")
Difyエージェントで加速するドラッグ・リポジショニング:文献からの候補探索シナリオ
Difyエージェントで加速するドラッグ・リポジショニング:文献からの候補探索シナリオ
新規創薬に要する期間は10年超、費用は数百億から数千億円にのぼるとされ、そのハイリスク・ハイリターンな構造が大きな課題となっています。こうした背景から、既存薬の新たな薬効を見出すドラッグ・リポジショニング(DR)が注目されていますが、その成功の鍵を握る「膨大な文献からの知識抽出」は、従来の人の手による作業では限界に達しています。
本記事では、AI開発プラットフォームDifyのエージェント機能、特にRAG(Retrieval-Augmented Generation)の応用に着目し、いかにしてこのAIエージェントが、DRの初期フェーズである「文献からの候補探索」を劇的に効率化するかを、具体的なシナリオとメカニズムを交えてプロフェッショナルな視点から解説します。
1. AIエージェントが創薬の「探索フェーズ」を革新する
Difyのエージェント機能は、大規模言語モデル(LLM)と外部知識ベースを連携させるRAG(検索拡張生成)の仕組みを容易に構築できます。この技術を医学・薬学分野に応用することで、ドラッグ・リポジショニング(DR)の最も時間のかかるフェーズである「候補薬の探索」を根本から変革することが可能です。従来のDRは、研究員の知識や偶発的な発見(セレンディピティ)に依存することが多く、網羅性や客観性に課題がありました。
AIエージェントは、PubChem、MEDLINE、PubMed Centralなどの数千万報に及ぶ論文やデータベースを学習データとして取り込み、特定の疾患(例:アルツハイマー病)と、既存薬の副作用・薬理作用、関連する遺伝子変異との間の潜在的な関係性を、人間では見落としがちな微細な文脈から自動で抽出します。これにより、従来のキーワード検索では不可能だった、バイアスのない客観的な候補リストを短期間で生成する「発見型概念検索」が実現します。
2. 新薬開発の常識を覆すDRのメリットと構造的課題
ドラッグ・リポジショニング(DR)の最大の魅力は、開発期間と費用の劇的な短縮です。新規創薬で必須となる非臨床試験や初期の臨床試験(第I相)の一部を、既存の安全性データに基づいて省略できるため、開発期間を数年単位で短縮できる可能性があります。 特に、有効な治療法が確立されていない難治性疾患や希少疾患への迅速な治療提供に大きな期待が寄せられています。
- 開発期間の約30%短縮(推定)
- 臨床試験の初期リスクが大幅に低減
- 既にヒトでの安全性が確認済み
- 新しい用法・用量での安全性再評価
- 物質特許切れ後の知財戦略の確立
- 既存薬の薬価を基準とする収益性の問題
しかし、DRには構造的な課題も存在します。例えば、新たな適応を取得しても、日本国内では既存の適応症の薬価が基準となるため、十分な収益を確保できないリスクがあります。また、投与条件や対象患者が変わることで、既知の副作用情報が適用できず、新たなリスクが顕在化する可能性も無視できません。
3. Difyエージェントが担う「知識抽出」のメカニズム
具体的には、AIは文献のテキストデータから、特定のタンパク質発現の変動、薬剤のオフターゲット効果(主作用以外の効果)、病態メカニズムとの関連性など、創薬ターゲット探索に必要な要素を抽出し、それらの論理的な繋がりをマッピングします。アステラス製薬の事例でも、AIを活用して文献情報から病態メカニズムの理解を深める試みが紹介されており、このアプローチの有用性が示されています。
従来のキーワード検索では、研究者の先入観や知識の範囲内でしか情報が見つかりませんでしたが、AIエージェントは、疾患、薬剤、遺伝子変異、アウトカム指標などの医療用語間の隠れた関係性をコンセプトレベルで検索・抽出します。これにより、研究員の知識内での作業になってしまうというDRの課題を克服します。
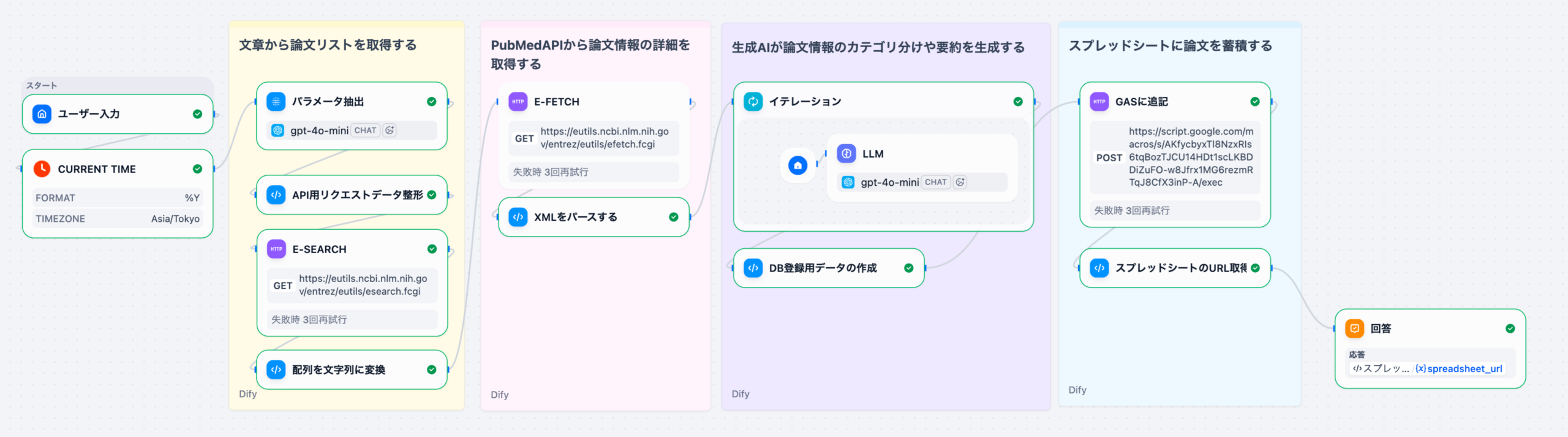
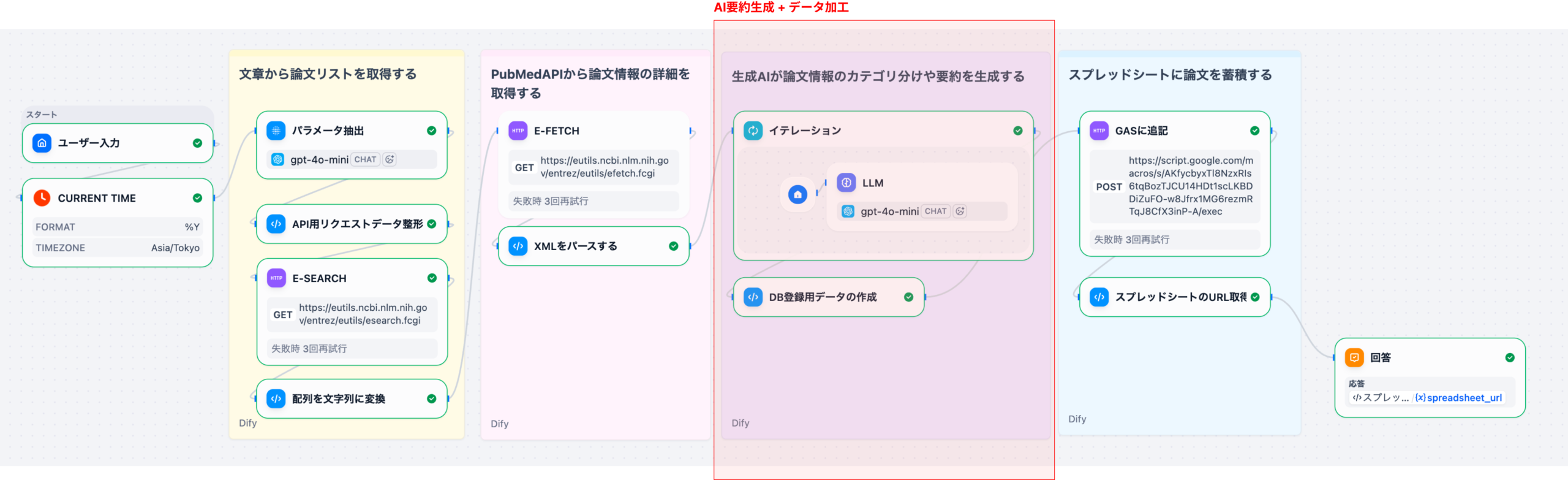
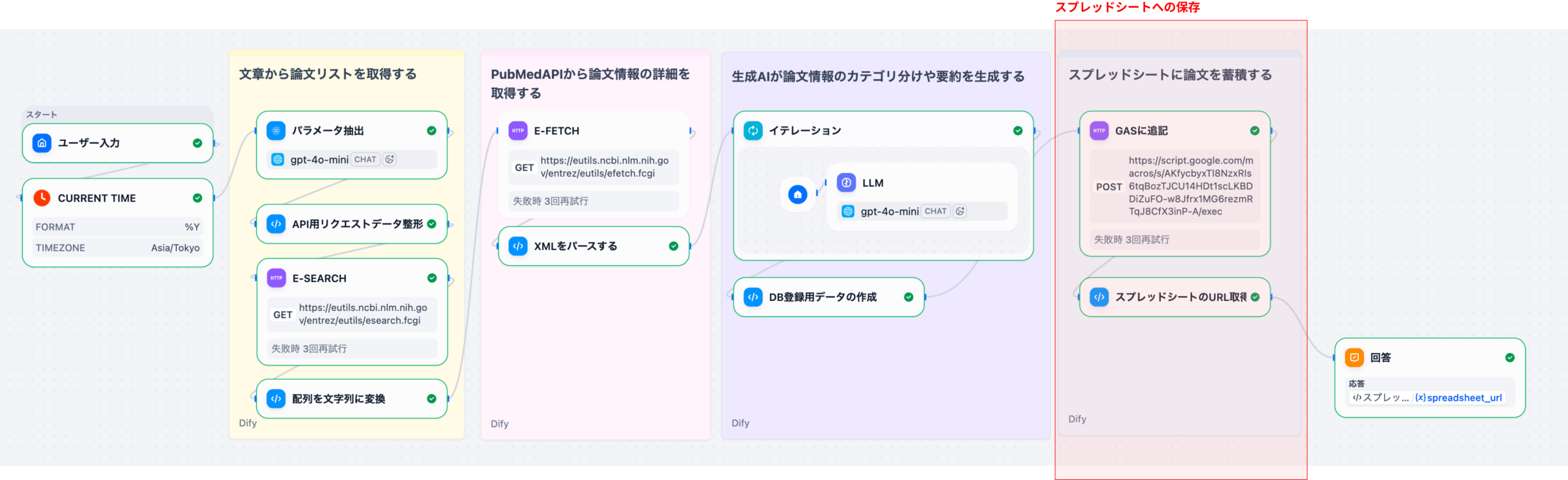
4. 文献からの候補探索シナリオ:具体的な5つのステップ
Difyエージェント機能を用いたドラッグ・リポジショニングの候補探索は、以下の5つのステップで実行されます。これは、膨大な文献データ(例えば、PubMedの3000万報以上の論文)から、創薬標的を効率的に解析し、客観的な仮説を生成するためのプロセスです。
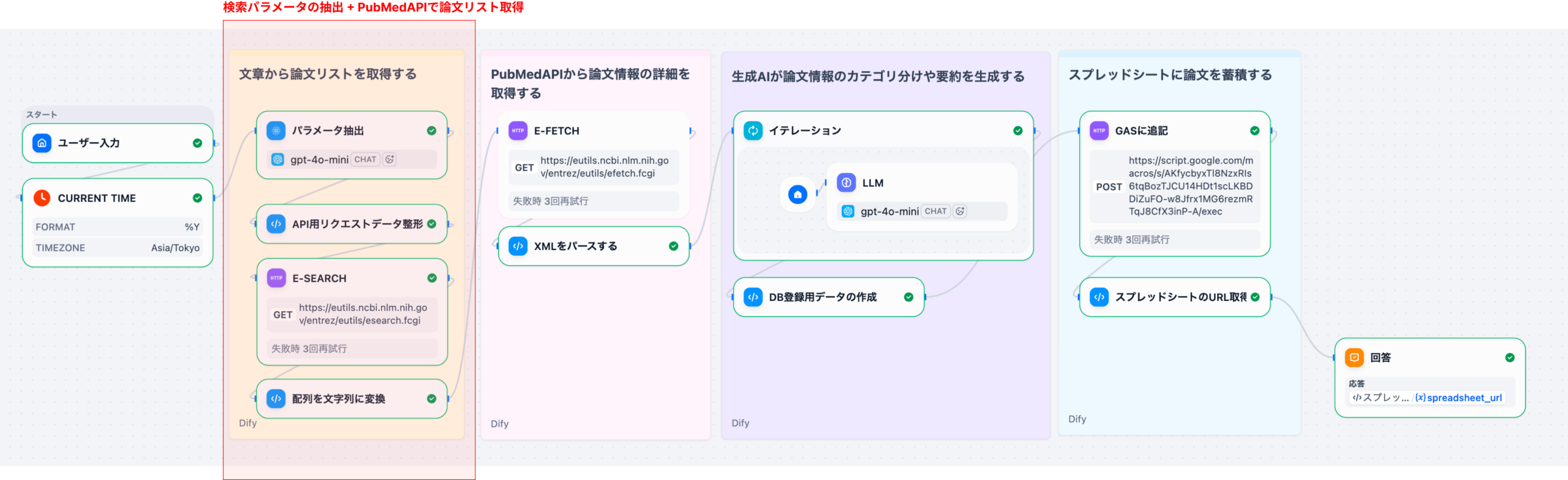
最新の医学・薬学論文、治験データ、特許情報などをDifyの知識ベースにアップロードし、ベクトル化して検索可能にする。
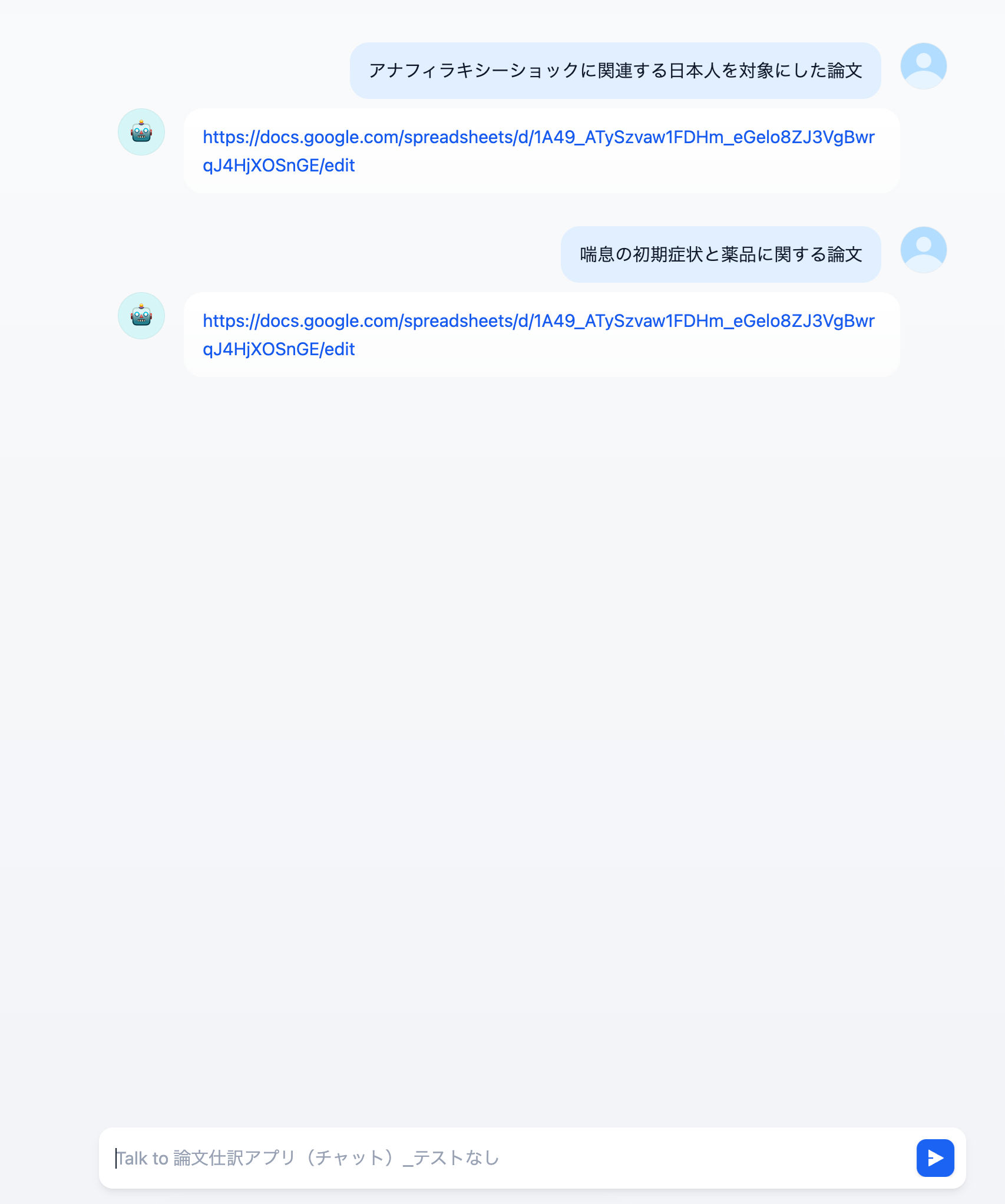
「特定の疾患(例:パーキンソン病)の病態メカニズムに関与するタンパク質に作用する既存薬のリストを、オフターゲット効果の観点から抽出せよ」といった具体的な指示をエージェントに与える。
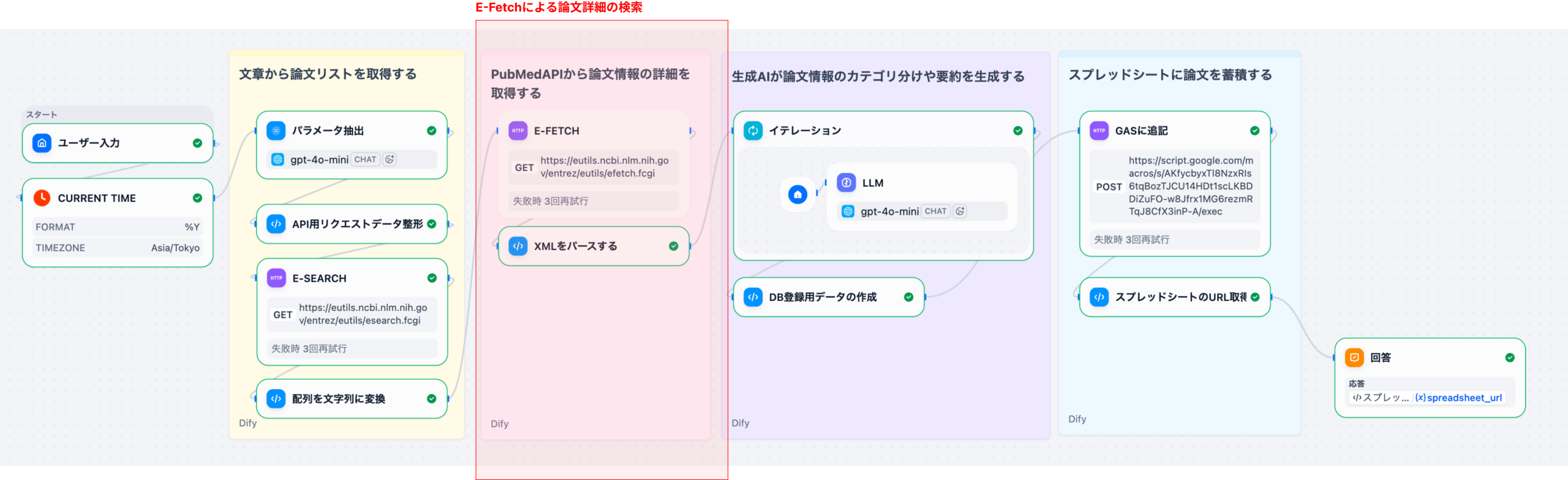
エージェントがKBを横断的に検索し、関連する論文の文脈(疾患-タンパク質-薬剤の関係性)を抽出。従来の検索では見落とされがちな、類似性の高い概念を基に候補をリストアップする。
抽出された候補薬に対し、関連論文数、作用メカニズムの明確性、臨床試験のフェーズなどの基準でスコアリング。AIは根拠となった論文の引用元を必ず付与する。
上位にランク付けされた候補について、研究者が抽出されたエビデンス(論文のハイライトや要約)を基に、in vitro/in vivoでの検証に進む。
このプロセスにより、数ヶ月〜数年かかっていた文献探索の時間を数週間単位に短縮する可能性があり、創薬のスピードを飛躍的に向上させます。
5. AIが導き出した候補の専門家による検証と品質管理
AIエージェントが生成した候補は、あくまで「仮説」であり、最終的な医薬品開発プロセスにおいては、人間の専門家による厳格な検証と品質管理が不可欠です。AIが導き出した候補薬や作用メカニズムは、必ずウェットラボでの基礎研究(in vitro/in vivo)を経て、ヒトでの安全性・有効性を確認する臨床試験に進む必要があります。
AIは、文献の網羅的解析という部分で圧倒的な優位性を示しますが、知財戦略や薬価交渉、副作用の再評価といった構造的な課題の解決は、依然として製薬企業やアカデミアの戦略的な判断に委ねられます。AIは「発見」を加速させ、人間は「実用化」を確実にする、という役割分担が、今後のDR成功の鍵となります。
AIの予測精度は、学習データの質と量に依存します。 Difyエージェントに組み込む知識ベースのデータ(論文、臨床データ、オミクスデータなど)は、常に最新かつ信頼性の高いソースから選定し、バイアスや誤情報を含まないようにキュレーション(選別・整理)を行う必要があります。PMDAもAI活用行動計画を策定し、規制当局においてもデータの品質管理が重要視されています。
まとめ
ドラッグ・リポジショニング(DR)は、開発期間とコストを大幅に短縮する創薬の有力な手法ですが、膨大な文献からの候補探索に限界がありました。Difyのエージェント機能は、RAG(検索拡張生成)技術を活用し、医学・薬学文献を網羅的かつ客観的に解析することで、この探索フェーズを革新します。AIエージェントは、特定の疾患と既存薬の隠れた関係性を抽出し、客観的な仮説を短期間で生成する能力を持ちます。しかし、AIが導き出した候補は、必ず専門家によるウェットラボでの厳格な検証と、高品質なデータの継続的な供給によって裏付けられる必要があります。AIは「発見」を加速し、人間は「実用化」を確実にする、この協働体制こそが、今後のDR成功の鍵となるでしょう。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。





")

")

")
")
")
")
")
")