")
Part2. Difyを⽤いてXAPIから直近のポストを取得する
| 目次 |
1. はじめに
本記事は、Difyのワークフローを使って、X(旧Twitter)のソーシャルリスニングを⾃動化するシリーズのPart 2です。
Part 1の復習: 前回の記事では、X APIの基礎について解説しました。具体的には、以下の内容を扱いました。
- X APIとは何か、その基本的な仕組み
- X APIの料⾦プランと制約
- Bearer Tokenの取得⽅法
- Pythonコードを使ったX APIの基本的な使い⽅
本記事(Part 2)では、Difyのワークフローを使ってX APIから直近のポストを取得する⽅法を詳しく解説します。
Part 1で学んだX APIの知識を活かして、DifyのHTTPリクエストノードやコードノードを使って、実際にツイートを取得する処理を実装していきます。
シリーズ構成
- Part 0: X APIを⽤いたソーシャルリスニング概要
- Part 1: X 旧Twitter) APIの基礎
- Part 2(本記事): Difyを⽤いてX APIから直近のポストを取得する
- Part 3: LLMを⽤いて⾃動でデータラベルを付与する
- Part 4: スプレッドシートにデータを格納する
- Part 5: Streamlitを⽤いたデータの可視化例
2. ワークフローの位置づけ
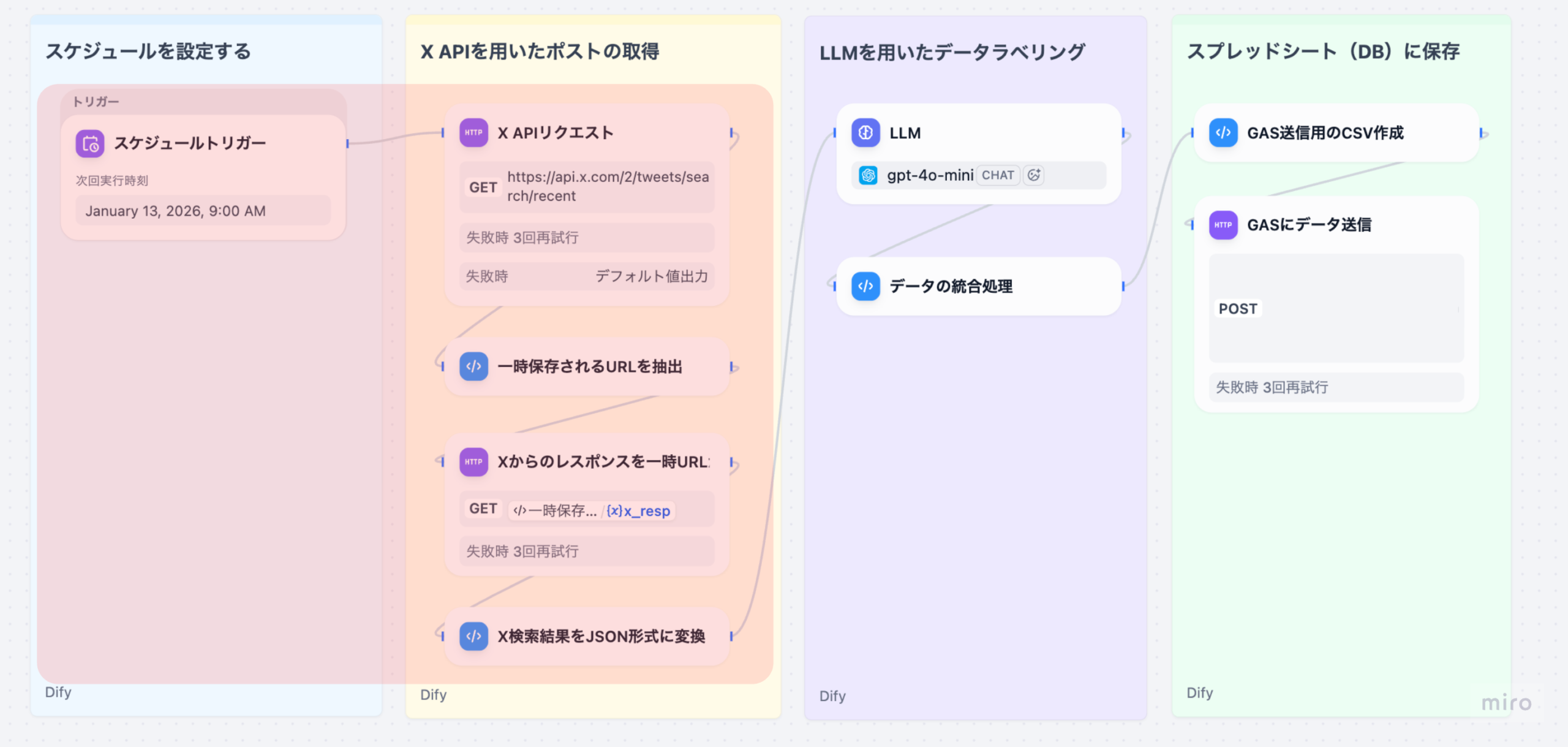
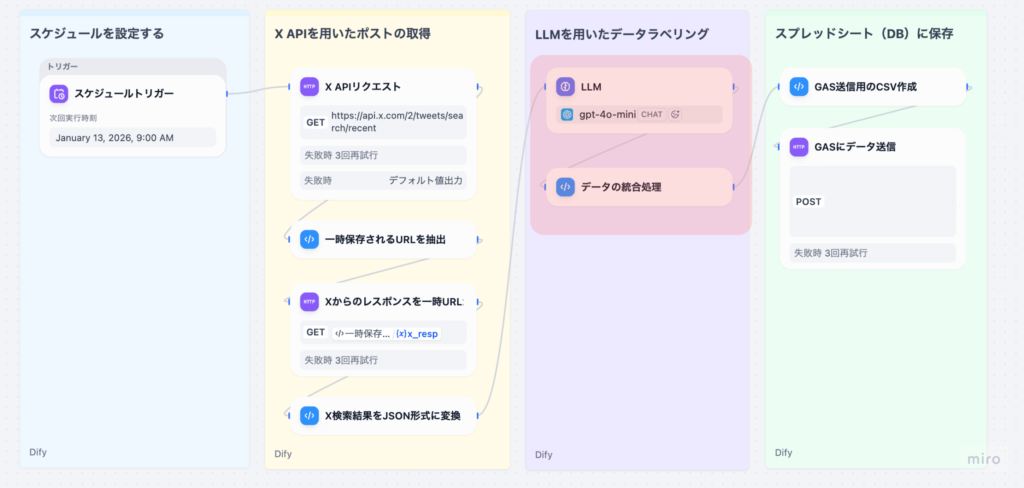
このワークフローは、以下のような処理の流れで構成されています。
- スケジュールトリガー : 毎⽇決まった時間にワークフローを⾃動実⾏
- XAPIリクエスト: 指定したキーワードでツイートを検索
- ⼀時URL抽出: X APIのレスポンスから⼀時URLを取得
- ⼀時URLから取得: ⼀時URLから実際のツイートデータを取得
- JSON形式変換: ツイートデータを構造化データに変換
- LLM処理: 感情判定、適応症抽出、副作⽤抽出など(Part 3で解説)
- データ統合: LLM結果と元データをマージ(Part 3で解説)
- CSV作成: スプレッドシート保存⽤にCSV形式に変換(Part 4で解説)
- GAS送信: Google Apps Scriptに送信してスプレッドシートに保存(Part 4で解説)
本記事では、ステップ1〜4(X APIリクエストからJSON形式変換まで)を詳しく解説します。LLM処理はPart 3(次の記事)で取り上げます。
3. 環境変数の設定
このワークフローでは、以下の環境変数を使⽤します。Difyのワークフロー設定画⾯で事前に設定しておく必要があります。
画⾯右上にある[ENV]と書かれた小さなボタンをクリックします。
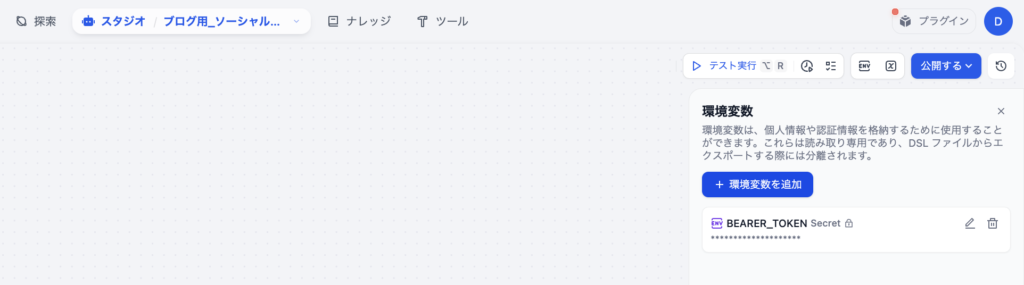
| 環境変数名 | 型 | 説明 | 設定例 |
|---|---|---|---|
| BEARER_TOKEN | secret | X APIのBearer Token | (X APIで取得したトークン) |
注意: X APIの認証には、Bearer Token⽅式を使⽤します。HTTPリクエストブロックの認証機能を使うと400エラーになるため、ヘッダーに直接 Authorization: Bearer でキーを指定する必要があります。Part1で取得したX APIのBearer Tokenをここで貼り付けて保存してください。
4. 各ノードの詳細解説
4-1. X APIリクエスト(HTTP Requestノード)
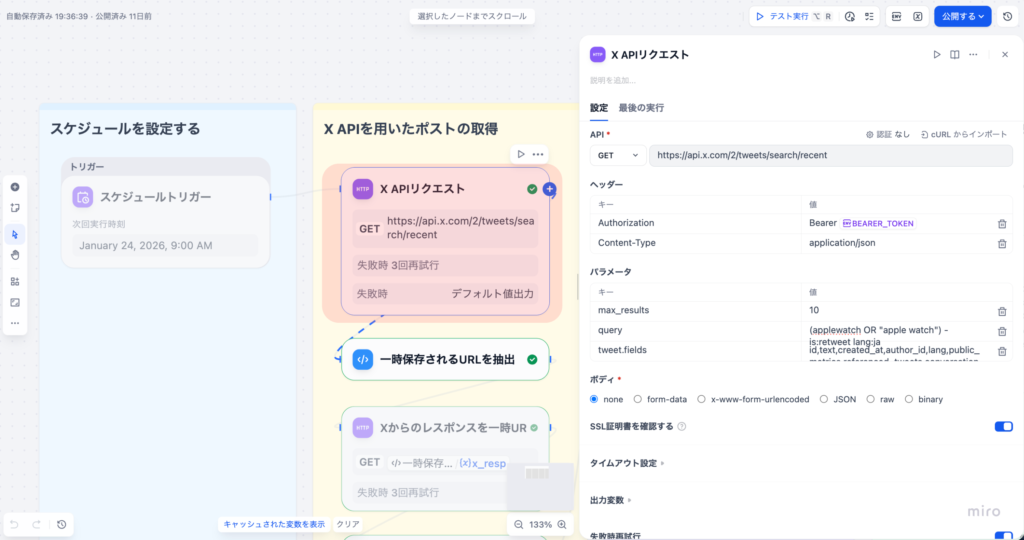
X API(旧Twitter API)v2を使って、指定したキーワードでツイートを検索するノードです。
設定内容
| 項⽬ | 設定値 |
|---|---|
| メソッド | GET |
| URL | https://api.x.com/2/tweets/search/recent |
| 認証 | なし |
| ヘッダー | 1. Authorization: Bearer {{#env.BEARER_TOKEN#}} 2. Content-Type:application/json |
パラメータ
| パラメータ名 | 値 | 説明 |
|---|---|---|
| max_results | 10 | 取得件数 |
| query | applewatch OR “apple watch” -is:retweet lang:ja | 検索クエリ |
| tweet.fields | id,text,created_at,author_id,lang,public_metrics,referenced_tweets,conversation_id,in_reply_to_user_id,source,entities,context_annotations,possibly_sensitive,attachments | 取得するフィールド |
max_resultsは最低値が10となります。Freeプランでテストする場合でも5などに絞っていると、エラーが返ってくるため必ず10以上を設定してください。
検索クエリの構⽂の解説
| 演算⼦ | 説明 | 例 |
|---|---|---|
| -is:retweet | リツイートを除外 | –is:retweet lang:ja |
| lang:ja | ⽇本語のツイートのみ | lang:ja |
| OR | OR条件 | applewatch OR “apple watch” |
認証の注意点
重要: HTTPリクエストブロックの認証機能を使うと、400エラーになることがあります。そのため、ヘッダーに直接Authorization: Bearerでキーを指定する必要があります。
Authorization: Bearer {{#env.BEARER_TOKEN#}}
レスポンス形式
X API v2は、⼤量のデータを返す場合、⼀時URL( url フィールド)を返すことがあります。この⼀時URLから実際のデータを取得する必要があります。
4-2. ⼀時URL抽出(Codeノード)
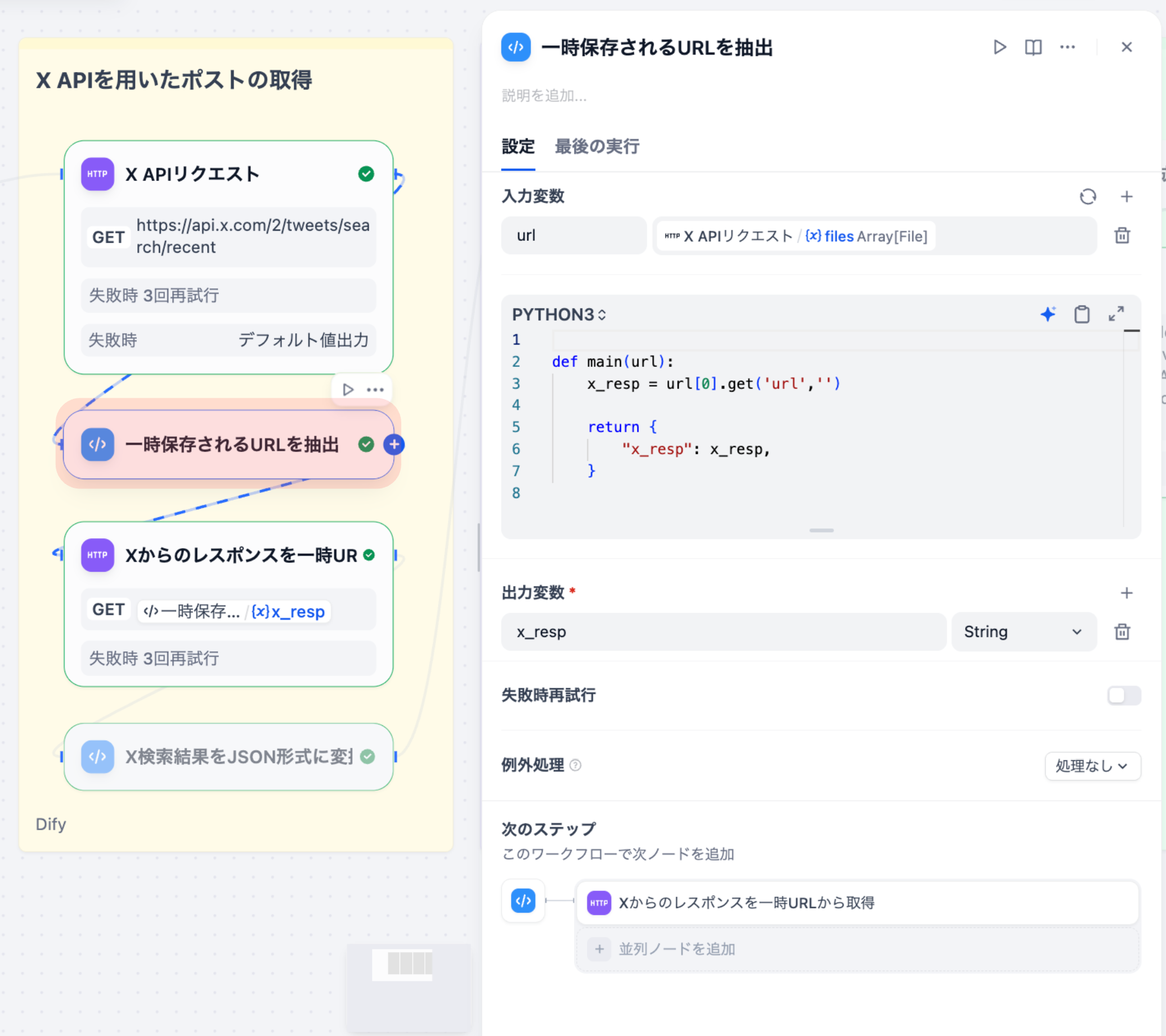
X APIのレスポンスから⼀時URLを抽出するノードです。X API v2では、データが⼤きい場合、直接データを返さずに⼀時URLを返すことがあります。
入⼒変数
| 変数名 | ソース | 型 |
|---|---|---|
| url | X APIリクエストノード | array[file] |
コード
def main(url):
# レスポンスのfiles配列から最初の要素のurlを取得
x_resp = url[0].get('url', '')
return {
"x_resp": x_resp,
}
処理の流れ
- レスポンス解析: X APIのレスポンスは files 配列として返される
- URL抽出: 配列の最初の要素から url フィールドを取得
- 出⼒: ⼀時URLを⽂字列として返す
出⼒
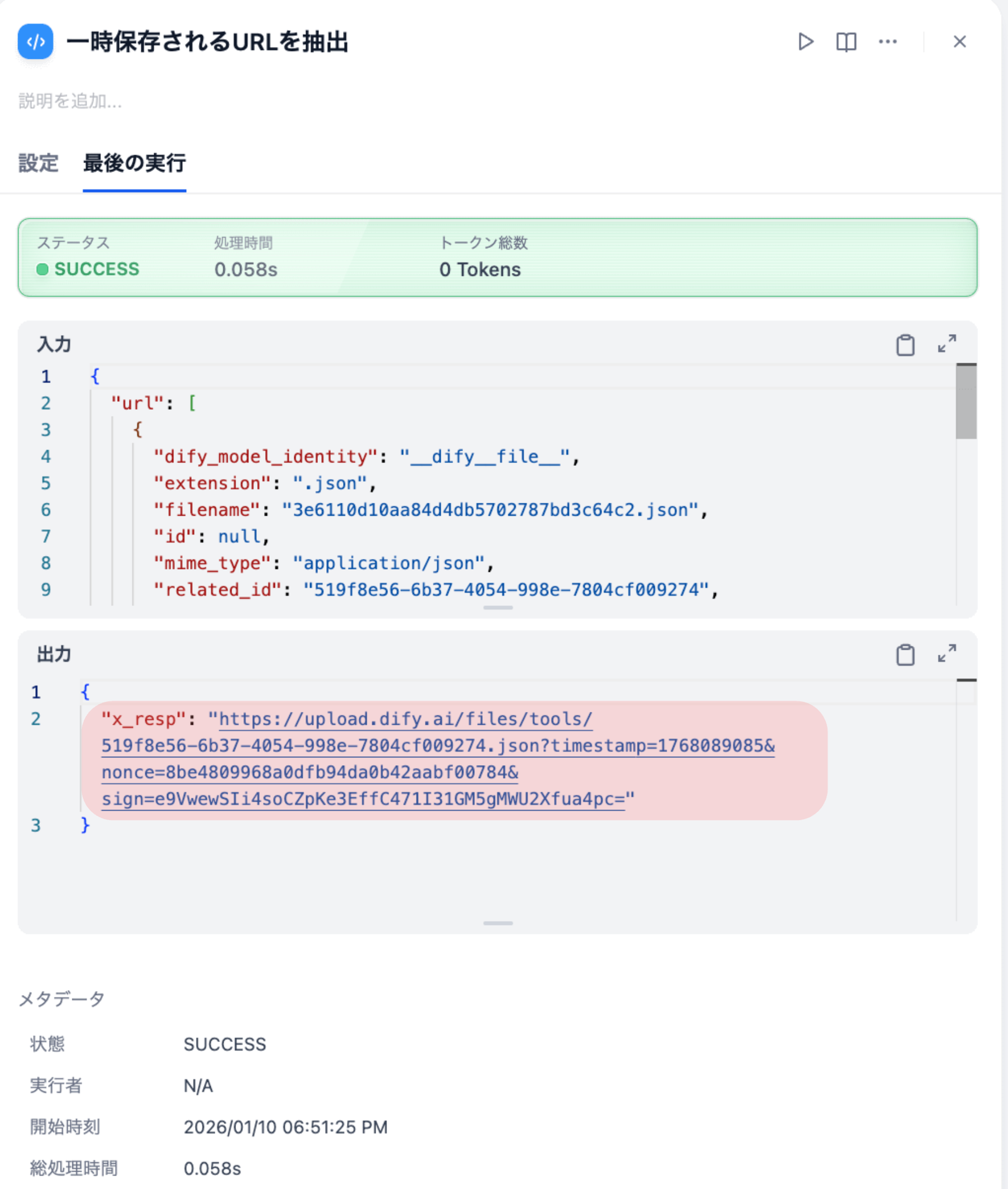
| 出⼒名 | 型 | 説明 |
|---|---|---|
| x_resp | string | ⼀時URL(例: https://… ) |
4-3. ⼀時URLから取得(HTTP Requestノード)
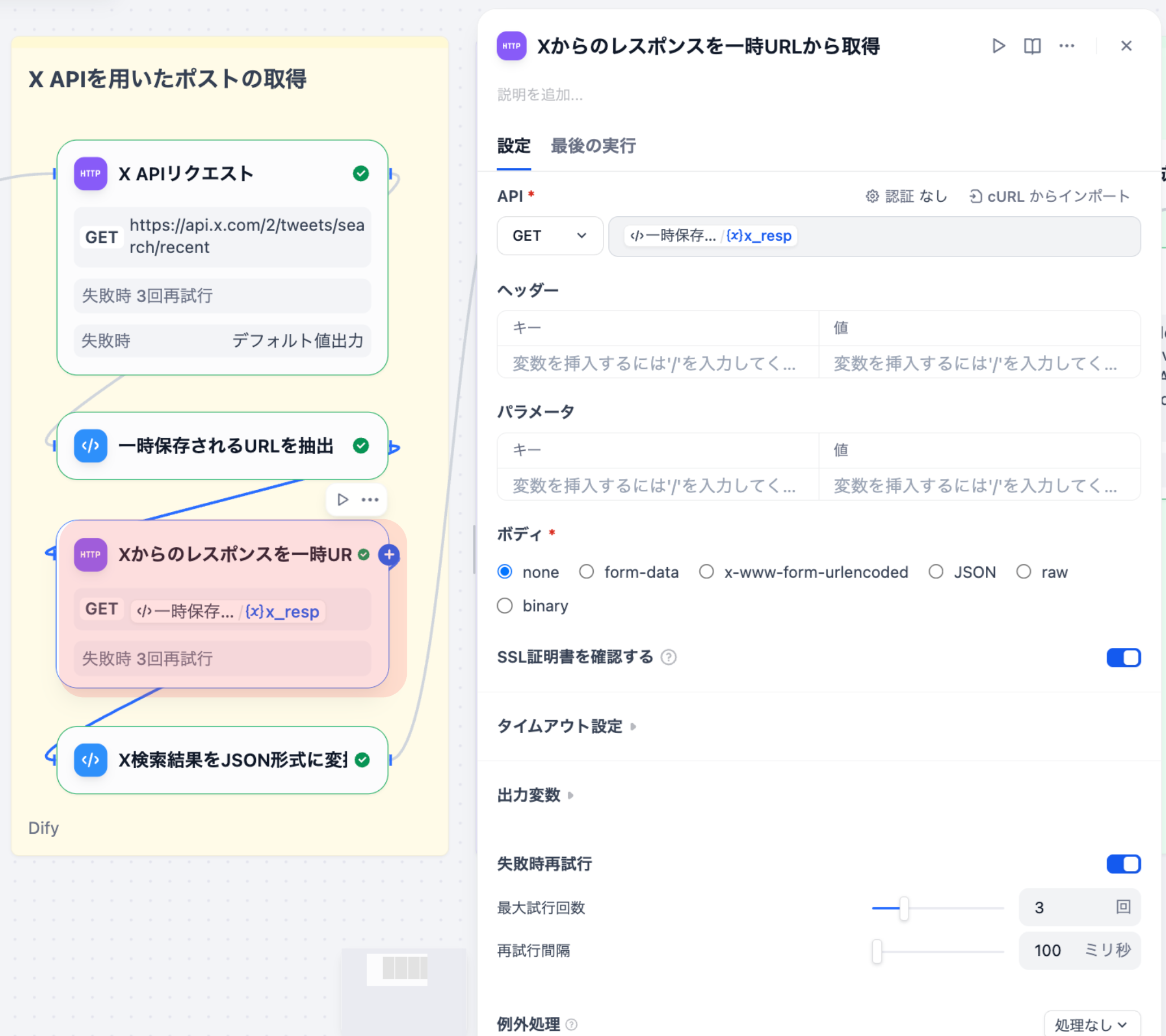
⼀時URLから実際のツイートデータを取得するノードです。X APIから返却されたURLを開くと、中にデータが格納されています。
設定内容
| 項⽬ | 設定値 |
|---|---|
| メソッド | GET |
| URL | {{#x_resp#}} |
| 認証 | なし |
| ヘッダー | (空) |
実装の意図
X API v2では、データが⼤きい場合、直接JSONを返さずに⼀時URLを返します。この⼀時URLにアクセスすることで、実際のツイートデータを取得できます。
レスポンス例
{
"data": [
{
"id": "1234567890",
"text": "Apple Watchの効果...",
"created_at": "2025-01-14T12:00:00.000Z",
"author_id": "987654321",
"lang": "ja",
"public_metrics": {
"retweet_count": 10,
"reply_count": 5,
"like_count": 20,
"quote_count": 2
}
}
],
"meta": {
"result_count": 20
}
}
4-4. X検索結果をJSON形式に変換(Codeノード)
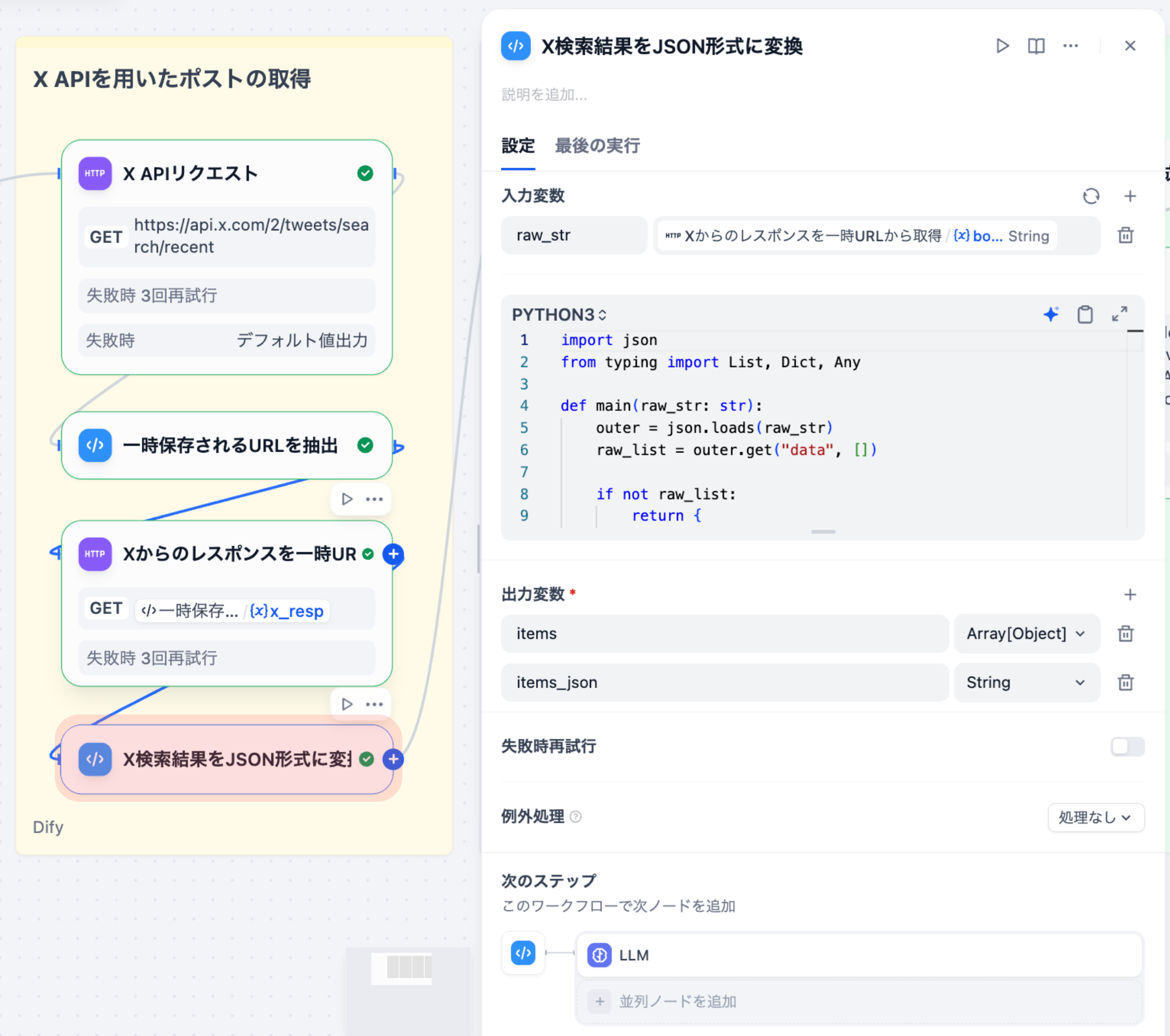
取得したツイートデータを、後続のLLM処理で扱いやすい構造化データに変換するノードです。
⼊⼒変数
| 変数名 | ソース | 型 |
|---|---|---|
| raw_str | ⼀時URLから取得ノード | string |
コード
import json
from typing import List, Dict, Any
def main(raw_str: str):
outer = json.loads(raw_str)
tweets: List[Dict[str, Any]] = raw_list
items = []
for t in tweets:
public = t.get("public_metrics", {}) or {}
text = t.get("text", "") or ""
text_lower = text.lower()
# search_keyword の判定ロジック
if "applewatch" in text_lower or "apple watch" in text_lower:
search_keyword = "Apple Watch"
entities = t.get("entities")
context_annotations = t.get("context_annotations")
attachments = t.get("attachments")
geo = t.get("geo")
result_row = {
# ---- 基本情報 ----
"tweet_id": t.get("id"),
"search_keyword": search_keyword,
"created_at": t.get("created_at"),
"author_id": t.get("author_id"),
"lang": t.get("lang"),
"text": text,
# ---- 会話・関係情報 ----
"conversation_id": t.get("conversation_id"),
"in_reply_to_user_id": t.get("in_reply_to_user_id"),
"referenced_tweets": t.get("referenced_tweets"),
"edit_history_tweet_ids": t.get("edit_history_tweet_ids"),
# ---- ツイートの属性 ----
"possibly_sensitive": t.get("possibly_sensitive"),
"source": t.get("source"),
"context_annotations": context_annotations,
"entities": entities,
"attachments": attachments,
"geo": geo,
# ---- パブリックメトリクス ----
"retweet_count": public.get("retweet_count", 0),
"reply_count": public.get("reply_count", 0),
"like_count": public.get("like_count", 0),
"quote_count": public.get("quote_count", 0),
"bookmark_count": public.get("bookmark_count", 0),
"impression_count": public.get("impression_count", 0),
}
items.append(result_row)
items_json = json.dumps(items, ensure_ascii=False)
return {
"items_json": items_json,
"items": items,
}
処理の流れ
- JSONパース: レスポンスのJSON⽂字列を解析
- データ抽出: data フィールドからツイート配列を取得
- 構造化: 各ツイートを構造化データに変換
- 基本情報(tweet_id, text, created_at等)
- 公開メトリクス(retweet_count, like_count等)
- LLM処理⽤のプレースホルダー(indication, adverse_events等)
- 出⼒形式: LLM⽤のJSON⽂字列と、後段処理⽤のPythonオブジェクトの両⽅を返す
出⼒データ構造
| フィールド名 | 説明 |
|---|---|
| tweet_id | ツイートID |
| search_keyword | 検索キーワード |
| created_at | 作成⽇時(ISO8601形式) |
| author_id | 著者ID |
| lang | 言語 |
| Text | ツイート本⽂ |
| retweet_count | リツイート数 |
| conversation_id | 会話スレッドID |
| in_reply_to_user_id | リプライ先のユーザーID |
| referenced_tweets | 参照ツイートのリスト |
| edit_history_tweet_ids | 編集履歴が有効な場合における、編集前含めたツイートIDの配列 |
| possibly_sensitive | センシティブコンテンツのフラグ |
| source | 投稿クライアントの情報 |
| context_annotations | トピックやエンティティに関する情報 |
| entities | ツイート内のメンション、ハッシュタグ、URLなど構造化情報 |
| attachments | メディア |
| geo | 位置情報 |
| reply_count | リプライ数 |
| like_count | いいね数 |
| quote_count | 引⽤ツイート数 |
出⼒
| 出⼒名 | 型 | 説明 |
|---|---|---|
| items_json | string | LLMに渡す⽤のJSON⽂字列 |
| items | array[object] | 後段処理で直接使う⽤のPythonオブジェクト |
5. まとめ
本記事(Part 2)では、DifyのワークフローでX APIからツイートを取得し、構造化データに変換するまでの処理を解説しました。
本記事で実現したこと
X API v2を使ったツイート検索
- ⼀時URLの仕組みとデータ取得⽅法
- ツイートデータの構造化(LLM処理の準備)
処理の流れの確認
- XAPIリクエスト: 指定キーワードでツイートを検索
- ⼀時URL抽出: レスポンスから⼀時URLを取得
- ⼀時URLから取得: 実際のツイートデータを取得
- JSON形式変換: LLM処理⽤に構造化データに変換
次のステップ
次回のPart 3では、ここで取得したツイートデータに対して、LLMで感情判定 ‧ 適応症抽出 ‧ 副作⽤抽出などの処理を⾏う⽅法を解説します。具体的には以下のテーマを扱います。
- LLMプロンプトの設計(Role, Input instruction, Task, Discipline)
- 感情判定 ‧ クラスタリングの実装
- LLM結果と元データの統合処理
- エラーハンドリングとデータ整合性の確保
これらの処理により、ツイートデータにAI分析結果が付与され、Part 4でのスプレッドシート保存に備えることができます。
シリーズ構成
- Part 0: X APIを⽤いたソーシャルリスニング概要
- Part 1: X 旧Twitter) APIの基礎
- Part 2(本記事): Difyを⽤いてX APIから直近のポストを取得する
- Part 3 LLMを⽤いて⾃動でデータラベルを付与する(←次の記事)
- Part 4: スプレッドシートにデータを格納する
- Part 5: Streamlitを⽤いたデータの可視化例

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら

監修者 株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中
")
")
")