")
Part4. スプレッドシートにデータを格納する
| 目次 |
1. はじめに
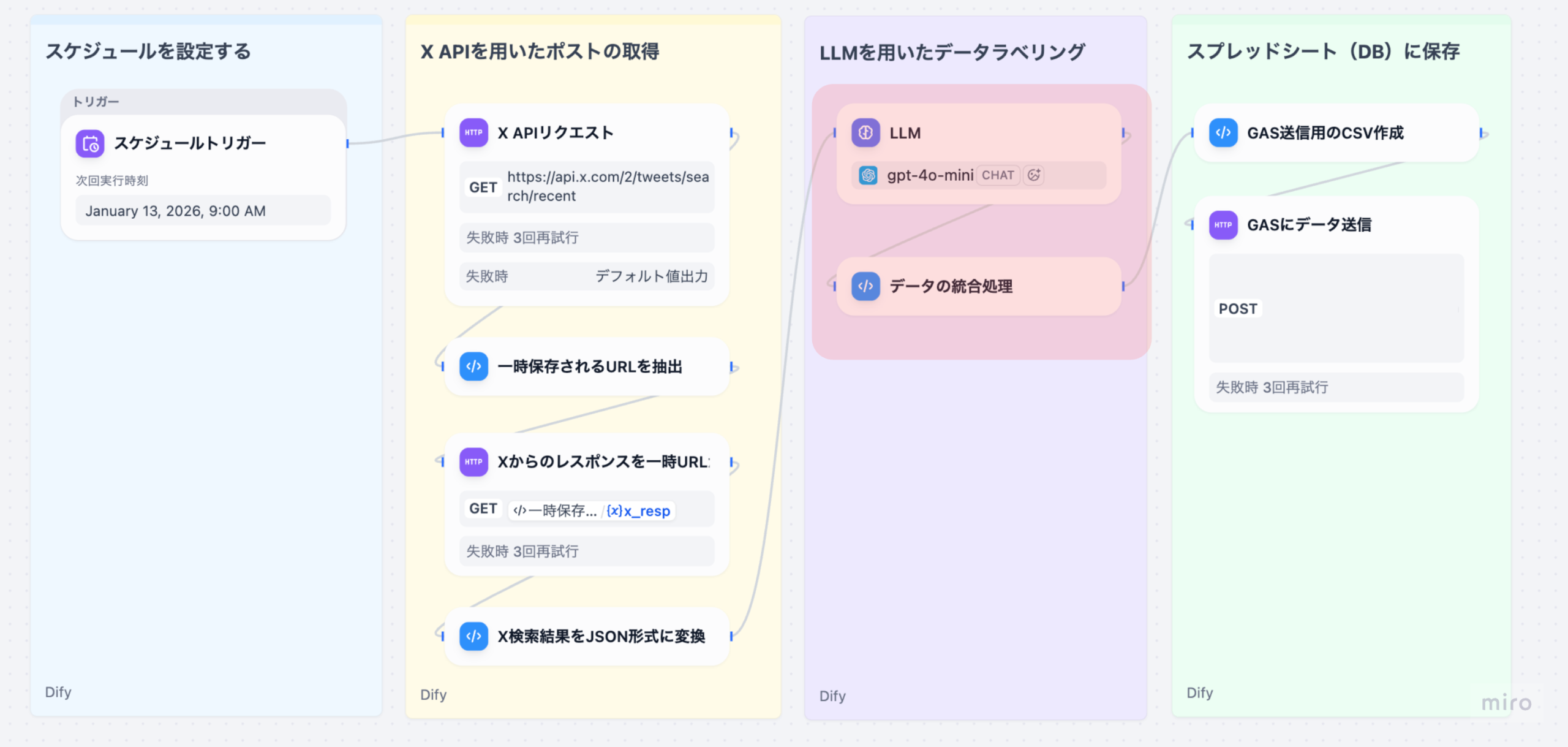
本記事は、Difyのワークフローを使って、X(旧Twitter)のソーシャルリスニングを⾃動化するシリーズのPart 4です。
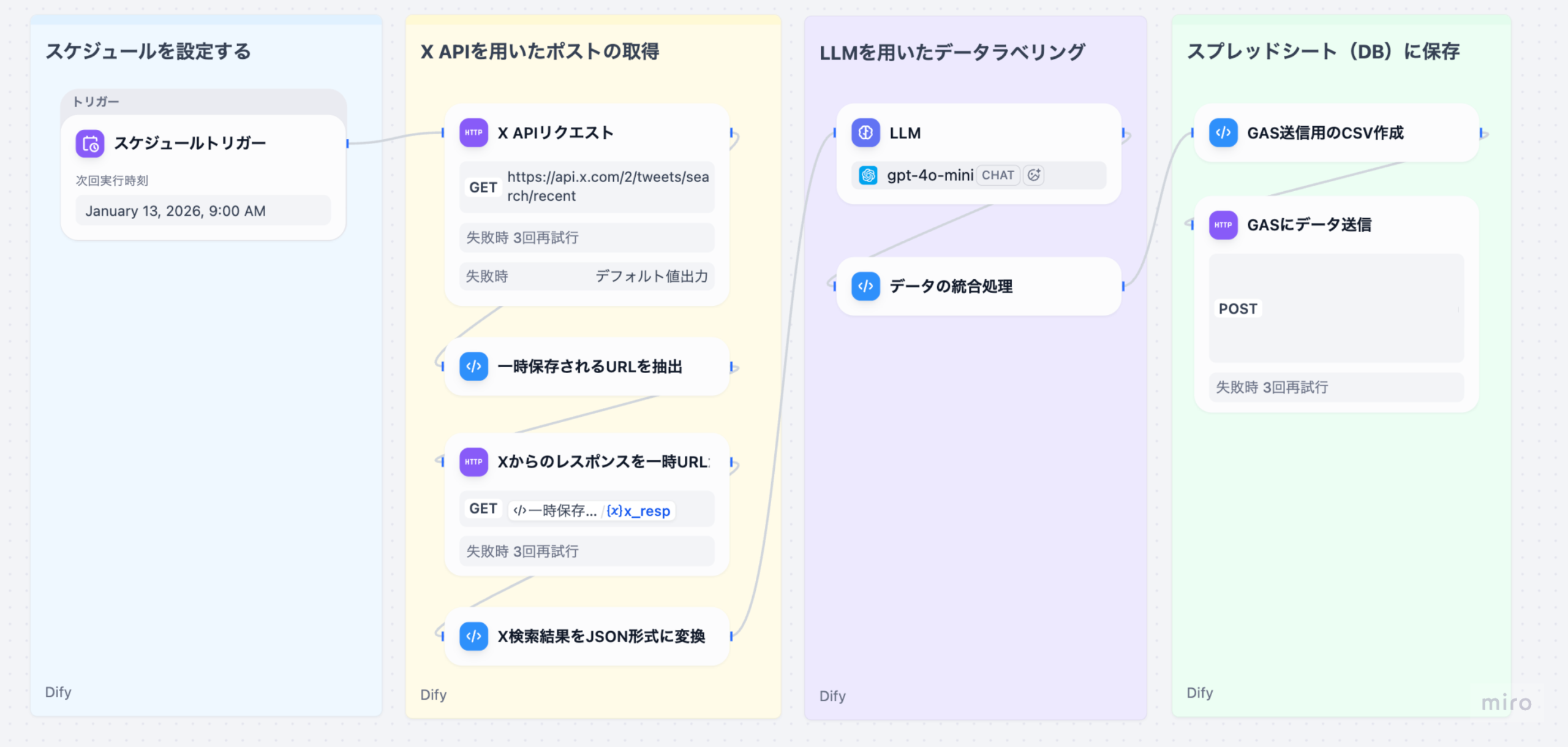
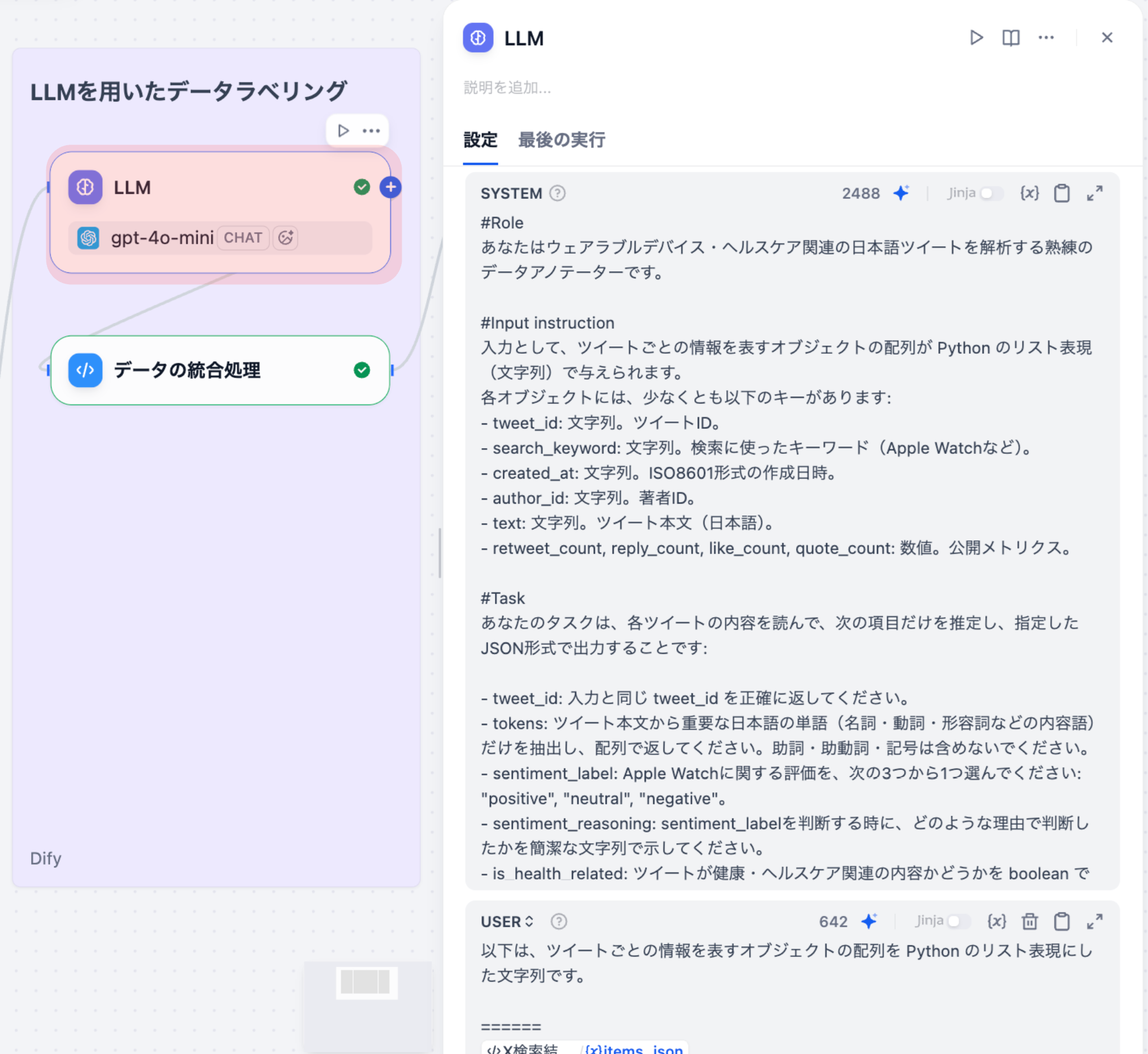
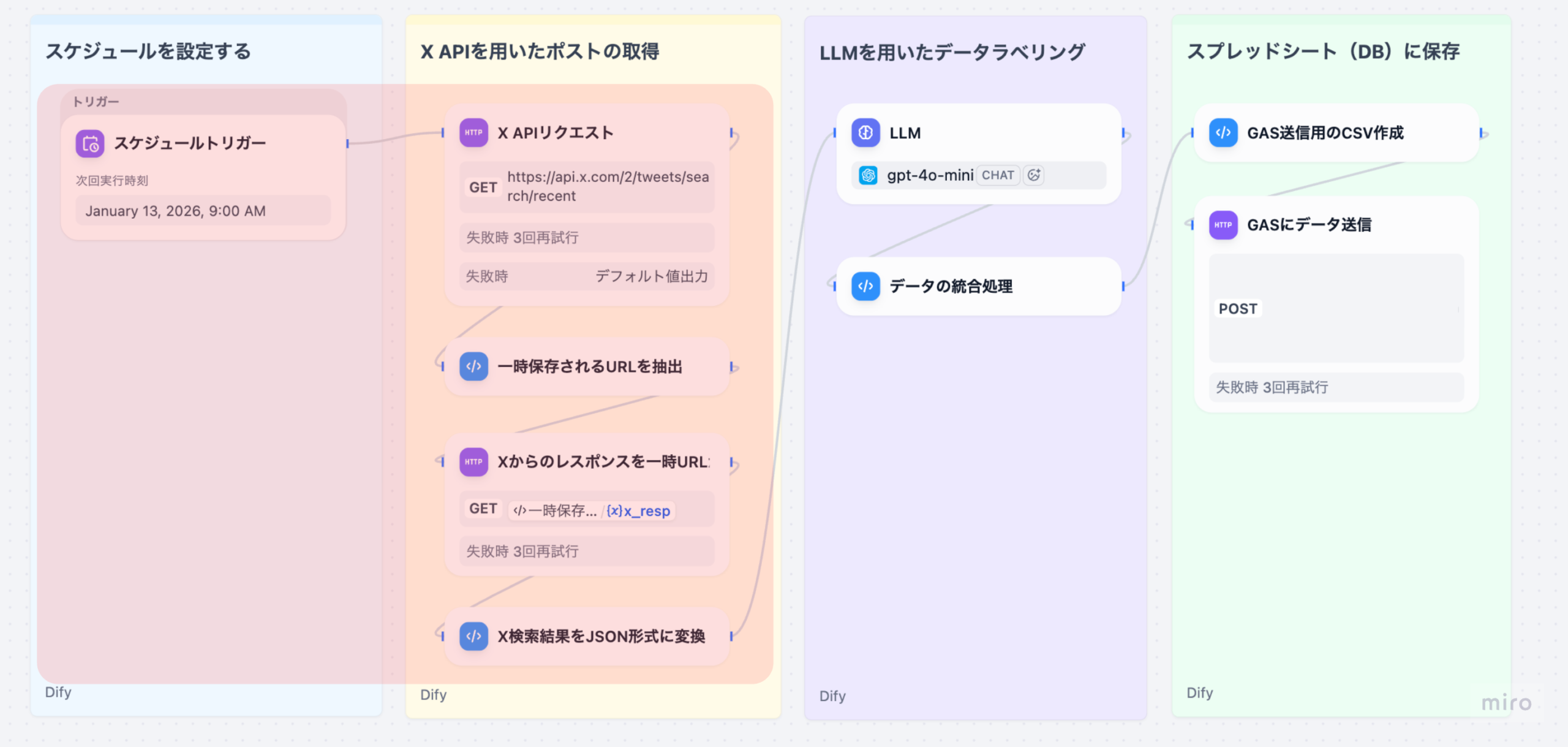
Part 3の復習: 前回の記事では、取得したツイートデータに対してLLMで感情ラベル付与、健康関連性の判定、カテゴリ分類、健康トピック • デバイストピックの抽出を⾏い、元データと統合する処理を解説しました。具体的には、以下のノードを実装しました。
- LLM処理(感情ラベル判定 • 健康関連性判定 • カテゴリ分類 • トピック抽出)
- データ統合(LLM結果と元データのマージ)
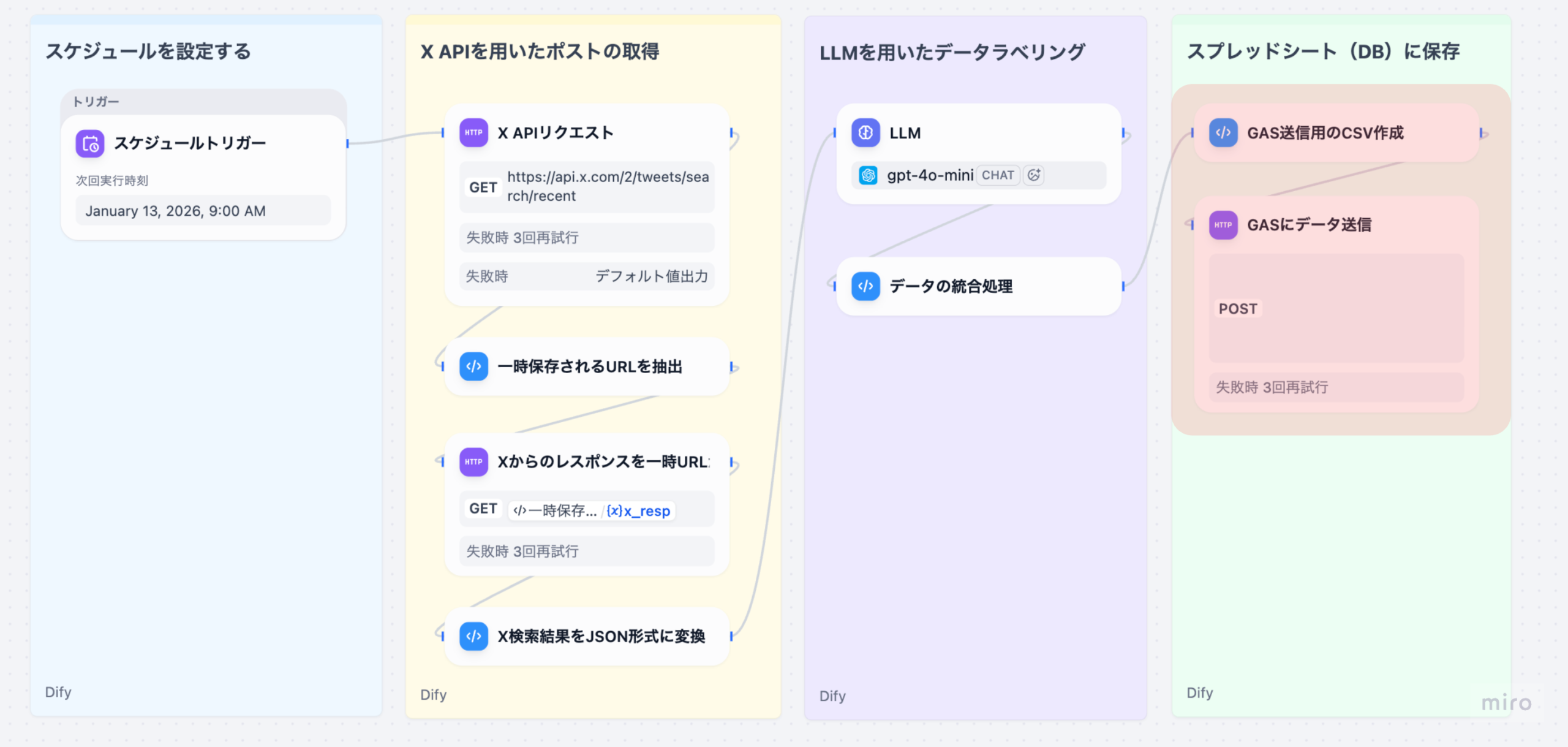
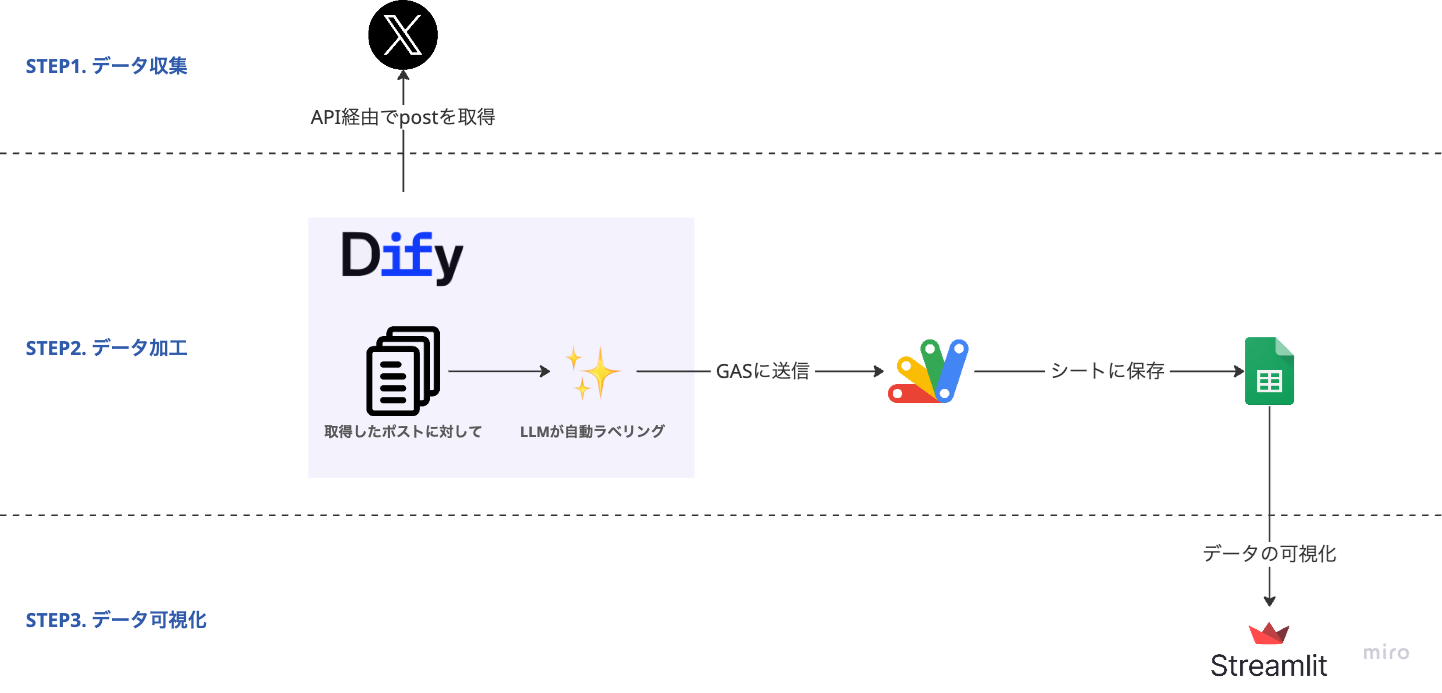
Part 4(本記事)では、統合したデータをCSV形式に変換し、Google Apps Script(GAS)に送信してスプレッドシートに保存する処理を詳しく解説します。これにより、ユーザーはスプレッドシートで分析結果を確認できるようになります。
シリーズ構成
- Part 0: X APIを⽤いたソーシャルリスニング概要
- Part 1: X 旧Twitter) APIの基礎
- Part2: Difyを⽤いてX APIから直近のポストを取得する
- Part 3: LLMを⽤いて⾃動でデータラベルを付与する
- Part 4(本記事): スプレッドシートにデータを格納する
- Part 5: Streamlitを⽤いたデータの可視化例
2. Part 3からの流れ
Part 3で統合したデータは、以下のような構造になっています。
{
"data": [
{
"tweet_id": "1234567890",
"search_keyword": "Apple Watch",
"created_at": "2025-01-14T12:00:00.000Z",
"author_id": "987654321",
"text": "Apple Watchの心拍数と睡眠トラッキングが便利...",
"retweet_count": 10,
"reply_count": 5,
"like_count": 20,
"quote_count": 2,
"sentiment_label": "positive",
"sentiment_reasoning": "健康管理機能への満足度が高い内容",
"is_health_related": true,
"category": "health_monitoring",
"health_topics": ["心拍モニタリング", "睡眠トラッキング"],
"device_topics": ["バッテリー寿命"],
"tokens": ["Apple Watch", "心拍数", "睡眠トラッキング"],
"post_url": "<https://x.com/i/web/status/1234567890>"
}
],
"meta": {
"result_count": 20
}
}
本記事では、この統合データに対して、以下の処理を⾏います。
- CSV形式への変換(カラム定義、データ整形)
- GASへのHTTPリクエスト(POST, JSON形式)
- スプレッドシートへの⾃動保存
3. 各ノードの詳細解説
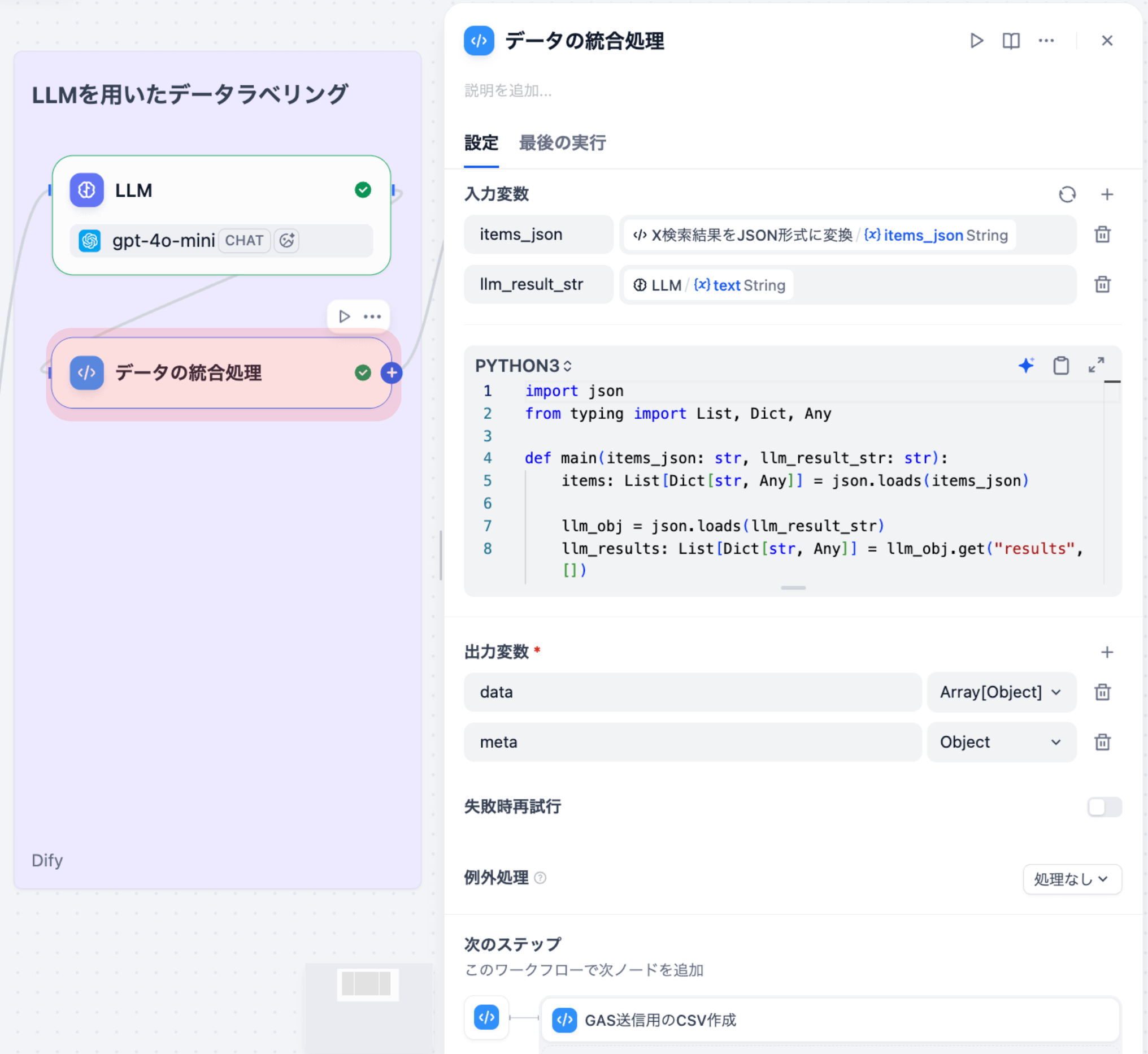
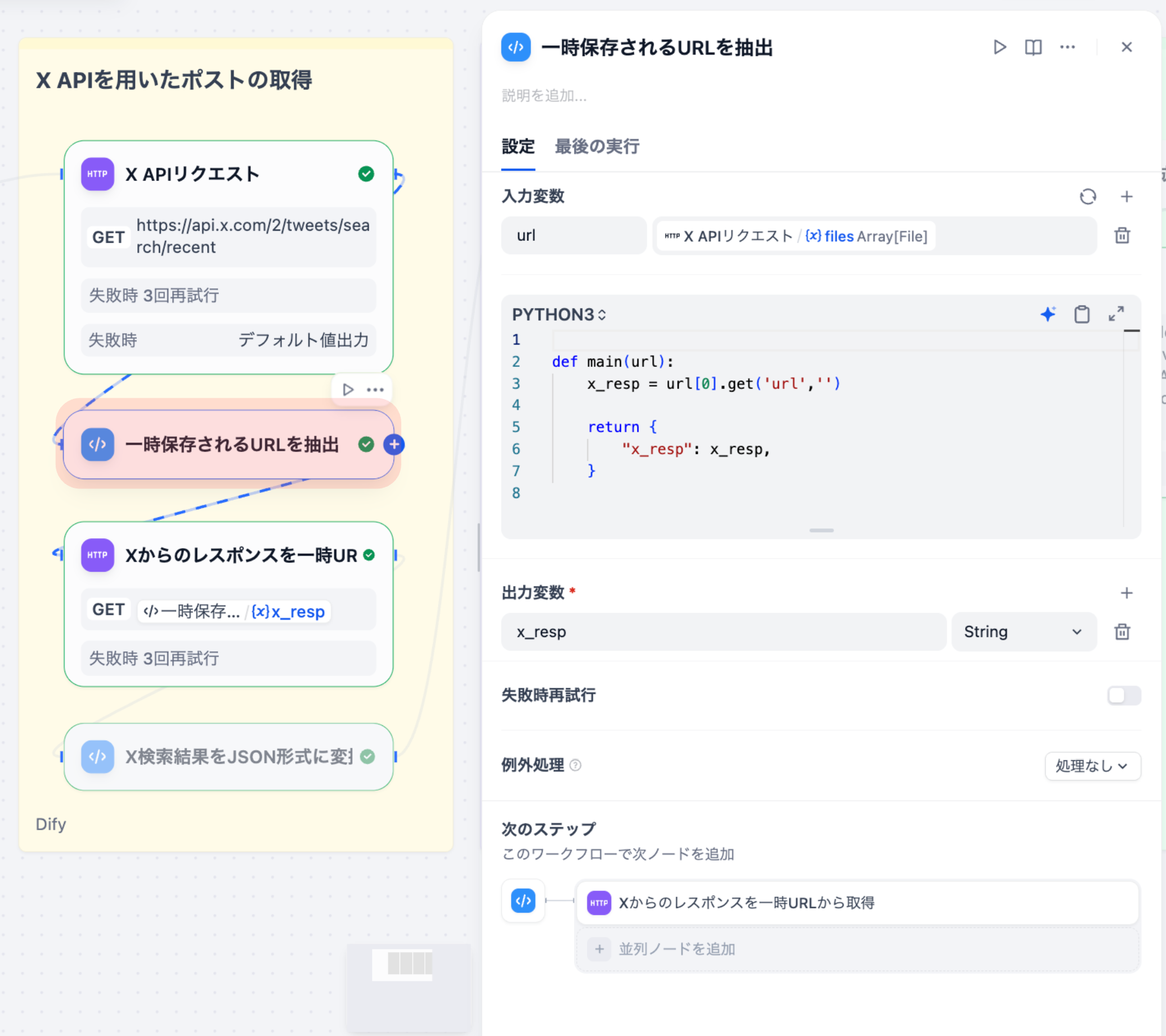
3-1. GAS送信⽤のCSV作成(Codeノード)
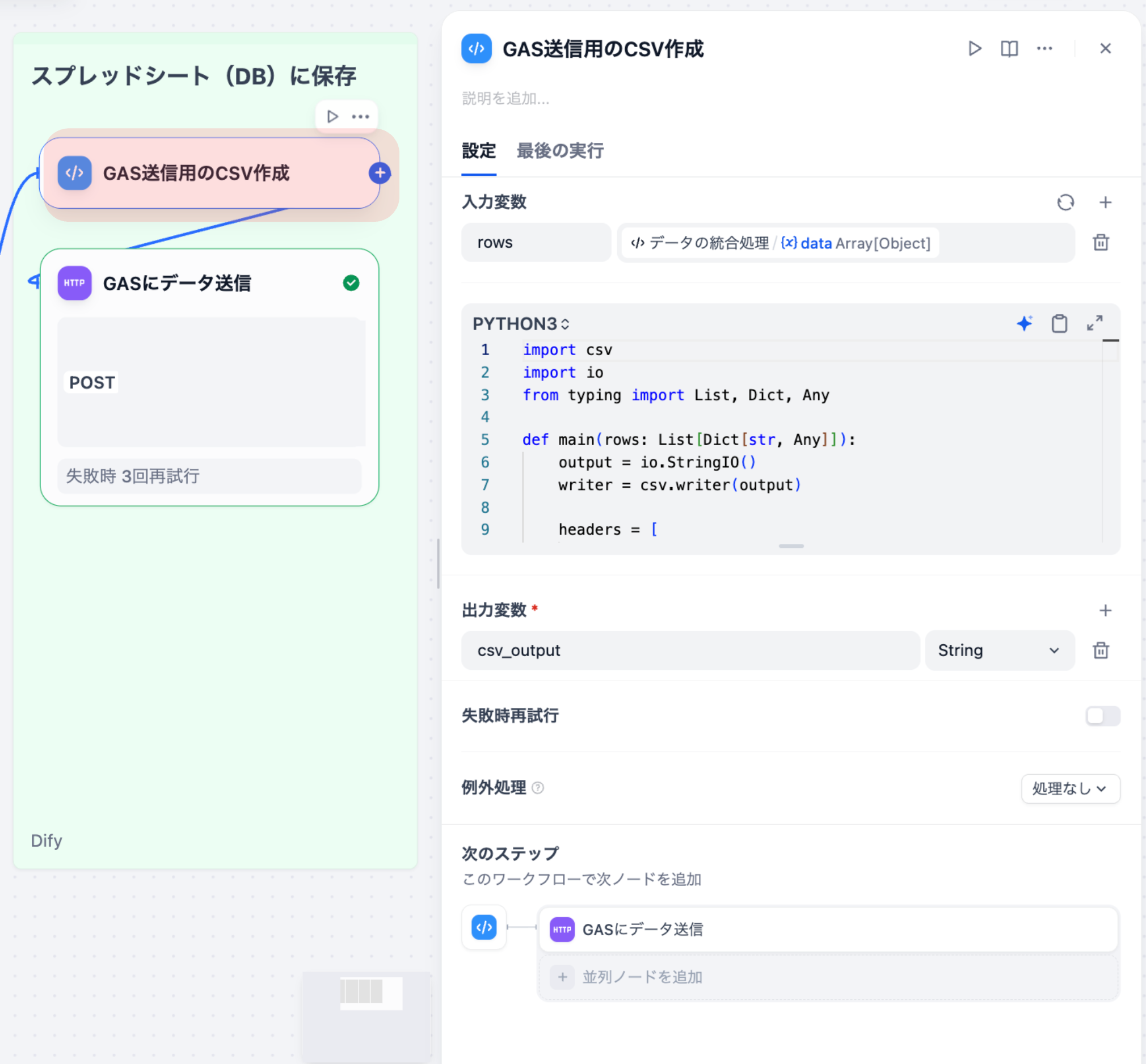
統合済みのツイートデータを、Google Apps Script(GAS)に送信するためのCSV形式に変換するノードです。
⼊⼒変数
| 変数名 | ソース | 型 |
|---|---|---|
| rows | データ統合ノード | array[object] |
コード
import csv
import io
from typing import List, Dict, Any
def main(rows: List[Dict[str, Any]]):
# CSV出力用のStringIOオブジェクトを作成
output = io.StringIO()
writer = csv.writer(output)
# CSVのヘッダー行を定義
headers = [
"tweet_id",
"search_keyword",
"created_at",
"author_id",
"text",
"retweet_count",
"reply_count",
"like_count",
"quote_count",
"post_url",
"sentiment_label",
"sentiment_reasoning",
"is_health_related",
"category",
"health_topics",
"device_topics",
"tokens",
]
writer.writerow(headers)
# 各ツイートデータをCSV行に変換
for row in rows:
# adverse_eventsは配列なので、パイプ区切り文字列に変換
adverse_events = row.get("adverse_events") or []
if isinstance(adverse_events, list):
adverse_events_str = "|".join(adverse_events)
else:
adverse_events_str = str(adverse_events)
# tokensも配列なので、パイプ区切り文字列に変換
tokens = row.get("tokens") or []
if isinstance(tokens, list):
tokens_str = "|".join(tokens)
else:
tokens_str = str(tokens)
# テキスト内の改行をスペースに置換(CSVの可読性向上)
text = row.get("text", "")
text = text.replace("\\n", " ")
# CSV行を生成
writer.writerow([
row.get("tweet_id", ""),
row.get("search_keyword", ""),
row.get("created_at", ""),
row.get("author_id", ""),
text,
row.get("retweet_count", 0),
row.get("reply_count", 0),
row.get("like_count", 0),
row.get("quote_count", 0),
row.get("post_url", ""),
row.get("sentiment_label", "") or "",
row.get("sentiment_reasoning", "") or "",
row.get("is_health_related", "") or "",
row.get("category", "") or "",
health_topics_str,
device_topics_str,
tokens_str,
])
# CSV文字列を取得
csv_string = output.getvalue()
output.close()
return {
"csv_output": csv_string
}
処理の流れ
- CSV出⼒準備: io.StringIO() でメモリ上にCSV出⼒⽤のバッファを作成
- ヘッダー⾏の⽣成: 19個のカラムを定義(tweet_id, search_keyword, created_at等)
- データ⾏の⽣成: 各ツイートデータに対して:
- adverse_events 配列をパイプ区切り⽂字列( \| )に変換(例: “発熱\|倦怠感” )
- tokens 配列もパイプ区切り⽂字列に変換
- テキスト内の改⾏( \\\\n )をスペースに置換(CSVの可読性向上)
- 各フィールドを取得し、デフォルト値を設定
- CSV⽂字列の取得: getvalue() でCSV⽂字列を取得する
CSVカラム構成
| カラム名 | 説明 | データソース |
|---|---|---|
| tweet_id | ツイートID | Xから取得される元データ |
| search_keyword | 検索キーワード | Xから取得される元データ |
| created_at | 作成⽇時 | Xから取得される元データ |
| author_id | 著者ID | Xから取得される元データ |
| text | ツイート本⽂ | Xから取得される元データ |
| retweet_count | リツイート数 | Xから取得される元データ |
| reply_count | リプライ数 | Xから取得される元データ |
| like_count | いいね数 | Xから取得される元データ |
| quote_count | 引⽤ツイート数 | Xから取得される元データ |
| post_url | ツイートURL | ⽣成( https://x.com/i/web/status/{tweet_id} ) |
| sentiment_label | 感情ラベル | LLM抽出結果 |
| sentiment_reasoning | 感情判断の理由 | LLM抽出結果 |
| is_health_related | 健康 • ヘルスケア関連かどうか | LLM抽出結果 |
| category | ツイートのメインカテゴリ | LLM抽出結果 |
| health_topics | 健康トピック(パイプ区切り) | LLM抽出結果 |
| device_topics | デバイストピック(パイプ区切り) | LLM抽出結果 |
| tokens | 重要な単語(パイプ区切り) | LLM抽出結果 |
データ整形のポイント
- 配列の処理: tokens は配列なので、パイプ区切り( \| )で結合(例: “発熱\|倦怠感” )
- 改⾏の処理: テキスト内の改⾏( \\\\n )をスペースに置換(CSVの可読性向上)
- デフォルト値: 各フィールドにデフォルト値を設定(空⽂字列、0等)
出⼒例
tweet_id,search_keyword,created_at,author_id,text,retweet_count,reply_count,like_count,quote_count,po st_url,sentiment_label,sentiment_reasoning,is_health_related,category,health_topics,device_topics,tok ens 1234567890,Apple Watch,2025-01-14T12:00:00.000Z,987654321,Apple Watchの心拍数と睡眠トラッキングが便利...,10,5,20,2,<https://x.com/i/web/status/1234567890,positive,健康管理機能への満足度が高い内容,true,health_moni toring,心拍モニタリング|睡眠トラッキング,バッテリー寿命,Apple Watch|心拍数|睡眠トラッキング
出⼒
| 出⼒名 | 型 | 説明 |
|---|---|---|
| csv_output | string | CSV形式の⽂字列 |
3-2. GASにデータ送信(HTTP Requestノード)
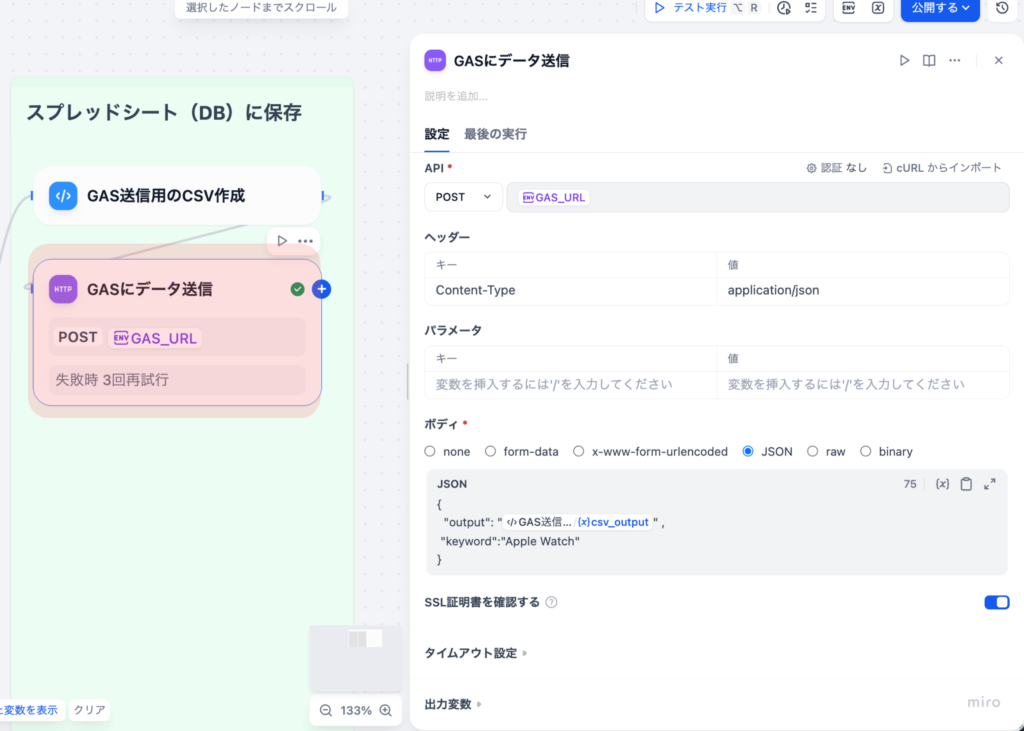
⽣成したCSVデータをGoogle Apps Script(GAS)のWebアプリに送信するノードです。
設定内容
| 項⽬ | 設定値 |
|---|---|
| メソッド | POST |
| URL | https://script.google.com/macros/s/…/exec |
| 認証 | なし |
| ヘッダー | Content-Type:application/json |
リクエストボディ
{
"output": "#csv_output#",
"keyword": "Apple Watch"
}
- output : CSV⽂字列(前のノードから取得)
- keyword : 検索キーワード(固定値または環境変数から取得)
Google Apps Scriptとは?
Google Apps Script(GAS)は、Googleが提供するクラウドベースのJavaScript実⾏環境で、Google Workspace(スプレッドシート、ドライブ、メール、カレンダーなど)を⾃動化 • 拡張するために設計されたプラットフォームです。ブラウザ上のエディタだけで完結し、インフラ構築やサーバ管理なしでスクリプトを動かせるため、「ちょっとした業務⾃動化」から「⼩さな業務システム」までを素早く⽴ち上げられる点が特徴です。
GAS Webアプリの作成⽅法(参考)
- Google Apps Scriptエディタを開く: https://script.google.com/
- 新しいプロジェクトを作成
- 以下のようなコードを記述:
function doPost(e) {
try {
const data = JSON.parse(e.postData.contents);
const csvString = data.output;
const keyword = data.keyword;
// スプレッドシートを取得または作成
const spreadsheet = SpreadsheetApp.getActiveSpreadsheet() ||
SpreadsheetApp.create('ソーシャルリスニング結果');
const sheet = spreadsheet.getActiveSheet() ||
spreadsheet.insertSheet('データ');
// CSVをパースしてスプレッドシートに追記
const rows = Utilities.parseCsv(csvString);
sheet.getRange(sheet.getLastRow() + 1, 1, rows.length, rows[0].length)
.setValues(rows);
return ContentService.createTextOutput(JSON.stringify({
status: 'success',
message: 'Data appended successfully',
spreadsheet_url: spreadsheet.getUrl()
})).setMimeType(ContentService.MimeType.JSON);
} catch (error) {
return ContentService.createTextOutput(JSON.stringify({
status: 'error',
message: error.toString()
})).setMimeType(ContentService.MimeType.JSON);
}
}
Webアプリとしてデプロイ:
- 「デプロイ」→「新しいデプロイ」を選択種類: 「ウェブアプリ」を選択
- アクセス権限: 「全員」を選択
- 「デプロイ」をクリック
- 表⽰されたURLをコピー(これがHTTP RequestノードのURLになります)
レスポンス例
{
"status": "success",
"message": "Data appended successfully",
"spreadsheet_url": "<https://docs.google.com/spreadsheets/d/>..."
}
エラーハンドリング
GAS側でエラーが発⽣した場合、以下のようなレスポンスが返されます。
{
"status": "error",
"message": "Error message here"
}
Dify側では、このレスポンスを確認し、必要に応じてエラーログを記録する処理を追加できます。
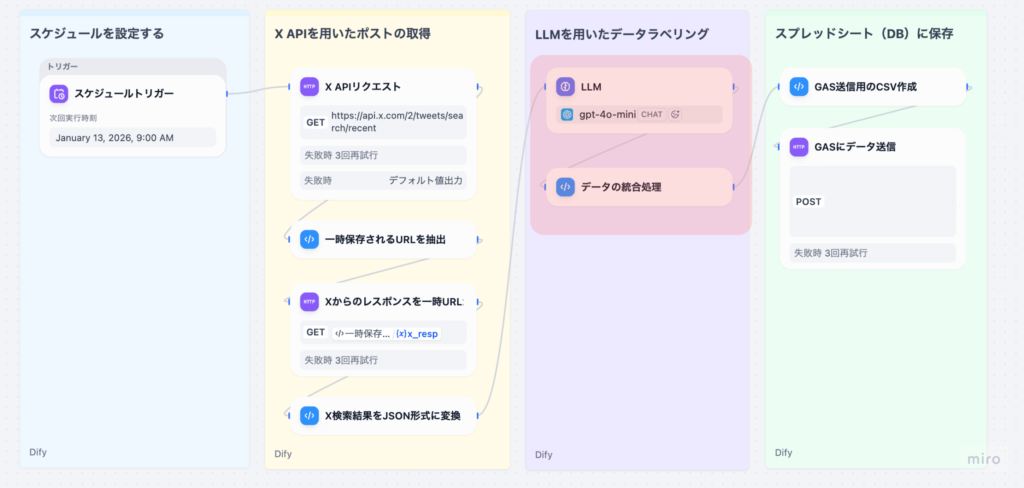
4. ワークフローの完成
ここまでで、ソーシャルリスニングワークフローの主要な処理が完成しました。
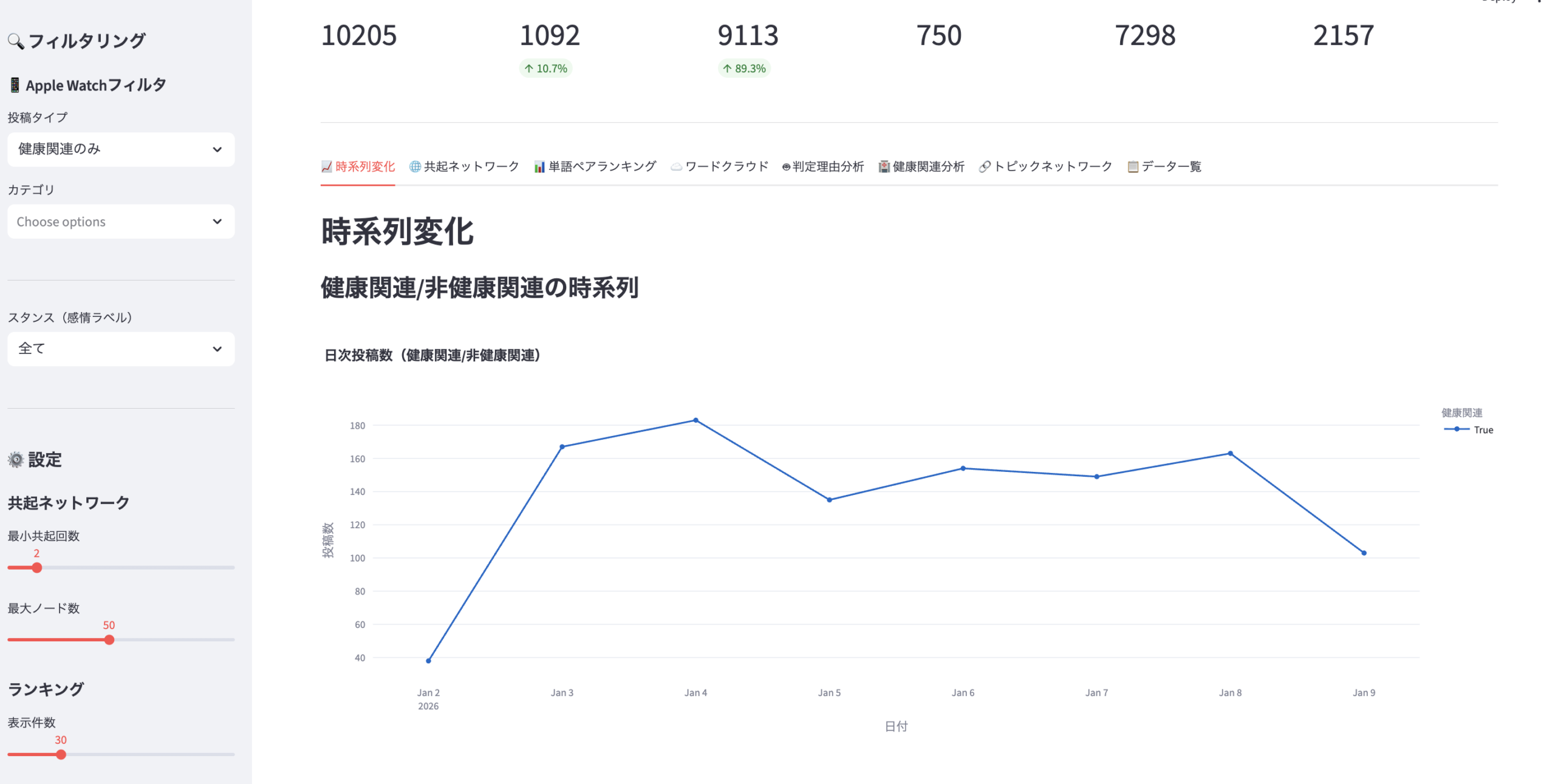
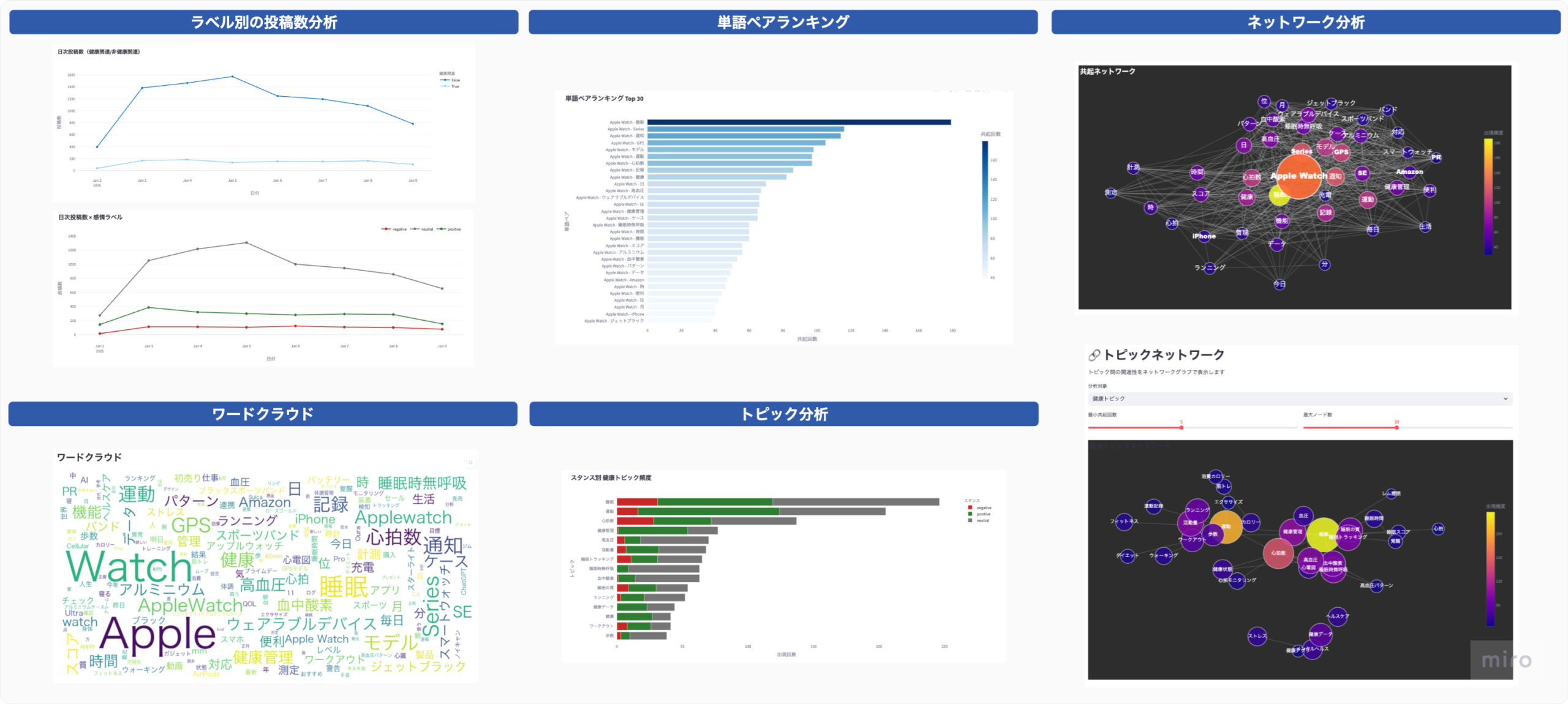
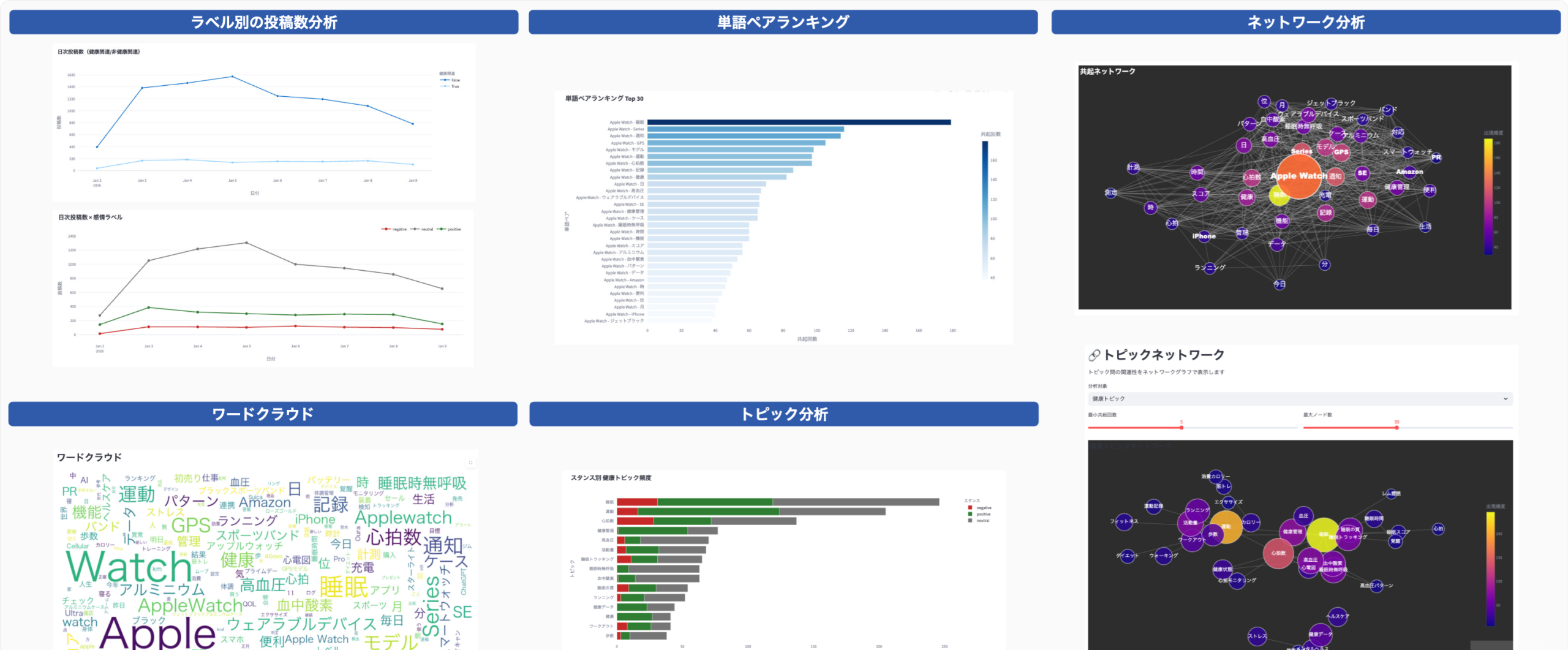
スプレッドシートをデータベース代わりに利⽤しているため、以下のようにデータが蓄積されます。
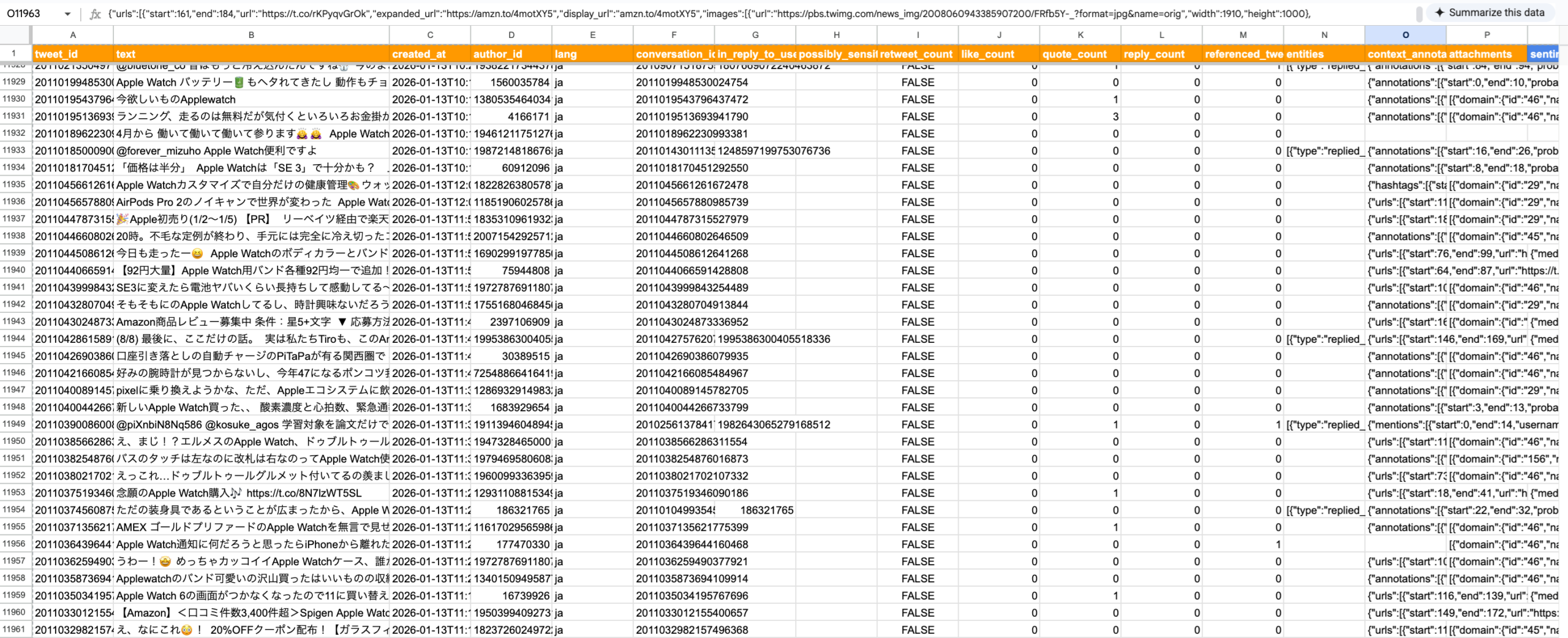
5. まとめ
本記事(Part 4)では、統合したデータをCSV形式に変換し、Google Apps Script(GAS)に送信してスプレッドシートに保存する処理を詳しく解説しました。
本記事で実現したこと
- CSV形式への変換処理(カラム定義、データ整形)
- GASへのHTTPリクエスト(POST, JSON形式)
- スプレッドシートへの⾃動保存
- エラーハンドリングとレスポンス処理
処理の流れの確認
- CSV作成: 統合済みデータをCSV形式に変換(配列の処理、改⾏の処理等)
- GAS送信: Google Apps ScriptのWebアプリにPOSTリクエストで送信
- スプレッドシート保存: GAS側でCSVをパースしてスプレッドシートに追記
シリーズ全体のまとめ
本シリーズ(Part 2〜4)では、Difyのワークフローを使って、X(旧Twitter)のソーシャルリスニングを⾃動化するシステムを構築しました。
- Part 2: DifyのワークフローでX APIからツイートを取得し、構造化データに変換
- Part 3: LLMによる感情判定 • カテゴリ分析と、データ統合処理
- Part 4: CSV形式への変換と、Google Apps Scriptへの送信 • スプレッドシート保存
これらの処理により、ツイートを取得 • 分析 • 保存するシステムが完成しました。
次のPart5ではこのStreamlitデータを⽤いたデータの可視化⽅法を解説します。企業におけるX投稿データの利⽤例として使える、現実的なサンプルを⽤意しています。
シリーズ構成
- Part 0: X APIを用いたソーシャルリスニング概要
- Part 1: X(旧Twitter) APIの基礎
- Part 2: Difyを用いてX APIから直近のポストを取得する
- Part 3: LLMを用いて自動でデータラベルを付与する
- Part 4(本記事): スプレッドシートにデータを格納する
- Part 5: Streamlitを用いたデータの可視化例(次の記事)

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら

監修者 株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中
")
")
")