")
Part3. LLMを⽤いて⾃動でデータラベルを付与する
| 目次 |
1. はじめに
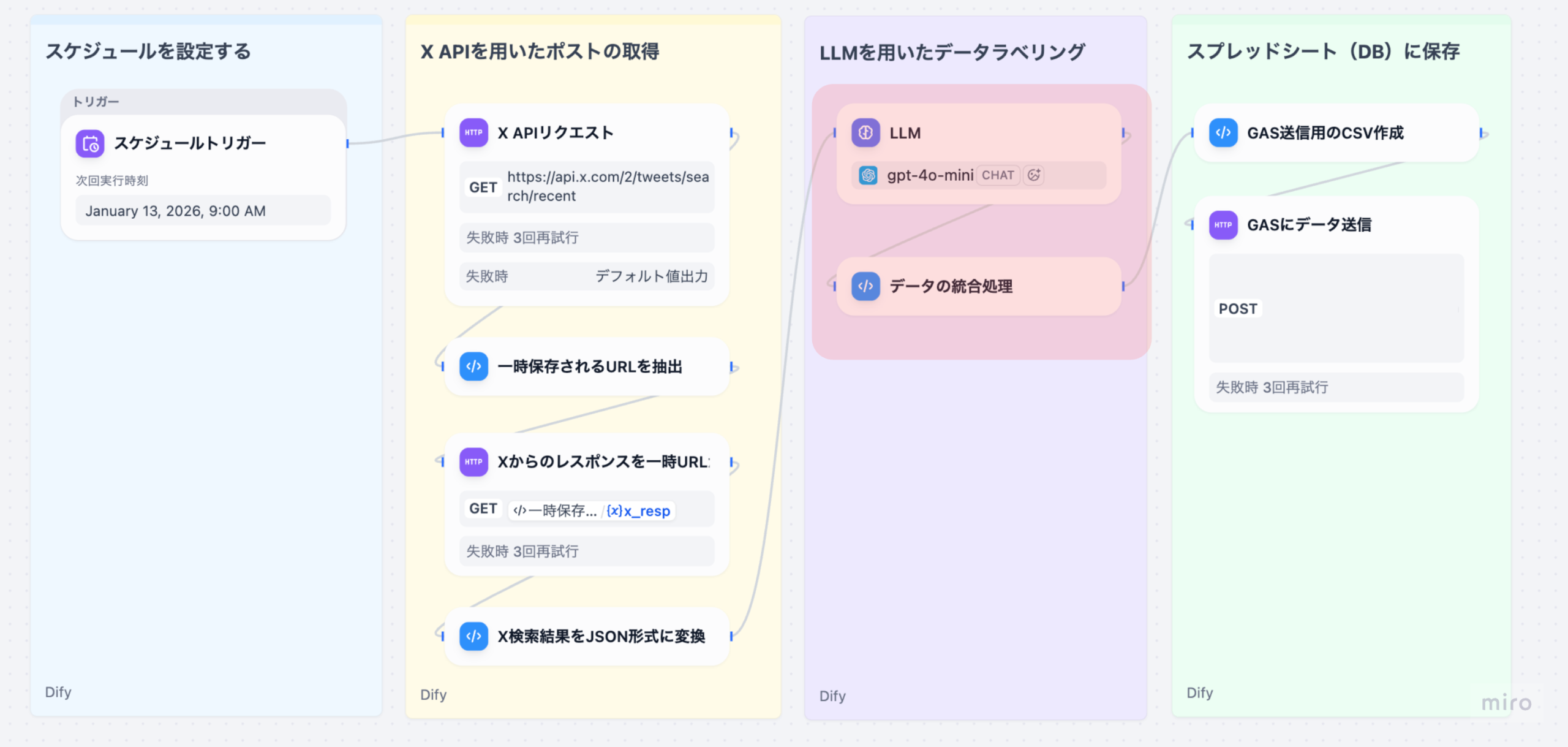
本記事は、Difyのワークフローを使って、X(旧Twitter)のソーシャルリスニングを⾃動化するシリーズのPart 3です。
Part 2の復習: 前回の記事では、DifyのワークフローでX APIからツイートを取得し、構造化データに変換するまでの処理を解説しました。具体的には、以下のノードを実装しました。
- X APIリクエスト(ツイート検索)
- ⼀時URL抽出 • 取得(実際のデータ取得)
- JSON形式変換(構造化データへの変換)
本記事(Part 3)では、取得したツイートデータに対してLLMで感情判定 ‧ 感情ラベル付与、健康関連性の判定、カテゴリ分類(health_monitoring/ fitness/ gadget/ notification/ other)、健康トピックおよびデバイストピックの抽出を⾏い、元データと統合する処理を詳しく解説します。この部分は、ワークフローの核⼼となるAI処理部分です。
シリーズ構成
- Part 0: X APIを⽤いたソーシャルリスニング概要
- Part 1: X 旧Twitter) APIの基礎
- Part2: Difyを⽤いてX APIから直近のポストを取得する
- Part 3(本記事): LLMを⽤いて⾃動でデータラベルを付与する
- Part 4: スプレッドシートにデータを格納する
- Part5: Streamlitを⽤いたデータの可視化例
2. Part 2からの流れ
Part 2で取得したデータは、以下のような構造になっています。
{
"items_json": "[{\\"tweet_id\\":\\"1234567890\\",\\"text\\":\\"Apple Watchの効果...\\",\\"created_at\\":\\"2025-01-14T12:00:00.000Z\\",...}]",
"items": [
{
"tweet_id": "1234567890",
"text": "Apple Watchの効果...",
"created_at": "2025-01-14T12:00:00.000Z",
"author_id": "987654321",
"retweet_count": 10,
"reply_count": 5,
"like_count": 20,
"quote_count": 2,
}
]
}
本記事では、このツイートデータに対して、以下の処理を⾏います。
- LLMで各ツイートの感情ラベル判定、健康関連性の判定、カテゴリ分類、健康トピック • デバイストピックの抽出
- LLM結果と元データをマージ(tweet_idをキーに統合)
3. 各ノードの詳細解説
3-1. LLM(LLMノード)
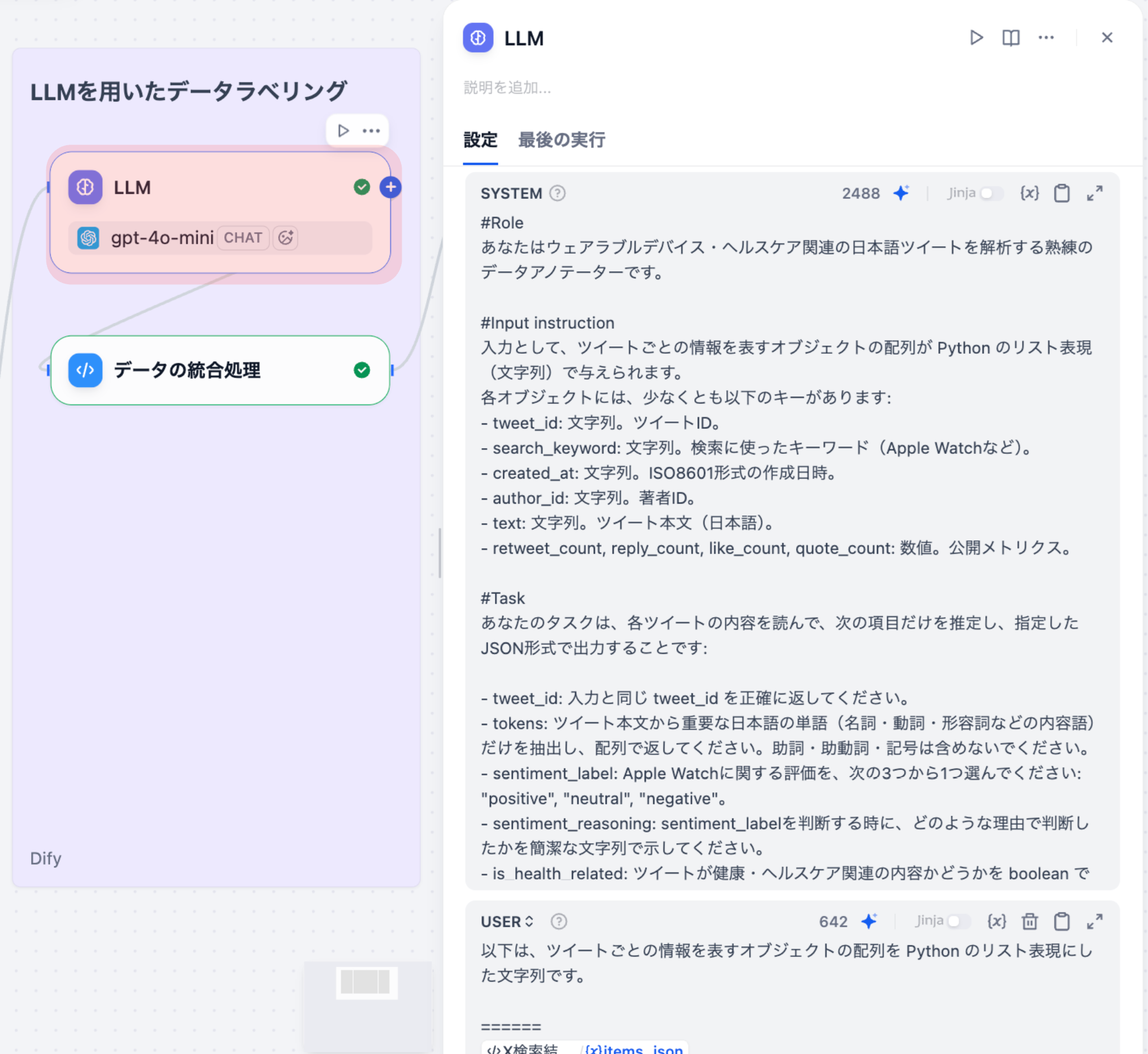
各ツイートに対して、感情ラベル判定、健康関連性の判定、カテゴリ分類、健康トピック • デバイストピックの抽出を⾏うLLMノードです。ウェアラブルデバイス • ヘルスケア関連の⽇本語ツイートを解析するための専⾨的なプロンプトを設計しています。
プロンプトテンプレート
System メッセージ
#Role
あなたはウェアラブルデバイス・ヘルスケア関連の日本語ツイートを解析する熟練のデータアノテーターです。
#Input instruction
入力として、ツイートごとの情報を表すオブジェクトの配列が Python のリスト表現(文字列)で与えられます。各オブジェクトには、少なくとも以下のキーがあります:
- tweet_id: 文字列。ツイートID。
- search_keyword: 文字列。検索に使ったキーワード(Apple Watchなど)。
- created_at: 文字列。ISO8601形式の作成日時。
- author_id: 文字列。著者ID。
- text: 文字列。ツイート本文(日本語)。
- retweet_count, reply_count, like_count, quote_count: 数値。公開メトリクス。
#Task
あなたのタスクは、各ツイートの内容を読んで、次の項目だけを推定し、指定したJSON形式で出力することです:
- tweet_id: 入力と同じ tweet_id を正確に返してください。
- tokens: ツイート本文から重要な日本語の単語(名詞・動詞・形容詞などの内容語)だけを抽出し、配列で返してください。助詞・助動詞・記号は含めないでください。
- sentiment_label: Apple Watchに関する評価を、次の3つから1つ選んでください: "positive", "neutral", "negativ e"。
- sentiment_reasoning: sentiment_labelを判断する時に、どのような理由で判断したかを簡潔な文字列で示してください。
- is_health_related: ツイートが健康・ヘルスケア関連の内容かどうかを boolean で返してください。以下のような内容が含まれる場合は true にしてください:
* 心拍数、心拍変動、心拍モニタリング
* 運動、ワークアウト、フィットネス、エクササイズ
* 睡眠、睡眠トラッキング、睡眠の質
* 血中酸素(SpO2)、酸素飽和度
* ECG(心電図)、不整脈検出
* 活動量、カロリー消費、歩数
* メンタルヘルス、ストレス、マインドフルネス
* 健康アプリ、ヘルスケア連携、健康データ
* 病気のモニタリング、症状追跡、健康状態の記録
* その他、健康や身体状態に関する言及
- category: ツイートのメインカテゴリを以下のいずれか1つ選んでください:
* "health_monitoring": 健康モニタリング機能に関する内容(心拍数、ECG、血中酸素、睡眠など)
* "fitness": フィットネス・運動に関する内容(ワークアウト、運動記録、活動量など)
* "gadget": ガジェットとしての側面に関する内容(デザイン、価格、機能、バッテリー、比較、レビューなど)
* "notification": 通知・連絡機能に関する内容
* "other": 上記に当てはまらない内容
- health_topics: is_health_related が true の場合、ツイートで言及されている健康関連トピックを日本語の短い名詞句として配列で返してください。該当がなければ空配列 [] を返してください。以下のようなトピックを含めてください:
* 心拍数、心拍変動、心拍モニタリング
* 運動、ワークアウト、フィットネス、エクササイズ、ランニング、サイクリング
* 睡眠、睡眠トラッキング、睡眠の質、レム睡眠
* 血中酸素、SpO2、酸素飽和度
* ECG、心電図、不整脈、心房細動
* 活動量、カロリー、歩数、消費カロリー
* メンタルヘルス、ストレス、マインドフルネス、呼吸
* 健康アプリ、ヘルスケア、健康データ
* その他、健康や身体状態に関する具体的な言及
- device_topics: category が "gadget" の場合、またはガジェットとしての側面が言及されている場合、ツイートで言及されているデバイス関連トピックを日本語の短い名詞句として配列で返してください。該当がなければ空配列 [] を返してください。以下のようなトピックを含めてください:
* デザイン、見た目、スタイル、カラー、サイズ
* 価格、コスト、購入、販売
* バッテリー、充電、バッテリー寿命
* 機能、スペック、性能
* 比較、他製品との比較
* レビュー、評価、感想
* アクセサリー、バンド、ケース
* その他、デバイスとしての側面に関する具体的な言及
#Discipline
重要な制約:
- 入力の配列の長さは任意ですが、必ず全ての要素について判断してください。
- 出力には、入力の全ての要素分の結果を含めてください。
- 出力では、 tweet_id を必ず含め、入力と同じ tweet_id を正確に返してください。
- 出力では、ここに列挙したキー「tweet_id, tokens, sentiment_label, sentiment_reasoning, is_health_relate d, category, health_topics, device_topics」以外のキーは含めないでください。
- JSON 形式の文字列のみを出力し、説明文やコメント、余計なテキストは一切含めないでください。
- is_health_related が true の場合、health_topics には必ず該当するトピックを記載してください。
- category が "gadget" の場合、またはデバイス関連の言及がある場合、device_topics には必ず該当するトピックを記載してください。
User メッセージ
======
#items_json#
======
この配列の各要素について、SYSTEMメッセージで指定した項目だけを推定し、次のようなJSON形式で出力してください。
```json
{
"results": [
{
"tweet_id": "<元の tweet_id>",
"tokens": ["Apple Watch", "心拍数", "睡眠トラッキング"],
"sentiment_label": "<positive|neutral|negative>",
"sentiment_reasoning": "<なぜsentiment_labelの判断を下したかの理由>",
"is_health_related": true,
"category": "<health_monitoring|fitness|gadget|notification|other>",
"health_topics": ["心拍モニタリング", "睡眠トラッキング"],
"device_topics": ["バッテリー寿命", "デザイン"]
}
]
}
```
必ず有効なJSONのみを出力し、日本語の文章や説明は一切含めないでください。
ダブルクオーテーションを用いてください。
プロンプト設計のポイント
- Role定義: ウェアラブルデバイス • ヘルスケア関連ツイートに特化したデータアノテーターとして定義
- 明確なタスク定義: 8つの項⽬(tweet_id, tokens, sentiment_label, sentiment_reasoning, is_health_related, category, health_topics, device_topics)を明確に定義
- カテゴリ設計: health_monitoring / fitness / gadget / notification / other の5カテゴリを定義
- トピック設計: 健康トピックとデバイストピックをそれぞれ⽇本語の短い名詞句として抽出
- 厳格な制約: JSON形式のみを出⼒し、説明⽂やコメントを禁⽌
抽出項⽬の詳細
| 項⽬名 | 型 | 説明 | 例 |
|---|---|---|---|
| tweet_id | string | ⼊⼒と同じツイートID | “1234567890” |
| tokens | array[string] | ツイート本⽂から抽出した重要な⽇本語の単語リスト (助詞 • 助動詞を除く) | [“Apple Watch”, “心拍数”] |
| sentiment_label | string | Apple Watchに関する評価 | “positive”,“neutral”,“negative” |
| sentiment_reasoning | string | 感情判断の理由 | “健康機能への満足度が高い” |
| is_health_related | boolean | 健康 • ヘルスケア関連の内容かどうか | true / false |
| category | string | ツイートのメインカテゴリ | “health_monitoring” 、 “fitness” 、 “gadget” など |
| health_topics | array[string] | 健康 • ヘルスケアに関する具体的なトピック | [“心拍モニタリング”, “睡眠トラッキング”] |
| device_topics | array[string] | デバイスとしての側⾯に関するトピック | [“バッテリー寿命”, “デザイン”] |
出⼒例
{
"results": [
{
"tweet_id": "1234567890",
"tokens": ["Apple Watch", "心拍数", "睡眠"],
"sentiment_label": "positive",
"sentiment_reasoning": "健康管理機能への満足度が高い内容",
"is_health_related": true,
"category": "health_monitoring",
"health_topics": ["心拍モニタリング", "睡眠トラッキング"],
"device_topics": ["バッテリー寿命"]
}
]
}
LLMの不安定性への対応
注意: LLMの出⼒は不安定な場合があります。以下のような問題が発⽣する可能性があります。
- tweet_idが間違っている
- tweet_idが抜けている
- ⽣成対象のテキストと内容がずれている
これらの問題に対処するため、後続のデータ統合処理で、tweet_idをキーにしたマージ処理を⾏い、データ整合性を確保します。
3-2. データの統合処理(Codeノード)
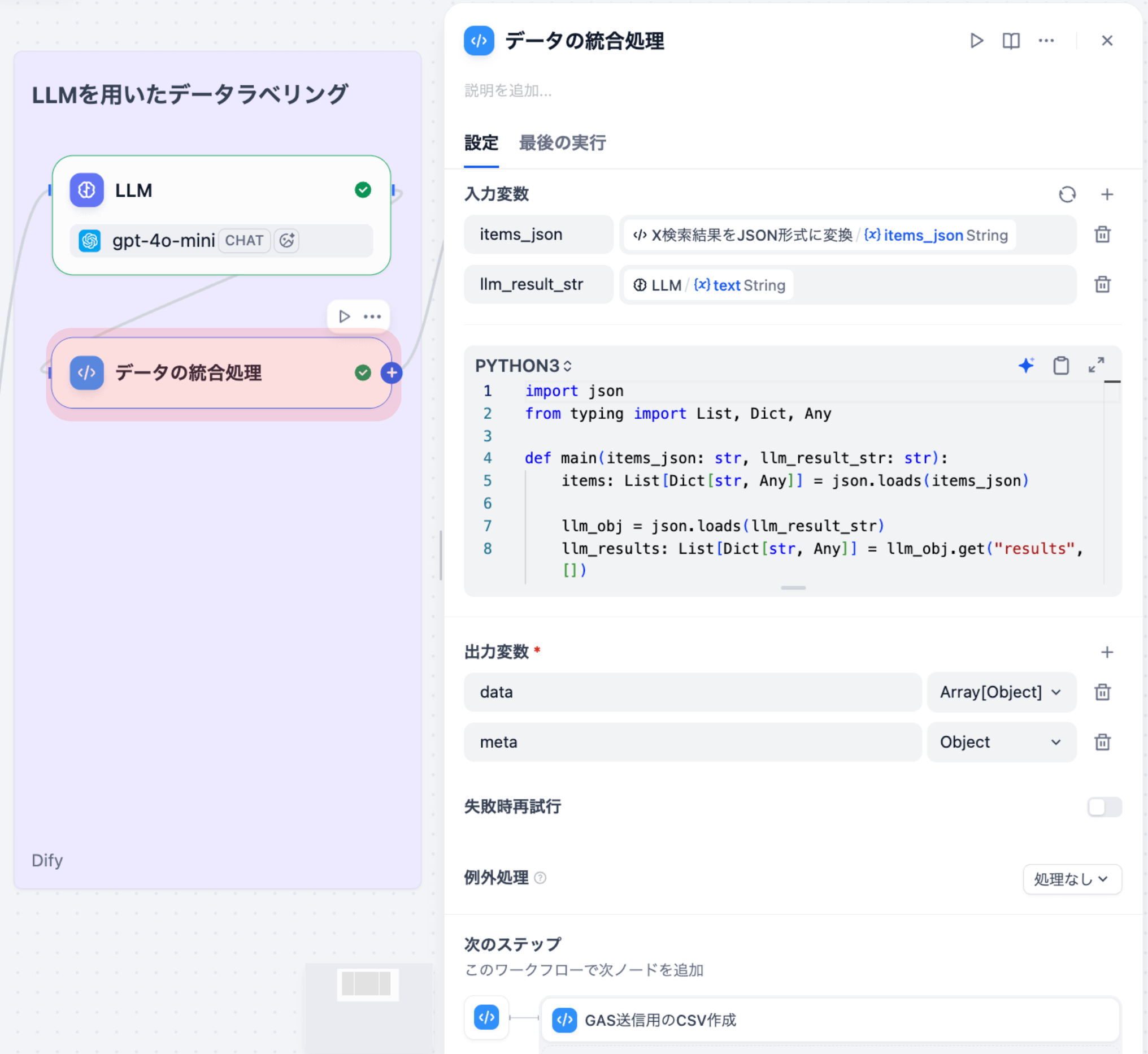
LLMの出⼒結果と元のツイートデータをマージするノードです。tweet_idをキーにして、LLMで抽出した情報を元データに統合します。
⼊⼒変数
| 変数名 | ソース | 型 |
|---|---|---|
| items_json | X検索結果をJSON形式に変換ノード | string |
| llm_result_str | LLMノード | string |
コード
import json
from typing import List, Dict, Any
def main(items_json: str, llm_result_str: str):
# 元のツイートデータをパース
items: List[Dict[str, Any]] = json.loads(items_json)
# LLMの出力をパース
llm_obj = json.loads(llm_result_str)
llm_results: List[Dict[str, Any]] = llm_obj.get("results", [])
# tweet_idをキーにしたマップを作成(高速検索のため)
llm_map = {r.get("tweet_id"): r for r in llm_results if r.get("tweet_id")}
# 各ツイートデータにLLM結果をマージ
for item in items:
tid = item.get("tweet_id")
if not tid:
continue # tweet_idがない場合はスキップ
# LLM結果が存在する場合、各フィールドをマージ
if tid in llm_map:
llm = llm_map[tid]
for key in [
"tweet_id",
"tokens",
"sentiment_label",
"sentiment_reasoning",
"is_health_related",
"category",
"health_topics",
"device_topics",
]:
if key in llm:
item[key] = llm[key]
# ツイートのURLを生成
item["post_url"] = f"<{{
処理の流れ
- データパース: 元のツイートデータ(JSON⽂字列)とLLM出⼒(JSON⽂字列)をそれぞれパース
- マップ作成: LLM結果をtweet_idをキーにした辞書(マップ)に変換(⾼速検索のため)
- ループ処理: 各ツイートデータに対して:
- tweet_idを取得
- LLM結果マップから該当する結果を検索
- ⾒つかった場合、各フィールド(is_health_related, category, health_topics等)をマージ
- ツイートのURLを⽣成(
https://x.com/i/web/status/\{tweet_id\})
- 出⼒: マージ済みのデータとメタ情報を返す
エラーハンドリング
- tweet_idがない場合: そのツイートはスキップ
- LLM結果に該当するtweet_idがない場合: 元データのまま(初期値のまま)
- JSONパースエラー: 例外が発⽣する可能性があるため、後続処理でエラーハンドリングが必要
出⼒データ構造
マージ後のデータは、以下のような構造になります。
{
"data": [
{
"tweet_id": "1234567890",
"search_keyword": "Apple Watch",
"created_at": "2025-01-14T12:00:00.000Z",
"author_id": "987654321",
"text": "Apple Watchの心拍数と睡眠トラッキングが便利...",
"retweet_count": 10,
"reply_count": 5,
"like_count": 20,
"quote_count": 2,
"sentiment_label": "positive",
"sentiment_reasoning": "健康管理機能への満足度が高い内容",
"is_health_related": true,
"category": "health_monitoring",
"health_topics": ["心拍モニタリング", "睡眠トラッキング"],
"device_topics": ["バッテリー寿命"],
"tokens": ["Apple Watch", "心拍数", "睡眠トラッキング"],
"post_url": "<https://x.com/i/web/status/1234567890>">
}
],
"meta": {
"result_count": 20
}
}
出⼒
| 出⼒名 | 型 | 説明 |
|---|---|---|
| data | array[object] | マージ済みのツイートデータ配列 |
| meta | object | メタ情報(result_count等) |
4. まとめ
本記事(Part 3)では、取得したツイートデータに対してLLMで感情ラベル付与、健康関連性の判定、カテゴリ分類、健康トピック • デバイストピックの抽出を⾏い、元データと統合する処理を詳しく解説しました。
本記事で実現したこと
- LLMプロンプトの設計(Role, Input instruction, Task, Discipline)
- 感情ラベル判定とカテゴリ分類の実装
- 健康トピック • デバイストピックの抽出
- LLM結果と元データの統合処理(tweet_idをキーにしたマージ)
- エラーハンドリングとデータ整合性の確保
処理の流れの確認
- LLM処理: ツイート配列に対して感情ラベル判定、健康関連性の判定、カテゴリ分類、健康トピック • デバイストピック抽出を実⾏
- データ統合: tweet_idをキーにLLM結果と元データをマージ
- URL⽣成: 各ツイートのURLを⾃動⽣成
次のステップ
次回のPart 4では、ここで統合したデータをCSV形式に変換し、Google Apps Script(GAS)に送信してスプレッドシートに保存する処理を解説します。具体的には以下のテーマを扱います。
- CSV形式への変換処理(カラム定義、データ整形)
- GASへのHTTPリクエスト(POST, JSON形式)
- スプレッドシートへの⾃動保存
- レスポンス処理とエラーハンドリング
これらの処理により、ワークフローが完成し、定期的にツイートを取得 • 分析 • 保存するシステムが完成します。
シリーズ構成
- Part 0: X APIを⽤いたソーシャルリスニング概要
- Part 1: X 旧Twitter) APIの基礎
- Part2: Difyを⽤いてX APIから直近のポストを取得する
- Part 3: LLMを⽤いて⾃動でデータラベルを付与する
- Part 4: スプレッドシートにデータを格納する(←次の記事)
- Part5: Streamlitを⽤いたデータの可視化例

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら

監修者 株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中
")
")
")