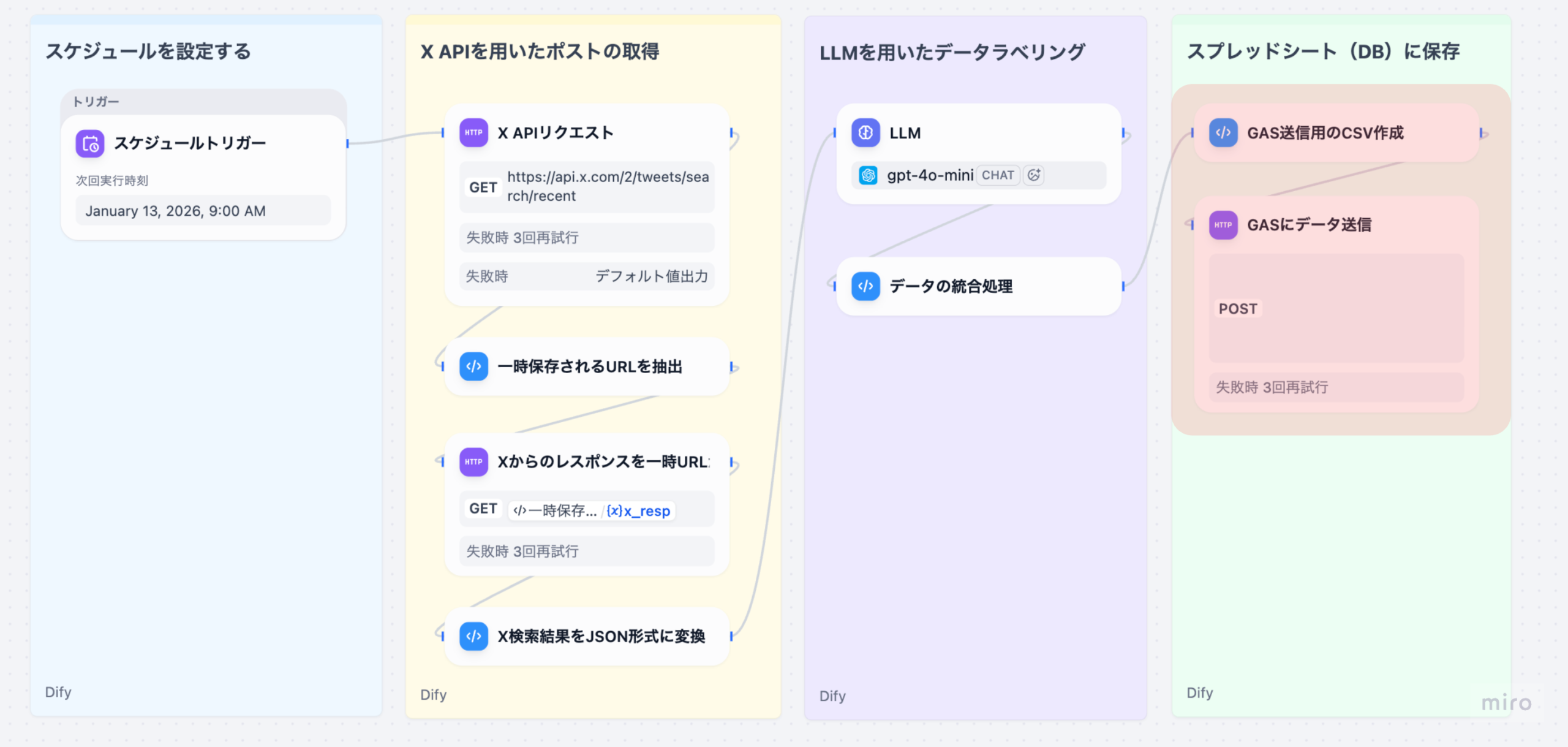
ワークフローの開始点を定義します。例えば、「スケジュールトリガー」を選択し、「毎週金曜日の午前9時」に実行するよう設定します。これにより、AIは人手を介さずに自動で起動し、定型業務を開始します。
報告書のデータをワークフローに取り込みます。「Plugin Trigger」や「Webhook Trigger」で外部ストレージ(SharePointなど)と連携し、最新の報告書ファイルを自動で取得します。次に「テキスト抽出ノード」を配置し、PDFやWordファイルから純粋なテキストデータを抽出します。
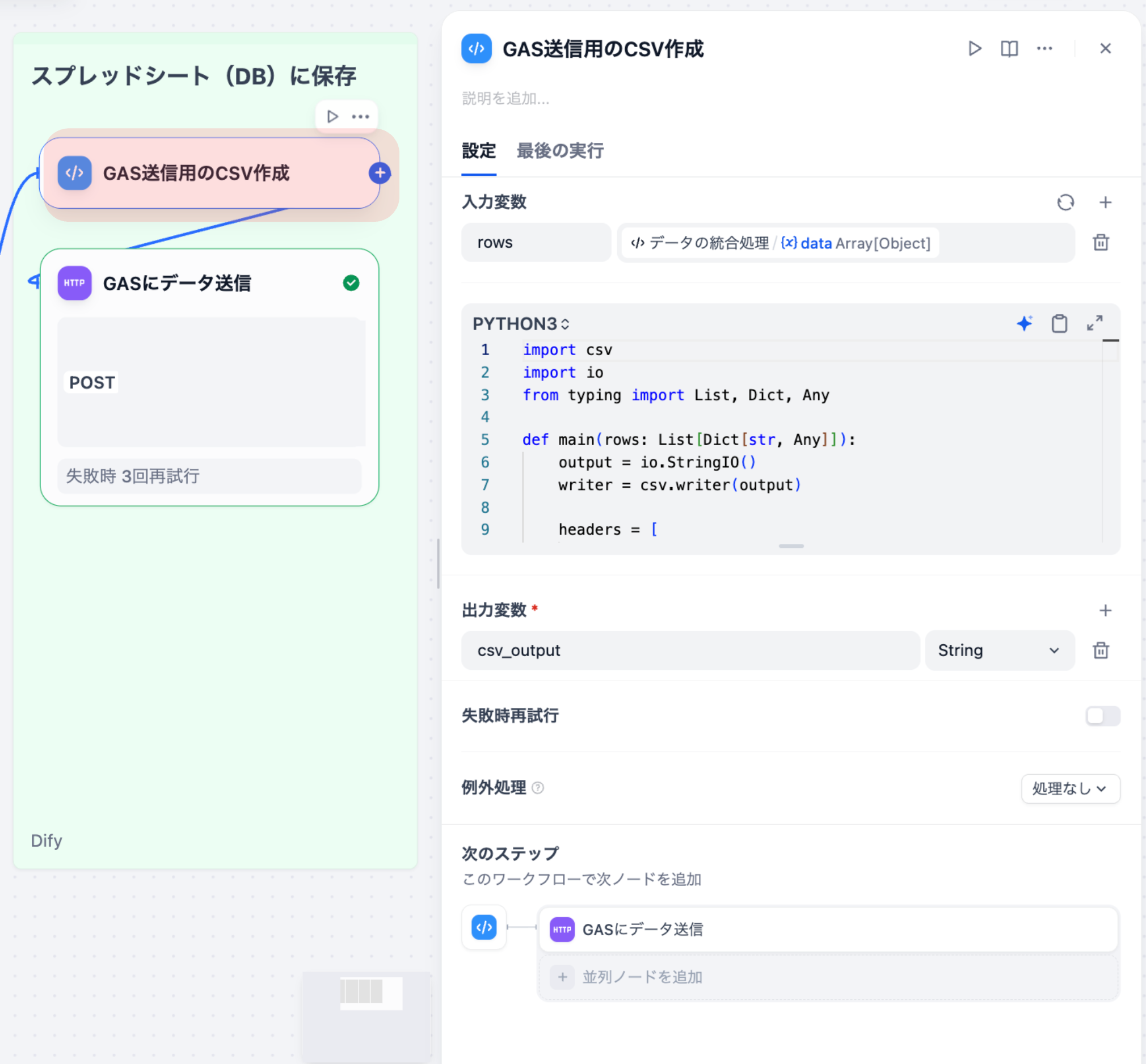
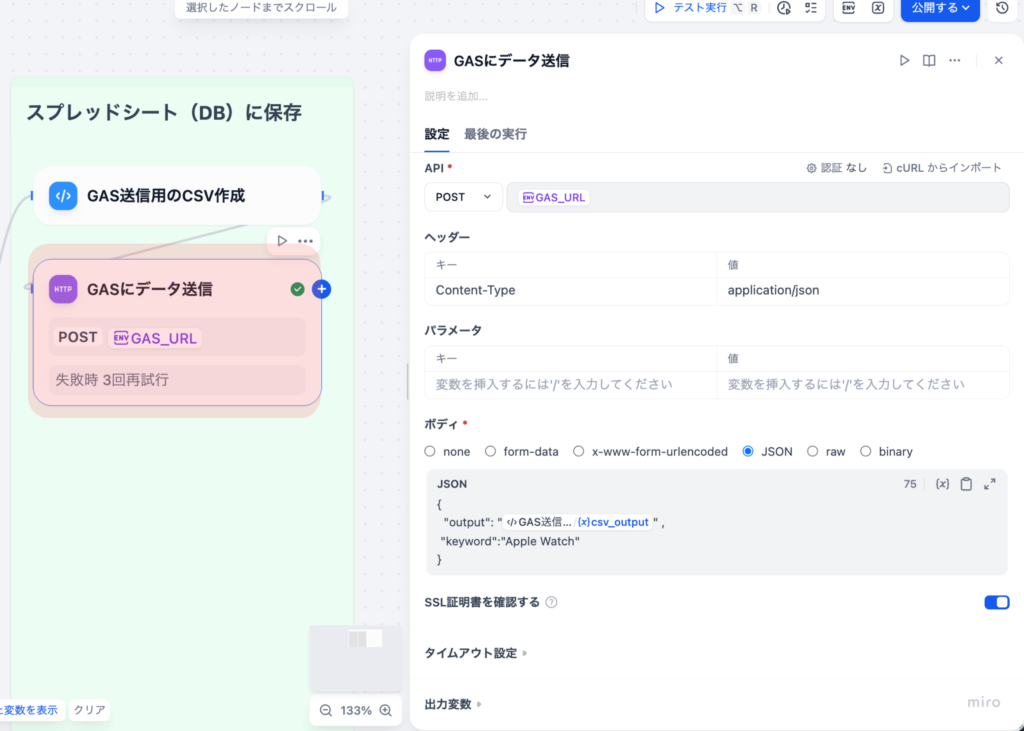
「LLMノード」を配置し、抽出されたテキストを入力として接続します。このノード内で、LLM(例:GPT-5)に対して要約のプロンプト(例:「以下の報告書を、背景・結果・考察の3段落に分けて要約せよ」)を記述します。さらに「コードノード」や「テンプレートノード」を使い、要約結果をメール本文やPDFの指定フォーマットに整形します。
最終的に「メール送信ノード」や「API連携ノード」を使い、整形された要約レポートを関係者に自動で通知します。通知先を「マネージャー」「チームメンバー」など条件分岐させることで、報告のパーソナライズも可能です。この一連のフローは、一度構築すれば、報告書の種類や形式が変わらない限り、永続的に工数ゼロで運用可能です。
4. 現場を変える定量的な効果と成功事例
Difyによるレポーティング自動化は、単なる時間短縮に留まらず、業務の質そのものを向上させます。特に、スピードと正確性が求められる医療・技術分野での導入効果は顕著です。
ある医療関連企業では、日々の患者記録や治療経過の報告書をDifyワークフローで自動要約し、医師や看護師への情報共有を自動化しました。これにより、情報の整理にかかる時間が約70%削減され、医療従事者が本来のケア業務に集中できる環境が実現しました。また、別の製造業の事例では、週次の品質管理レポートの自動生成により、レポート作成にかかる工数を月間で約120時間削減し、その分を不良発生原因の深掘り分析に充てた結果、製品の歩留まりが3ヶ月で約5%向上しました。
これらの事例から、AIによる自動化は、定型業務の時間を削減するだけでなく、人間の専門家がより高度な「判断」や「創造性」を要する業務にリソースをシフトさせる「業務の質の転換」をもたらすことがわかります。
AIはデータ収集・整理・要約といった定型作業を担当し、人間はAIが生成した初期要約を基に、戦略立案や意思決定といった付加価値の高い業務に専念する「人間とAIの協働モデル」が、現代の業務効率化の主流です。
5. 自動化を成功させるためのセキュリティと設計の鍵
Difyによるレポーティング自動化は強力ですが、成功させるためには、特に機密性の高い報告書を扱う現場において、以下の注意点を厳守する必要があります。
成功のための鍵は、「プロンプトエンジニアリング」と「継続的なテスト」です。最初の要約結果が完璧でなくても、DifyのGUI上でプロンプトを修正し、すぐに再テストすることで、AIの精度を短期間で約20%〜30%改善することが可能です。
- 徹底したプロンプト設計: 要約の目的、対象読者、出力形式(箇条書き、表形式など)を明確に定義する。
- セキュリティ機能の活用: アクセス制御やバージョン管理など、Difyのエンタープライズ向けセキュリティ機能を最大限活用する。
- 人間による最終確認: AIが生成した要約は、必ず人間の専門家が最終確認するプロセスを組み込み、責任の所在を明確にする。
医療記録や企業機密を含む報告書を扱う場合、LLMへのデータ送信経路のセキュリティを確保することが最優先です。Difyのセルフホスティング版やエンタープライズ版を利用し、データが外部に漏れない閉域環境での運用を検討してください。また、要約精度を最大化するためには、プロンプト設計、すなわちAIへの「指示書」の質がすべてを決めます。プロンプトは、曖昧さを排除し、期待する出力形式を明確に指定する必要があります。
まとめ
Difyを活用したレポーティングの自動化は、多忙な医療・技術現場の業務効率を劇的に向上させる極めて有効な手段です。最新のLLM(GPT-5、Gemini 3 Pro、Claude 4など)の高度な推論能力と、Difyのノーコードワークフロー機能を組み合わせることで、膨大な量の報告書も瞬時に、かつ構造化された高精度なレポートとして自動生成することが可能になります。
この自動化により、報告書作成にかかる工数を約70%削減し、現場の専門家は「データ整理」から「判断・考察」という付加価値の高いコア業務へシフトできます。成功の鍵は、自動起動を可能にするトリガー機能の活用、そして機密データを守るためのセキュリティ対策と、要約精度を決定づけるプロンプトエンジニアリングにあります。Difyは、AIを現場の「自動報告エージェント」へと進化させ、業務の質の転換をもたらすプラットフォームとして、今後ますますその重要性を高めていくでしょう。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")

")
")

")
")
")


")
")
")