")
PubMed 最新論文を要約して定期配信 Part1
| 目次 |
1. 導入
1.1 本記事の概要
本記事では、PubMedの最新論文を定期的に自動収集し、SlackやGmailへ配信する仕組みを紹介します。
n8nというオープンソースの自動化ツールを用いることで、検索から要約、配信までを完全に自動化することが可能です。
1.2 想定読者と利用シーン
- 製薬会社・医療機器メーカーの研究開発(R&D)、学術、メディカルアフェアーズ、マーケティング部門
- 研究者やアカデミアの方々
- ライフサイエンス関連ビジネスに従事し、PubMedを日常的に利用する方
日常業務で論文検索や要約に時間を奪われている方に特に有効です。
また、KOL(Key Opinion Leader)調査や疾患啓発資料の準備など、特定テーマでのクイック調査にも応用可能です。
1.3 本記事のポイント
- PubMed API key不要の構築方法(大量取得や安定運用にはAPI key推奨、後日紹介予定)
- 検索 → 要約 → 配信まで完全自動化されたワークフロー
- 検索対象は疾患名だけでなく、治療法・薬剤・デバイス・分子標的・著者名など自由に設定可能
2. 背景と目的
2.1 背景:PubMed活用の実態
PubMedは生命科学・医学分野で世界最大級の文献データベースとして、製薬企業・医療機器メーカー・アカデミアで幅広く利用されています。
研究開発では新薬や医療機器に関する最新研究成果を把握するために、メディカルアフェアーズでは医師への情報提供や学会発表準備に、マーケティング部門では疾患や競合の動向分析やKOL調査に活用されています。
さらに研究者や学生にとっても、レビュー作成や博士論文準備に欠かせない情報源となっています。
2.2 現状の課題
一方で、新着論文は膨大であり、週単位での追跡は困難です。
抄録作成や翻訳には人手が必要で効率が悪く、論文を集めてもチーム内での共有が遅れることで情報が断片化しやすいという課題があります。
2.3 本取り組みの目的
これらの課題を解決するため、本取り組みでは新着論文を定期的に収集・要約し、自動でSlackやGmailに配信する仕組みを構築します。
これにより情報がタイムリーに共有され、研究効率や戦略立案のスピードを大幅に向上させることが可能になります。
実際は薬剤名や治療法などの条件で配信内容を柔軟に設定でき、SlackやGmailに加えてOutlookやTeamsといった環境でも利用できるように展開できますが、今回は論文のタイトルが「糖尿病」が含まれるものと課題を単純化しています。
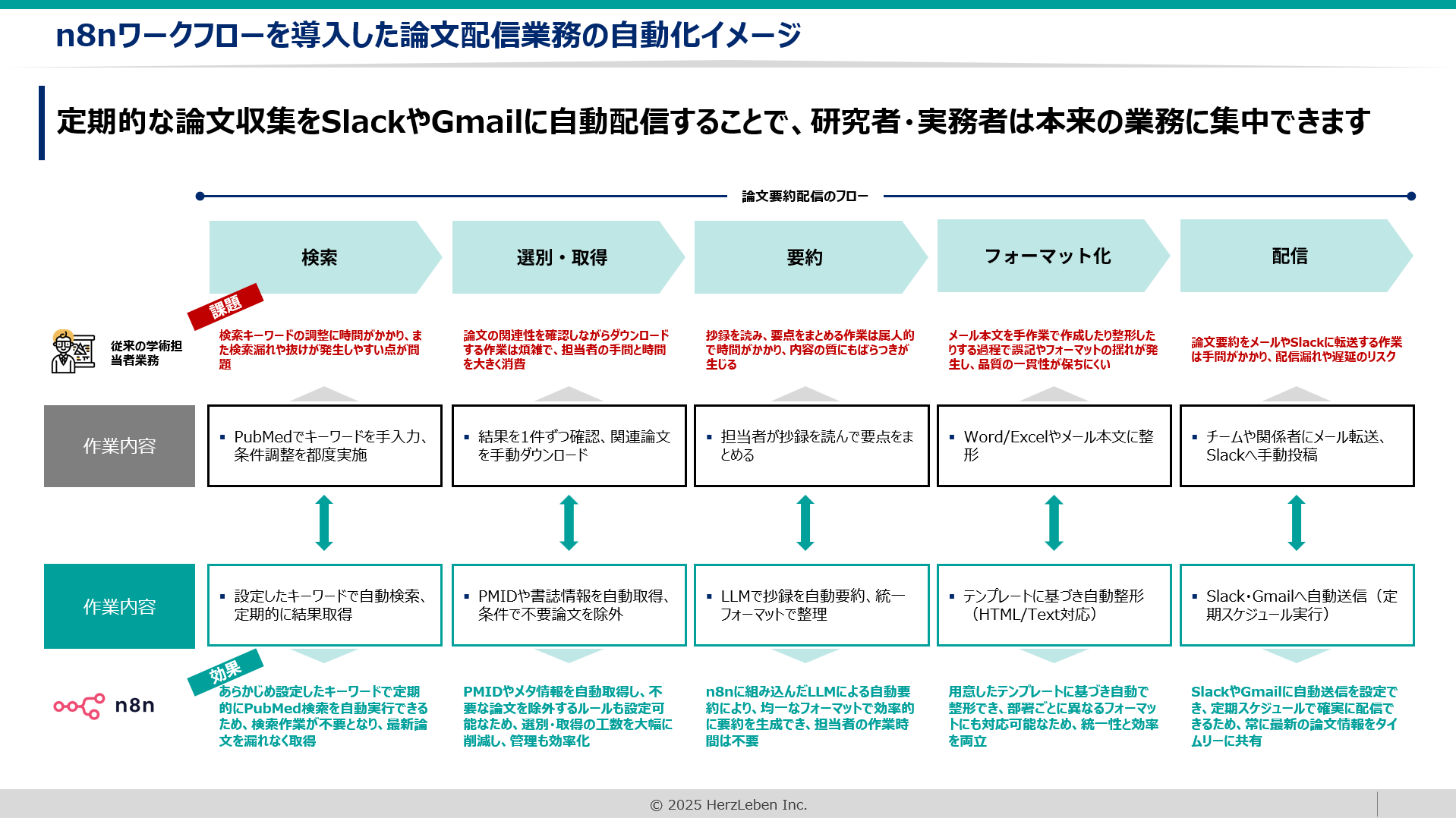
3. n8nの概要
3.1 n8nとは
n8nは、オープンソースのワークフロー自動化プラットフォームです(https://n8n.io/)。
GUIベースで外部サービスやAPIと直感的に連携できるため、研究業務における繰り返し作業を効率的に自動化することが可能です。
3.2 特徴
n8nの大きな特徴は、ノーコード/ローコードで利用できる点にあります。
プログラミング知識がなくても操作でき、900以上のサービスやAPIと連携できるため、幅広い業務に柔軟に対応できます。
また、データ処理や条件分岐といった複雑な設定もGUI上で直感的に実装できる仕組みが整っています。
さらに、オンプレミス環境とクラウド環境の両方に対応しているため、セキュリティ要件の厳しい企業でも導入が容易です。
欧米を中心に人気が拡大しており、製薬企業やアカデミアにおいても研究効率化のために利用が進んでいます。

4. PubMedの概要
4.1 PubMedとは
PubMedは米国国立医学図書館(NLM)が提供する無料の文献データベースであり、生命科学・医学分野における標準的な情報源として広く利用されています(https://pubmed.ncbi.nlm.nih.gov/)。
4.2 特徴
現在、PubMedには3,600万件を超える文献が収録されており、その内容は基礎研究から臨床試験、症例報告、さらにはレビュー論文まで幅広い範囲をカバーしています。
誰でも無料で利用できる点も大きな特徴であり、研究者だけでなく幅広いユーザーにとってアクセス可能な情報基盤となっています。
さらにAPIを通じて外部システムと連携できるため、自動化やデータ分析にも柔軟に対応できる仕組みが整っています。
4.3 利用シーン
PubMedは多様な場面で活用されています。
製薬企業においては新薬候補や適応拡大の可能性を調査するために利用され、医療機器メーカーではデバイス関連の臨床エビデンス収集に活かされています。
また研究者やアカデミアでは、研究テーマに関連するレビューや最新の研究成果を追跡するための重要な情報源となっています。
さらに、調査会社やコンサルティング企業では疾患領域のトレンド分析やKOL調査にも積極的に利用されています。
5. PubMed自動化フローの全体像
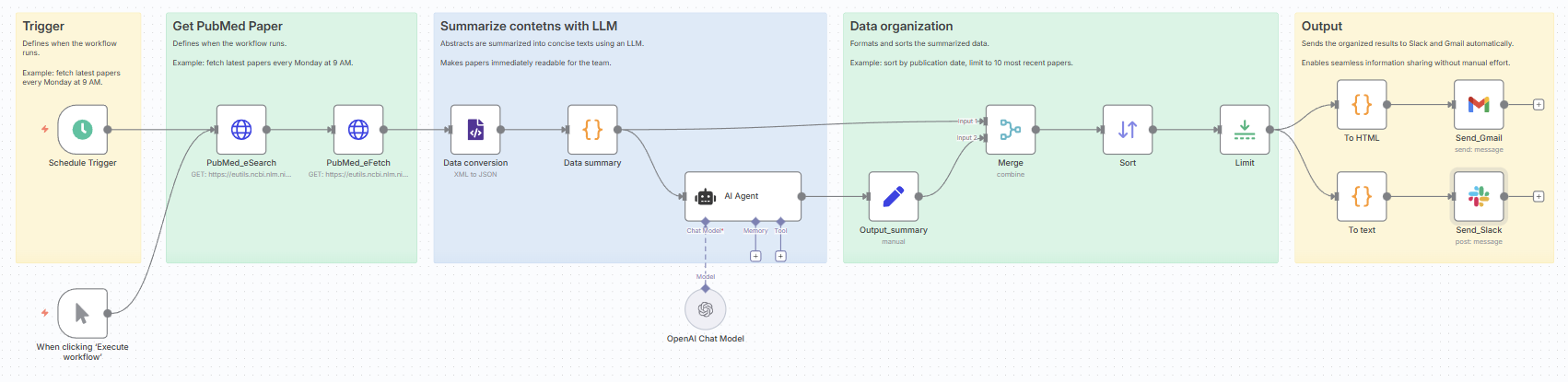
- スケジュールトリガー(定期配信の設定)
- PubMed API検索(eSearchでPMIDを取得)
- PubMed API詳細取得(eFetchでタイトル・著者・抄録を取得)
- データ整形(JSON/Codeノードで整備)
- 要約処理(OpenAI LLMで日本語要約を生成)
- 出力(Slack通知とGmail配信に展開)
6. 出力イメージ
この週間PubMed要約レポートでは、各論文のタイトル・著者・掲載日・雑誌名・DOIといった基本情報に加え、要点を日本語で自動要約した内容が一覧形式で届けられます。
利用者は毎週決まったタイミング(月曜日など)に、必要な論文情報を漏れなく把握できる仕組みです。
Gmail:

Slack:

7. まとめ
PubMedはライフサイエンス業界において欠かせない情報源ですが、検索や要約、配信には膨大な手間と時間がかかるのが現状です。
そこでn8nを活用することで、検索から要約、そして配信までを完全に自動化し、情報活用にかかるコストを大幅に削減することが可能となります。
検索条件は疾患名だけでなく、研究テーマや治療法、薬剤、デバイス、分子標的、著者名など多様に設定でき、利用者のニーズに応じた柔軟なカスタマイズが可能です。
その結果、研究者や実務担当者は煩雑な情報収集から解放され、本来の業務に集中できる環境を実現できます。
実装ステップ 詳細
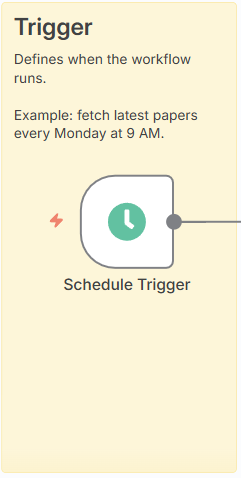
1. トリガー設定(Trigger)
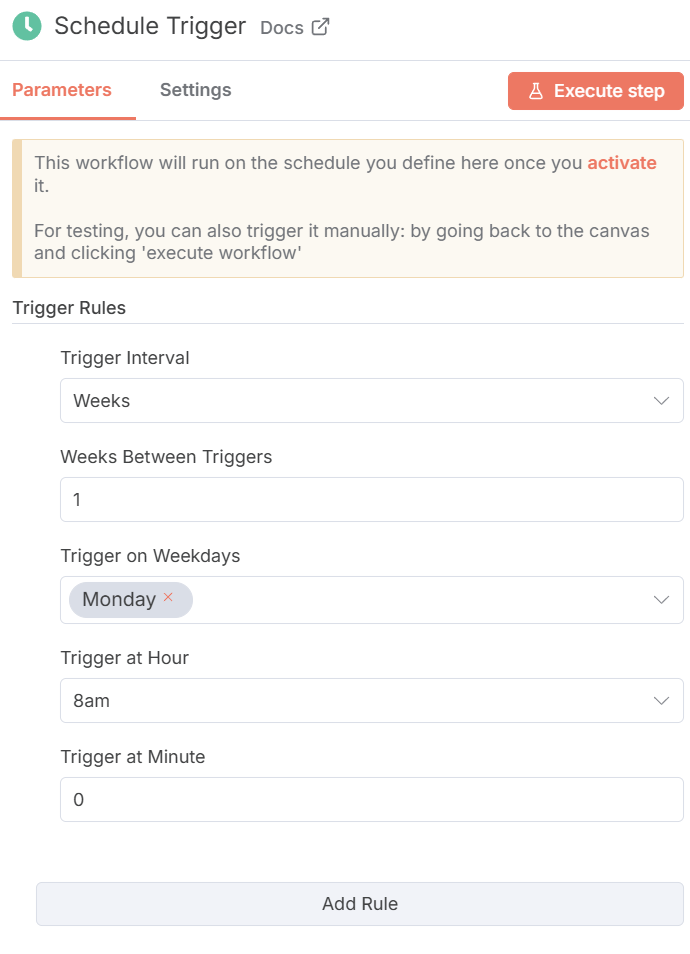
ノード:Schedule Trigger
- 設定例
- Mode: Every Week
- Day of Week: Monday
- Time: 09:00
- ポイント
毎週月曜朝9時に自動実行。社内定例や週次MTG前に最新論文が届く運用を想定。
 |
 |
2. PubMed検索(Get PubMed Paper)

(1) eSearch(PMID取得)
PubMedから論文ID(PMID)を取得するためのステップでは、HTTP Requestノードを使用します。
設定例:
- ノード:HTTP Request
- Method:GET
- URL:https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi
- Query Parameters
- db: pubmed
→ 検索対象のデータベースをPubMedに指定 - term: diabetes[Title/Abstract] OR “diabetes mellitus”[MeSH Terms]
→ 検索条件。タイトル/抄録、MeSH用語で柔軟に検索可能(疾患名・薬剤名などに変更可) - datetype: pdat
→ 日付種別を発表日(Publication Date)に指定 - reldate: 7
→ 直近7日間の論文を取得 - retmax: 20
→ 最大取得件数を20件に制限 - sort: pub date
→ 発表日順でソート - retmode: json
→ 出力形式をJSONに指定
- db: pubmed
(2) eFetch(詳細取得)
PubMed の論文詳細を取得する際には、以下のように HTTP Request ノードを設定します。
設定例:
- ノード:HTTP Request
- URL:https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi
- Query Parameters:
- db: pubmed
- id: {{$json[“esearchresult”][“idlist”].join(“,”)}}
- retmode: xml
- rettype: abstract
この設定により、先に取得した ID リストをカンマ区切りで連結し、PubMed API に渡します。
結果は XML 形式で返却され、各論文の タイトル、著者情報、ジャーナル、発行日、DOI、抄録 といった詳細情報を取得することができます。
つまり、eSearch で検索キーワードに合致する文献の PMIDs を集め、その ID 群を eFetch に流すことで、毎週決まったタイミングに タイトル、日付、DOI、抄録 などの論文情報をまとめて取得できる仕組みが完成します。
3. 要約処理(Summarize contents with LLM)
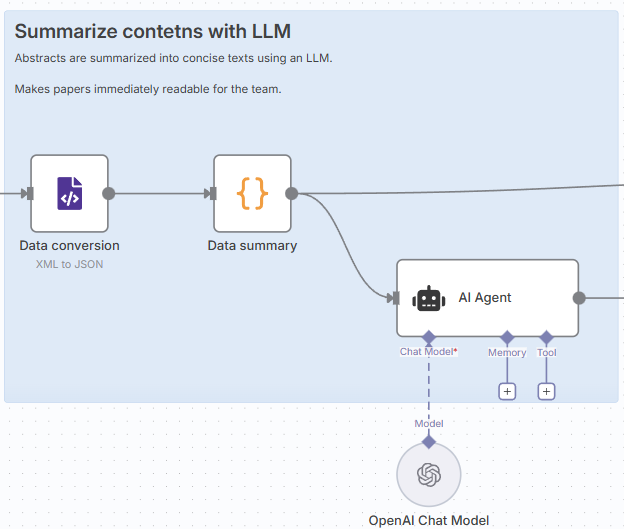
(1) Data conversion(XML → JSON)
- ノード:XML
- 設定例
- Options: Always Output Array → ON
(2) Data summary(抽出)
- ノード:Code
サンプルコード
// --- helper ---
const first = (v) => Array.isArray(v) ? first(v[0]) : v;
const text = (v) => {
if (v == null) return '';
if (typeof v === 'string') return v;
if (typeof v === 'number') return String(v);
if (typeof v === 'object') return text(v._ ?? v['#text'] ?? v.value ?? v.text ?? Object.values(v)[0]);
return String(v);
};
// --- root detection: supports {data.PubmedArticleSet...} or {PubmedArticleSet...} ---
const rootObj = $json?.data?.PubmedArticleSet ?? $json?.PubmedArticleSet;
const articles = rootObj?.PubmedArticle ?? [];
const arr = Array.isArray(articles) ? articles : (articles ? [articles] : []);
// 何もないと n8n は "No output data returned" になるので、ダミーを返す
if (arr.length === 0) {
return [
{ json: { note: 'no articles found', debugRootKeys: Object.keys($json || {}) } }
];
}
const out = arr.map(a => {
const mc = a.MedlineCitation || {};
const art = mc.Article || {};
const pmid = text(mc.PMID);
const title = text(art.ArticleTitle);
// Abstract は段落複数やラベル付きのことがある
let abstract = '';
const abs = art.Abstract?.AbstractText;
if (Array.isArray(abs)) {
abstract = abs.map(x => text(x)).filter(Boolean).join('\n');
} else {
abstract = text(abs);
}
const authSrc = art.AuthorList?.Author || [];
const authArr = Array.isArray(authSrc) ? authSrc : (authSrc ? [authSrc] : []);
const authors = authArr
.map(au => [text(au.ForeName), text(au.LastName)].filter(Boolean).join(' '))
.filter(Boolean)
.join(', ');
const pubDate = art.Journal?.JournalIssue?.PubDate || {};
const pub_date = [text(pubDate.Year), text(pubDate.Month), text(pubDate.Day)]
.filter(Boolean).join('-');
const ids = a.PubmedData?.ArticleIdList?.ArticleId || [];
const idsArr = Array.isArray(ids) ? ids : (ids ? [ids] : []);
const doiObj = idsArr.find(x => (x?.IdType ?? x?.['@_IdType']) === 'doi');
const doi = text(doiObj);
const url = pmid ? `https://pubmed.ncbi.nlm.nih.gov/${pmid}/` : '';
return {
json: {
pmid, title, abstract,
journal: text(art.Journal?.Title),
pub_date, authors, doi, url
}
};
});
return out;
(3) LLMによる要約
- ノード:OpenAI Chat Model
- プロンプト例
- Prompt (User Message)
次のPubMed論文を150~220字で日本語要約してください。
必ず「目的 / 方法 / 主な結果 / 含意」を短く含め、数値はあれば保持。最後に【タグ】を1~2語(例:T2DM、合併症、介入)で付与。
タイトル: {{$json.title}}
抄録: {{ $json.abstract }}
雑誌: {{$json.journal}}
発行日: {{$json.pub_date}}
URL: {{$json.url}}
System Message
あなたは医学論文の抄読支援者です。
出力は必ず日本語。誇張せず事実ベースで要約し、曖昧な点は「不明」と書く。
記載のない情報を推測しない。
4. データ整理(Data organization)
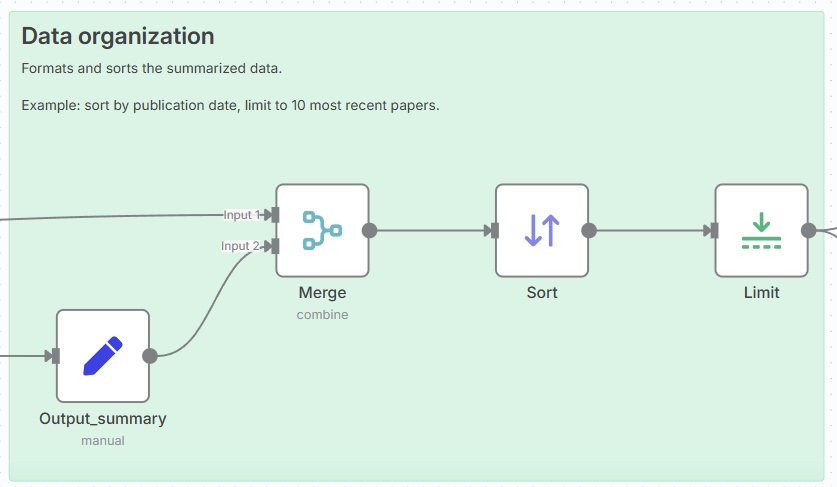
(1) Merge
- 目的:タイトル+要約を結合。
(2) Sort
- 設定例
- Field: date
- Order: Descending
(3) Limit
- 設定例
- Max Items: 10
5. 出力(Output)
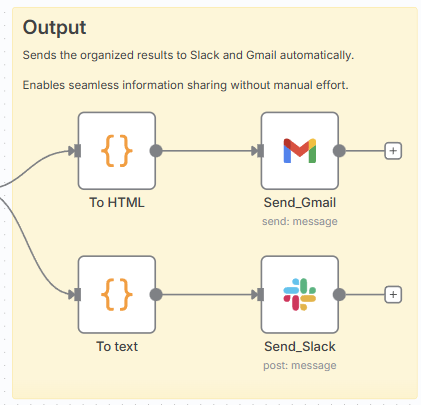
(1) To HTML(メール用)
// 各アイテム: pmid, title, abstract, journal, pub_date, authors, doi, url, summary_ja
const items = $input.all();
function esc(s=''){ return String(s)
.replace(/&/g,'&').replace(/</g,'<').replace(/>/g,'>'); }
const today = (new Date()).toISOString().slice(0,10);
let html = `
<h2>週間PubMed要約(糖尿病) - ${today}</h2>
<p>直近7日間にヒットした論文の要約です(自動生成)。原文と不一致があれば原著を優先してください。</p>
<ol>
`;
for (const it of items) {
const j = it.json;
html += `
<li style="margin-bottom:16px;">
<div><a href="${esc(j.url)}" target="_blank"><strong>${esc(j.title)}</strong></a></div>
<div style="font-size:90%;color:#555;">
${esc(j.journal || '')} ${esc(j.pub_date || '')}
${j.authors ? ' 著者: ' + esc(j.authors) : ''}
${j.doi ? ' DOI: ' + esc(j.doi) : ''}
</div>
<div style="margin-top:6px; white-space:pre-wrap;">${(j.summary_ja || '').trim()}</div>
</li>`;
}
html += `</ol>`;
return [{ json: { html } }];
(2) Gmail送信
- 設定例
- 宛先 (To):team@company.com(任意の配信先アドレス)
- Subject:PubMed Weekly Report
- Email Type:HTML
- Message (本文):{{ $json[“html”] }}(直前ノードで生成されたHTMLを本文として送信)
- Resource:Message
- Operation:Send
- 特徴:PubMed要約をメール形式で配信可能。HTML指定により見やすいフォーマットで送信できる。
(3) Slack送信
- 設定例
- 認証:Slackアカウントを接続
- Resource:Message
- Operation:Send
- 送信先:Channel(例:ai_experiment)
- メッセージタイプ:Simple Text Message
- メッセージ本文:{{ $json.text }}(直前ノードで生成されたテキストを送信)
- 特徴:PubMed要約などを自動でSlackチャンネルに配信可能

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら
")
")
")