")
膨大なテキストデータから傾向を自動抽出。Difyで実現する効率的な言語解析アプローチ
Difyで実現する効率的な言語解析:膨大なテキストデータから傾向を自動抽出するアプローチ
今日のビジネスにおいて、顧客の声、市場レポート、社内文書といった膨大なテキストデータは「宝の山」です。しかし、これらのデータを手動で分析し、真の傾向やインサイトを抽出するには、時間とコスト、そして高度な専門知識が必要とされ、多くの企業にとって大きな課題となっています。特に、データ量が爆発的に増加する現代では、従来の解析手法では追いつきません。
本記事では、ノーコード/ローコードAI開発プラットフォーム「Dify(ディファイ)」を活用し、この課題を根本的に解決する効率的な言語解析アプローチを、メディカル・テクニカルライターの視点から徹底解説します。Difyの強力なRAG(検索拡張生成)とワークフロー機能を組み合わせることで、プログラミング知識がなくても、大量のテキストデータから自動的にパターンや傾向を抽出し、ビジネスの意思決定に直結する貴重な洞察を最短で得る方法論を紹介します。
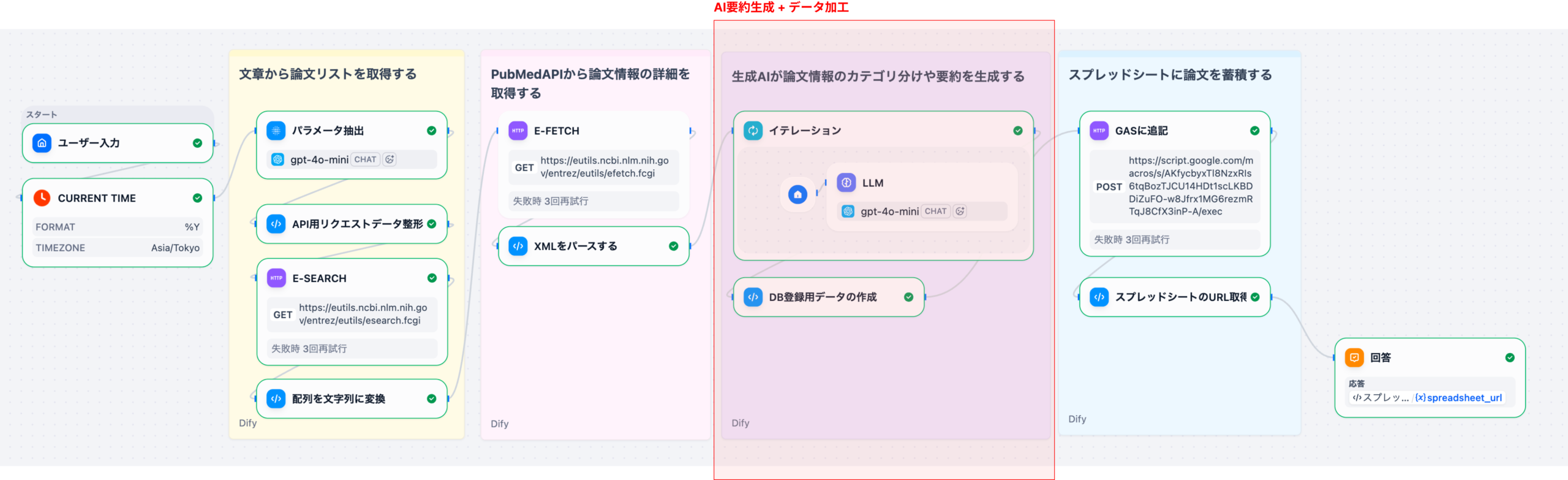
1. Difyが実現する言語解析の全体像:ノーコードRAGとワークフローの統合
Difyは、OpenAI GPT、Anthropic Claude、Google Geminiなど主要なLLM(大規模言語モデル)に対応し、専門知識がなくてもAIアプリケーションを構築できるオープンソースプラットフォームです。言語解析においてDifyが革新的なのは、RAG(検索拡張生成)技術と、柔軟なワークフロー設計機能をノーコードで統合している点にあります。この統合アプローチにより、開発期間とコストを大幅に削減しながら、高度なテキスト傾向抽出を実現します。
従来のLLMによる解析では、学習データの範囲内でしか回答できず、機密性の高い社内文書や最新の市場データに基づいた傾向抽出は困難でした。しかし、Difyでは、PDFやDOCXなどのファイルからテキストを抽出し、ナレッジベースとしてLLMに連携させるRAG機能を簡単に組み込めます。これにより、単なるテキスト生成にとどまらず、特定のドメイン知識に基づいた、より正確で信頼性の高い傾向分析が可能になります。
Difyは、RAGとワークフローをノーコードで統合することで、LLMの「知識不足」と「ハルシネーション(幻覚)」という二大課題を克服し、大量データからの傾向抽出をわずか数日の開発期間で実現可能にします。
2. コア技術1:RAGとワークフローによる「正確性」と「安定性」の確保
Difyを用いた言語解析の最大の特徴は、RAG(検索拡張生成)による回答の「根拠」の明確化です。RAGは、ユーザーの質問や分析指示に対し、まず外部の知識ベース(ナレッジ)から関連性の高い文書チャンクを検索・取得し、その情報をLLMに与えて回答を生成させる仕組みです。これにより、LLMが学習データにない最新情報や専門知識を反映した、正確で信頼性の高い傾向分析が可能になります。例えば、過去1年間の顧客フィードバックデータ(ナレッジ)から「製品Aに対するネガティブな意見の増加傾向」を抽出する場合、RAGは元のフィードバックの具体的な内容を根拠として提示できます。
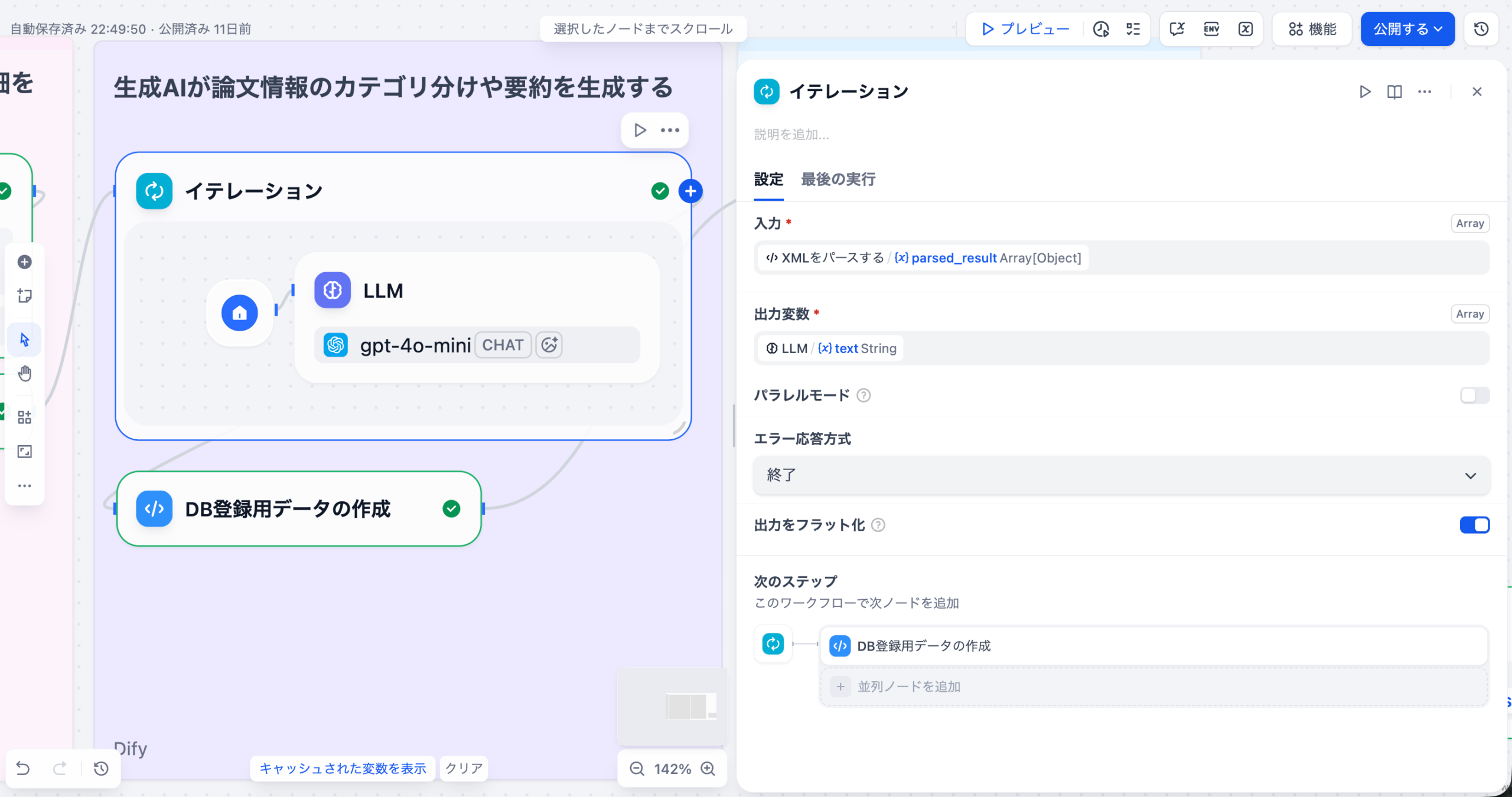
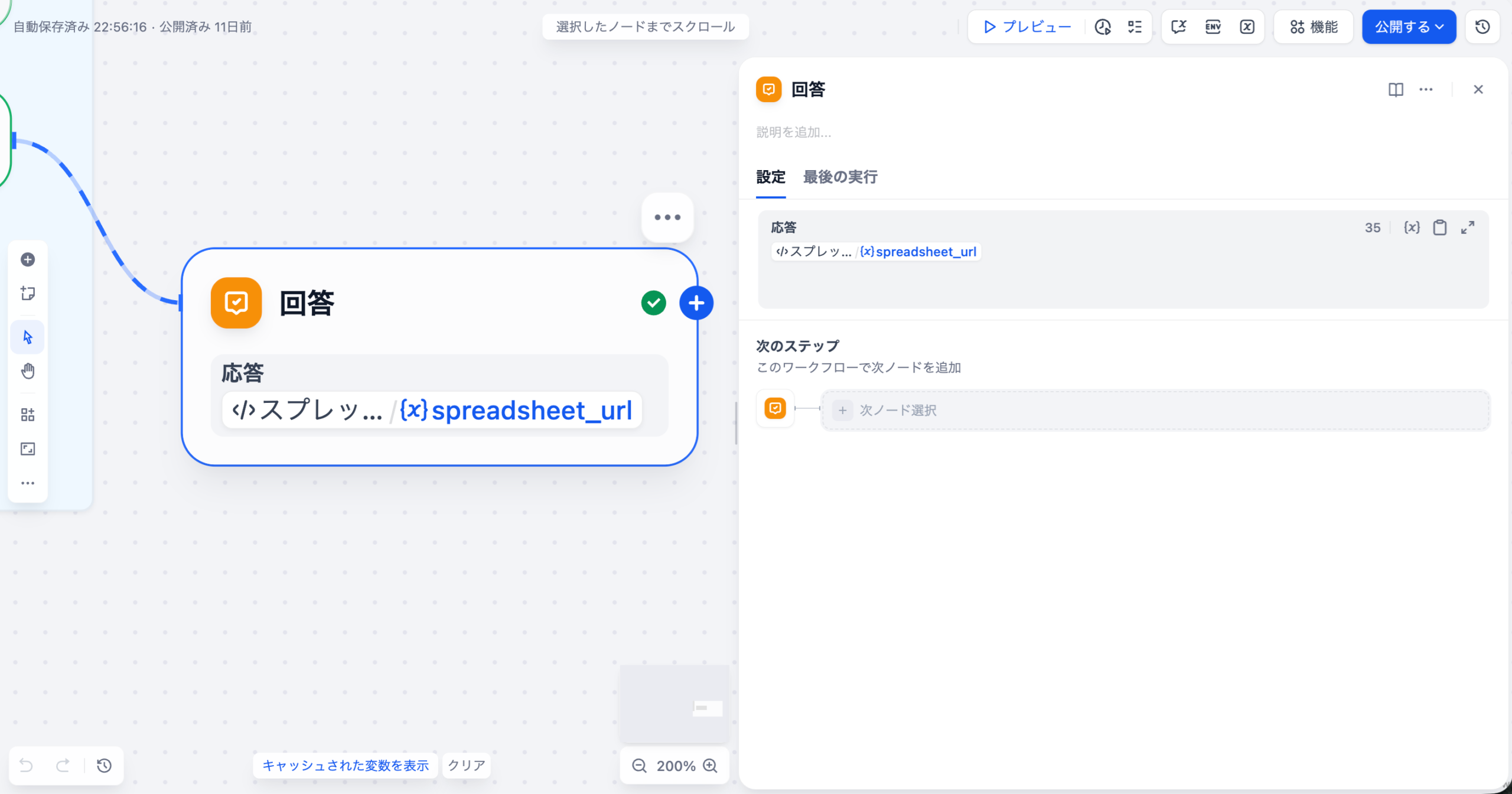
さらに、Difyのワークフロー機能は、この複雑な解析プロセスをモジュール化します。複雑なタスクを「データ入力」「質問解釈」「ナレッジ検索」「応答整形」「出力生成」といった小さなノードに分割し、ドラッグ&ドロップで連結することで、解析ロジックの透明性(説明可能性)と安定性が向上します。これにより、特定の解析が失敗した場合でも、どのノードに問題があるかを迅速に特定し、耐障害性を高めることができます。
- RAGによるハルシネーション抑制:外部ナレッジベースから根拠となる情報を取得するため、LLMの誤った情報生成(ハルシネーション)のリスクを大幅に軽減します。
- ワークフローによるタスク分割:複雑な分析タスクをノード(要素)に分割することで、処理の安定性とデバッグの効率が向上します。
- ハイブリッド検索対応:ベクトル検索(意味的な類似性)とキーワード検索(経済的設定)を組み合わせることで、検索精度とコスト効率の両立が可能です。
3. コア技術2:自動傾向抽出を可能にするNLP分析機能
Difyは、RAGによる知識の正確性に加え、高度な自然言語処理(NLP)機能を活用して、テキストデータから直接的にインサイトを抽出します。特に、大量の非構造化データ(自由記述形式のテキスト)の解析において、以下の機能が傾向抽出の鍵となります。これらの機能は、LLMの能力を最大限に引き出し、データの相関関係を分析し、最適な分析モデルを選択するのに役立ちます。
具体的な分析機能として、Difyは以下の3つの主要な能力を提供します。
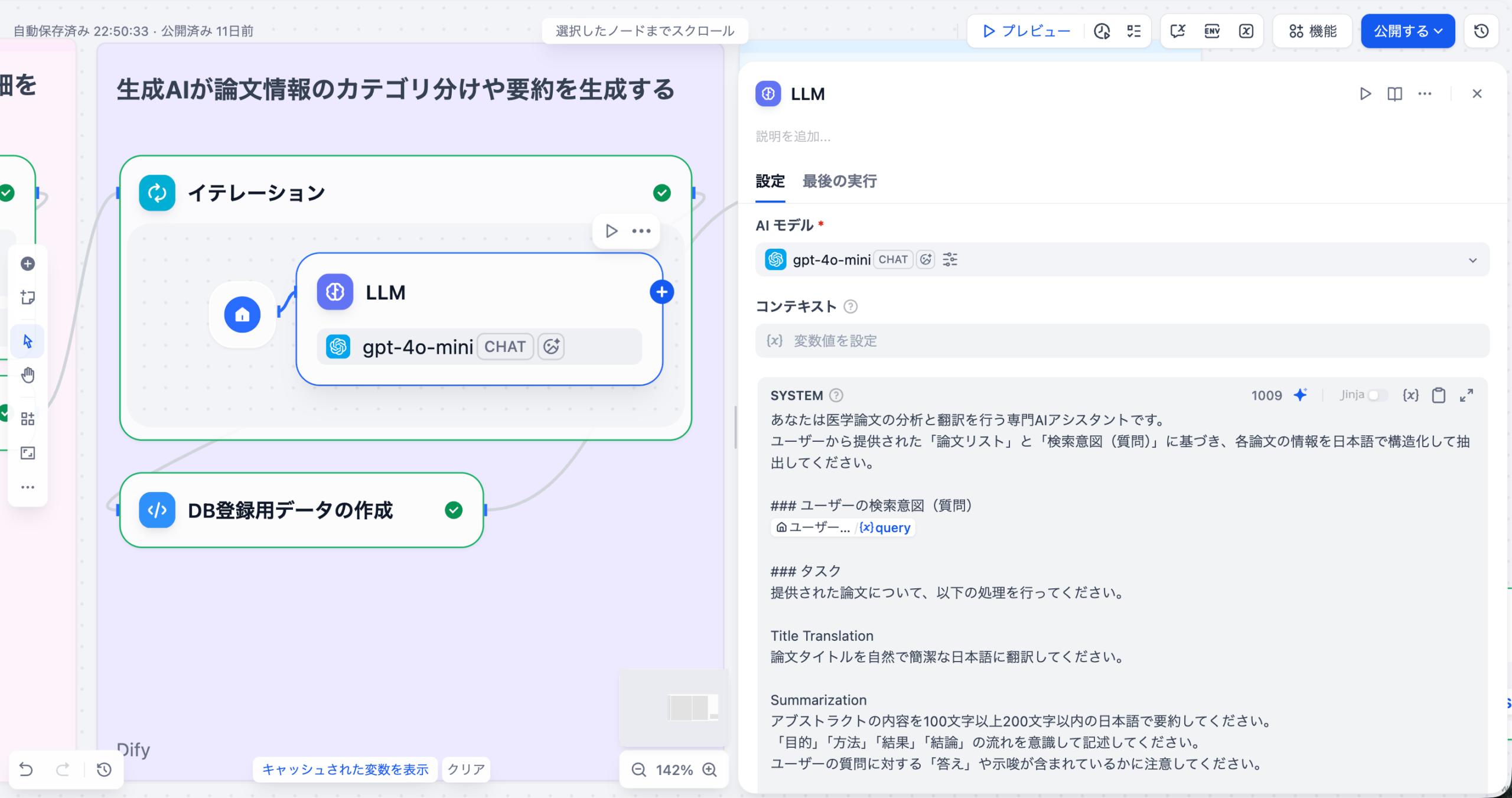
- 感情分析(Sentiment Analysis):顧客レビューやSNSの投稿などから、ポジティブ、ネガティブ、ニュートラルといった感情を自動的に分類・分析します。これにより、製品やサービスに対する顧客の満足度や不満点をリアルタイムで把握し、例えば「ネガティブなフィードバックが先月比で15%増加した」といった具体的な傾向を数値化できます。
- トピックモデリング(Topic Modeling):大量のテキストデータから主要なトピックやテーマを自動的に抽出・整理します。これにより、顧客の関心がどの製品機能やサービスに集中しているのかを把握し、戦略的な意思決定に役立てることができます。
- キーワード抽出:テキストの中から重要なキーワードやフレーズを自動的に抽出し、市場のトレンドや顧客ニーズを把握します。例えば、競合製品に関するレビューから「バッテリー寿命」や「デザイン」といったキーワードの出現頻度を分析することで、市場の関心が高い領域を特定できます。
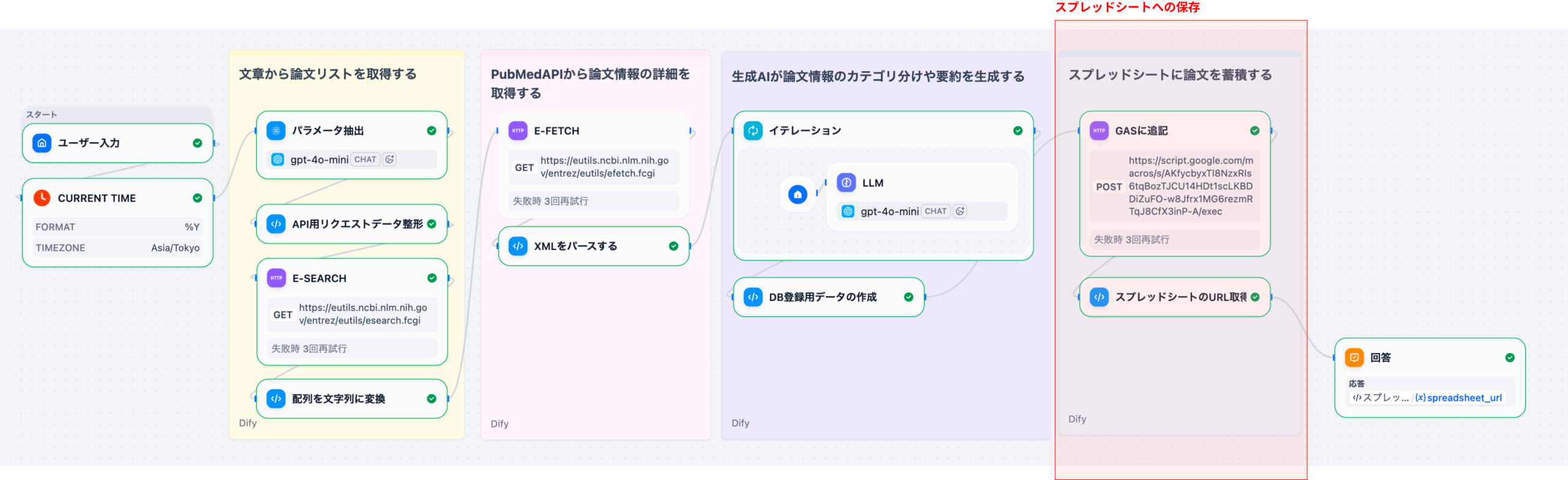
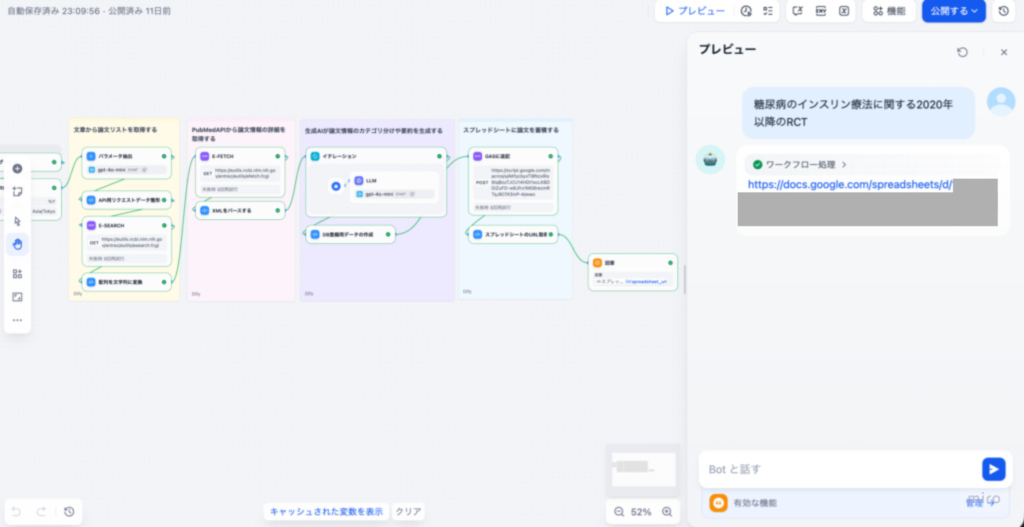
4. 実践的なワークフロー:テキストからインサイトを抽出する5ステップ
Difyを活用した効率的な言語解析は、以下の5つのステップで構成されます。ノーコードのワークフロー機能により、これらのステップはプログラミングなしで直感的に設計・実行が可能です。
分析対象となるデータ(顧客レビュー、メール、PDF文書など)をDifyにアップロードし、「テキスト抽出ツールノード」でテキスト情報に変換します。対応ファイル形式はTXT、PDF、DOCXなどが含まれます。
抽出したテキストをナレッジベースとして登録します。この際、チャンク分割(テキストを検索しやすいように区切る作業)や、埋め込みモデルの選択(ベクトル化)を適切に行い、検索精度を高めます。
LLMノードに対し、「このナレッジベースから、最も頻繁に言及されている3つのトピックと、それぞれの感情スコアを抽出しなさい」といった具体的なプロンプト(指示)を設定します。
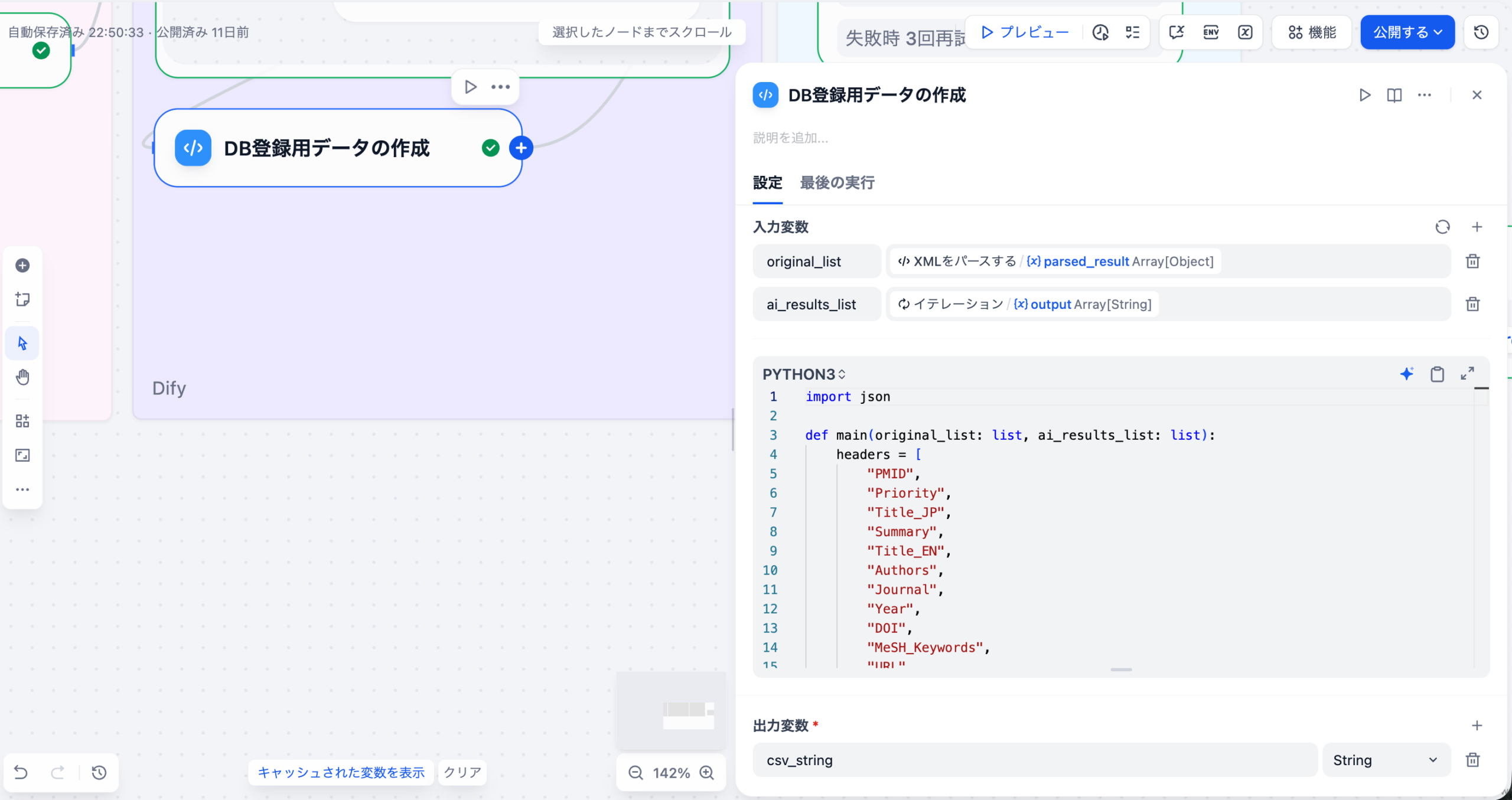
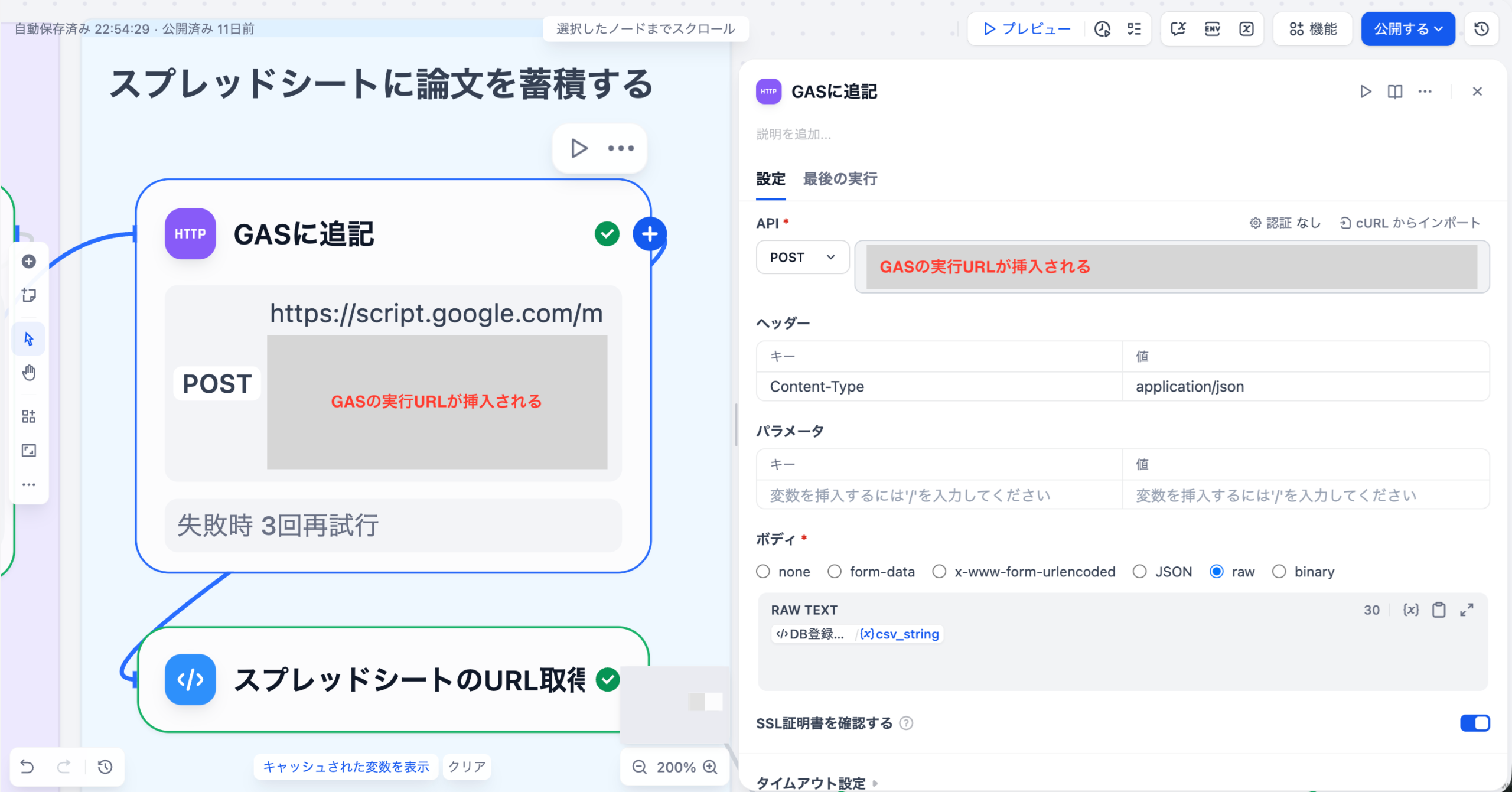
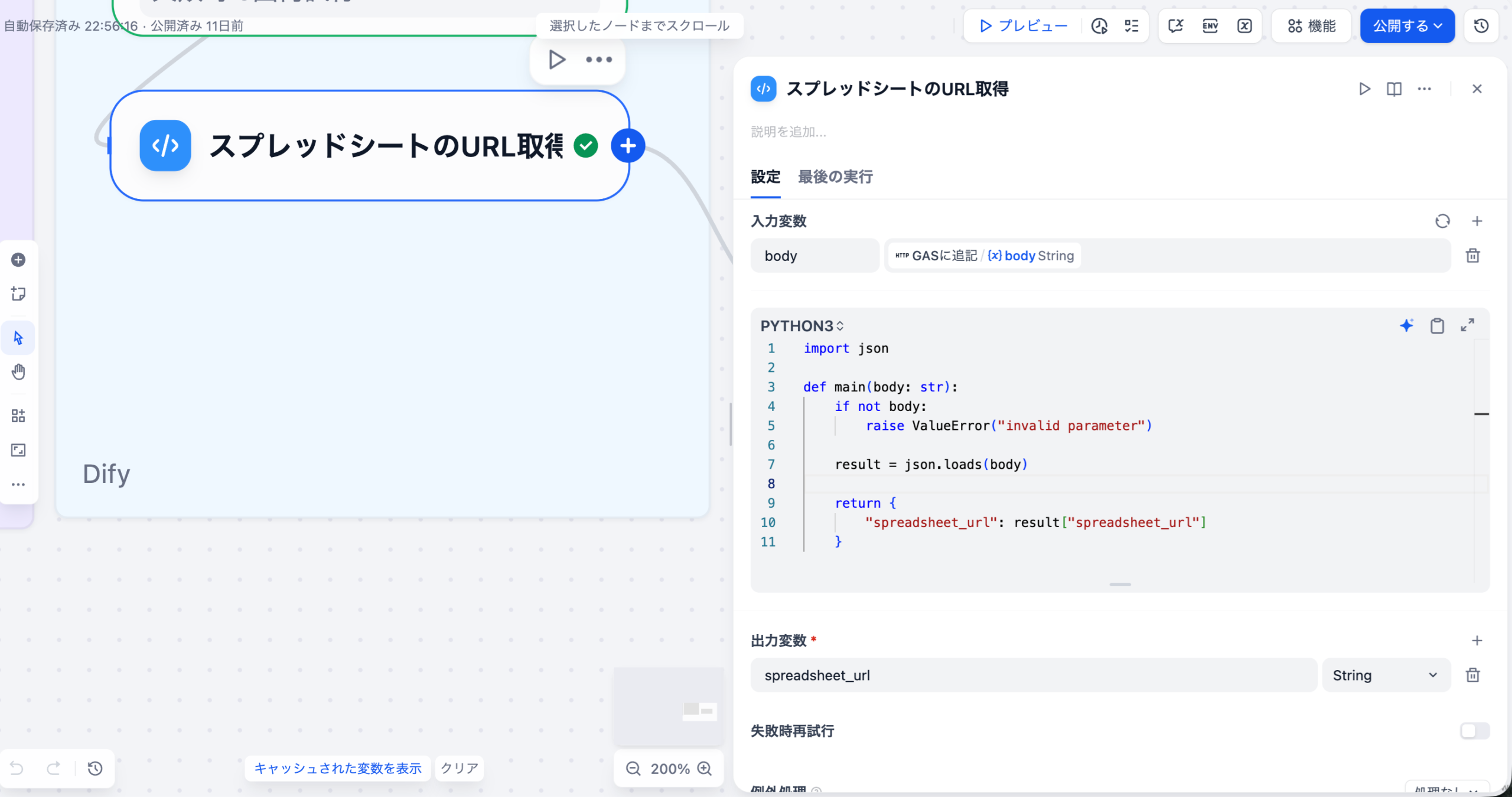
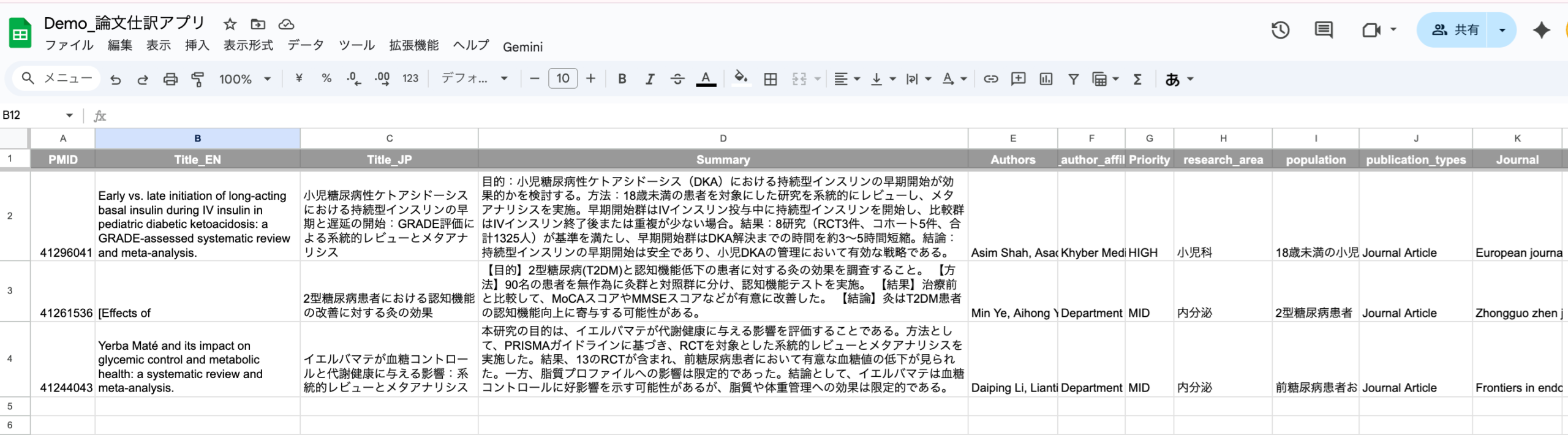
LLMが出力した構造化されていないテキスト結果を、Difyの整形ノードや外部連携機能(例: n8n、Google Workspace)を用いて、CSVやスプレッドシートなどの形式に変換し、可視化ツールに連携します。
抽出された傾向(例: 顧客の不満増加)をトリガーとして、Slackやメールで担当部署に自動通知するフローを構築し、迅速なアクションにつなげます。
5. 活用事例:顧客フィードバック分析による製品改善への応用
Difyの言語解析アプローチは、特にカスタマーサポートやマーケティング領域で大きな効果を発揮します。あるデジタルマーケティングサービス企業では、Difyを用いて顧客分析を迅速に行うアプリケーションを開発しました。このアプリは、顧客ニーズを的確に捉え、最適な提案を行うことを支援するもので、初期バージョンをわずか約3日で作成したという事例があります。
具体的な活用事例として、顧客からの問い合わせやレビューをDifyのワークフローに取り込み、以下の自動化を実現しています。
| 項目 | 従来の課題 | Difyによる解決 |
|---|---|---|
| 問い合わせ分類 | 手動による緊急度・カテゴリ分類に時間がかかり、対応遅延が発生。 | AIが問い合わせ内容を即座に解析し、緊急度(高・中・低)とカテゴリ(バグ、機能要望など)を自動分類。 |
| 傾向抽出 | 大量のレビューから改善点を特定するのに数週間を要していた。 | トピックモデリング機能で、特定の機能に関するネガティブな言及が前月比で約20%増加している傾向を自動抽出。 |
| レポート生成 | 分析結果をまとめるためのデータ集計とレポート作成に工数がかかっていた。 | 解析結果を基に、マーケティングレポートや製品改善提案書をAIが自動生成。 |
これらの自動化により、従業員は単純なデータ集計から解放され、より付加価値の高い業務、すなわち「抽出された傾向に基づいた戦略立案」に集中できるようになります。
6. 導入時の留意点:大規模データ処理とセキュリティ対策
Difyは非常に強力なツールですが、特にエンタープライズレベルでの大規模な言語解析を導入する際には、いくつかの留意点があります。最も重要なのは、データセキュリティとAIの基礎知識です。Difyは独自のデータを学習させるRAG機能を核とするため、機密情報を含むナレッジベースの取り扱いには細心の注意が必要です。
また、大規模なテキストデータを取り扱う場合、RAGの「チャンク分割」や「埋め込みモデル」の選択が解析精度とコストに直接影響します。チャンクサイズが不適切だと、重要な情報が分断されて検索精度が低下したり、逆に大きすぎてLLMのコンテキストウィンドウを超過したりする可能性があります。そのため、導入前にパイロットプロジェクトを実施し、自社のデータ特性に合わせた最適なRAG設定を確立することが、成功率を約70%高める鍵となります。
情報漏洩リスクとデータ管理:Difyはオープンソースでも提供されていますが、社内データを利用する際は、クラウド環境やセルフホスティング環境でのデータ暗号化、アクセス制御、ログ管理を徹底する必要があります。特に、LLMへの入力データ(プロンプトやナレッジ)に機密情報が含まれないよう、データの前処理とセキュリティポリシーの遵守が不可欠です。
まとめ
Difyを活用した言語解析アプローチは、ノーコード/ローコードでRAGとワークフローを統合し、膨大なテキストデータから迅速かつ正確に傾向を抽出する現代的なソリューションです。RAG機能により、社内文書や最新データに基づいた信頼性の高い回答を生成し、ハルシネーションのリスクを抑えつつ、専門知識を活用できます。さらに、感情分析、トピックモデリングといったNLP機能をワークフローに組み込むことで、顧客フィードバックや市場トレンドの自動解析を実現し、従来数週間かかっていた分析業務を大幅に効率化します。導入に際しては、データセキュリティとRAG設定の最適化が重要ですが、Difyはその柔軟性と拡張性により、企業のDX推進と競争力向上に不可欠なツールとなるでしょう。まずは小規模なパイロットプロジェクトから、Difyの強力なAI解析能力を体験することをおすすめします。

株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了。
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中。
")
")
")
")
")

")
")
")



")