
ClinicalTrials.gov 治験情報を自然言語で取得するAIワークフロー Part3
連載シリーズ
ClinicalTrials.gov 治験情報を自然言語で取得するAIワークフロー
| 目次 |
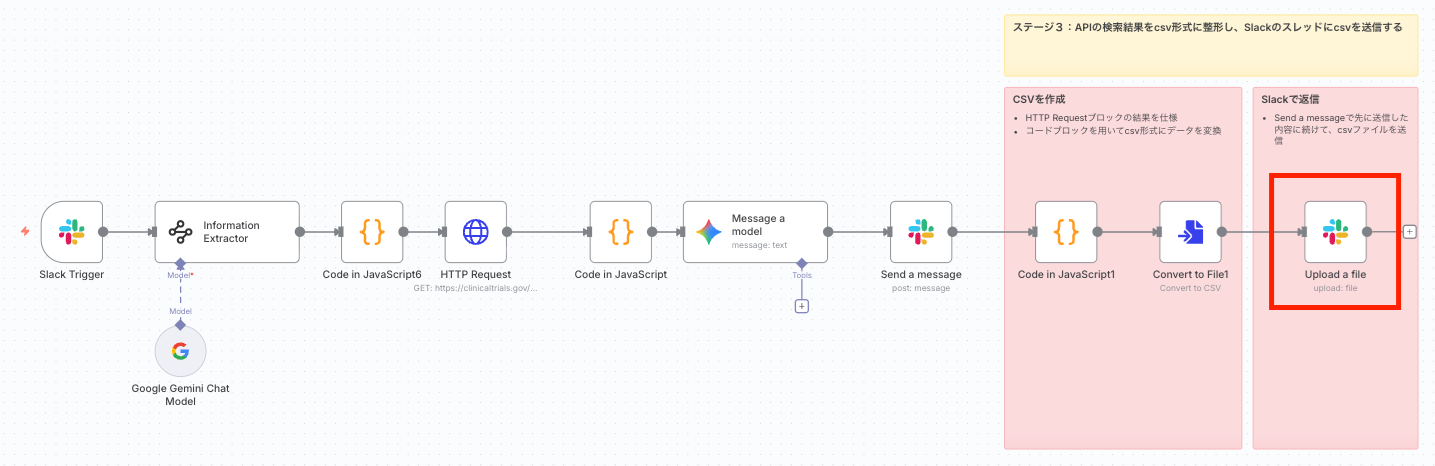
ワークフローの全体イメージ
| 検索 | 結果 | UI | ||
|---|---|---|---|---|
| Part 1 | 自然言語からAPI検索を実施 | 単語 | 要約 | Slack |
| Part 2 | 自然言語からAPI検索を行い生成AIが要約を実施 | 文章 | 要約 | Slack |
| Part 3 | 検索結果の一覧からcsvファイルと要約を生成する | 文章 | 要約 + csvファイル | Slack |
Part3. 検索結果の一覧からCSVファイルと要約を生成する
◆入力と回答のゴールイメージ
- Slack上でボット宛てに質問を行う

- Slack上にAPI検索結果の要約とcsvが送信される

<ワークフローの流れ>
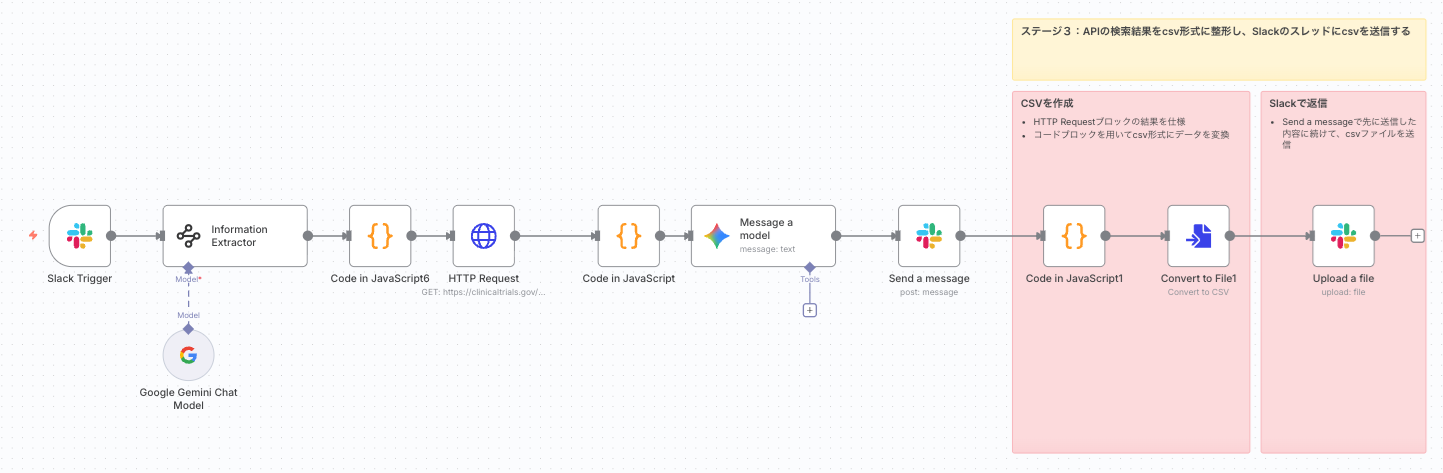
- Slack Trigger: Slackへのメンションをトリガーにワークフローを開始。
- Information Extractor: ユーザーの質問から、AIがClinicalTrials.govの検索クエリパラメータを抽出。
- Code in JavaScript6: 抽出されたパラメータから空の項目を削除しJSONを整形。
- HTTP Request: 整形されたクエリパラメータを用いてClinicalTrials.gov APIを検索。
- Code in JavaScript: 取得した臨床試験データを整形し、AI向けに要約テキストを生成。
- Code in JavaScript1: 取得した臨床試験データを整形し、CSV用の構造化データを生成。
- Message a model: Geminiモデルが要約されたデータとユーザーの質問に基づき回答を生成。
- Send a message: 生成された回答をSlackに返信。
- Convert to File1: Code in JavaScript1で生成された構造化データをCSVファイルに変換。
- Upload a file: 変換されたCSVファイルをSlackにアップロード。
◆ワークフローの説明
🚨 Part1,2の拡張版なので従来通りのブロックについては詳解せず、新規追加されたブロックのみ説明します。🚨
- Slack Triggerノードでワークフロー起動
(前回同様なので割愛)
- Information Extractorノードで検索条件を抽出
(前回同様なので割愛)
- Code in JavaScript6ノードでクエリを整形
(前回同様なので割愛)
- HTTP RequestノードでAPIを検索
(前回同様なので割愛)
- Code in JavaScriptノードでデータを整形(要約テキスト用)
(前回同様なので割愛)
- Message a modelノードでAIが回答を生成
(前回同様なので割愛)
- Send a messageノードでSlackに返信
(前回同様なので割愛)
8. Send a message: 生成された回答をSlackに返信
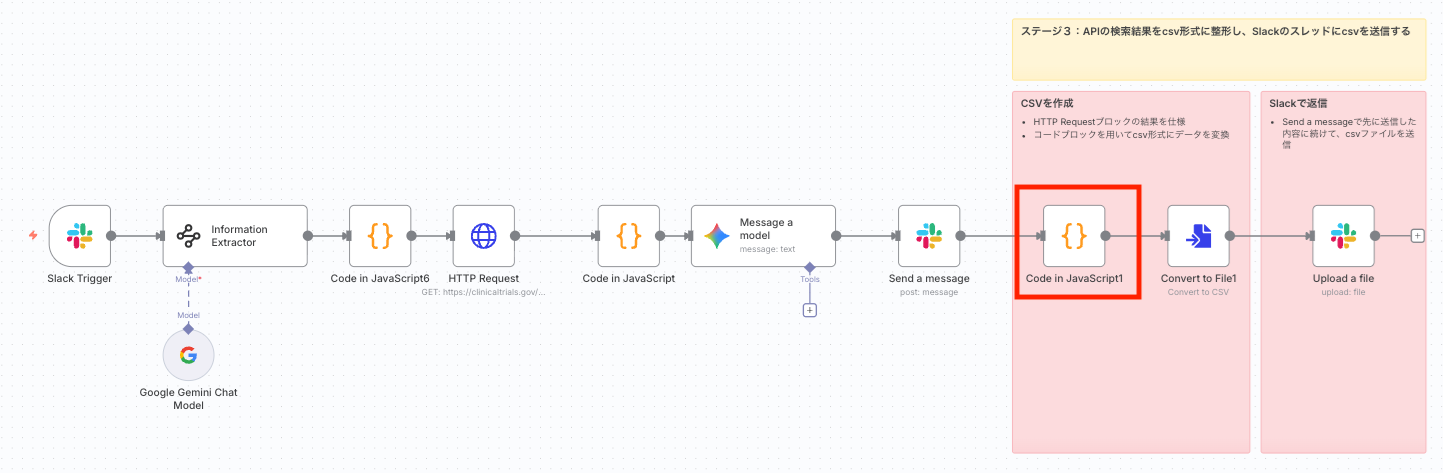
HTTP Requestノードで取得した生のJSONデータを、CSVファイル生成用に構造化します。
このノードは、HTTP Requestノードの出力を直接参照して処理を行います。
下記のコードは全てコピペで大丈夫です。
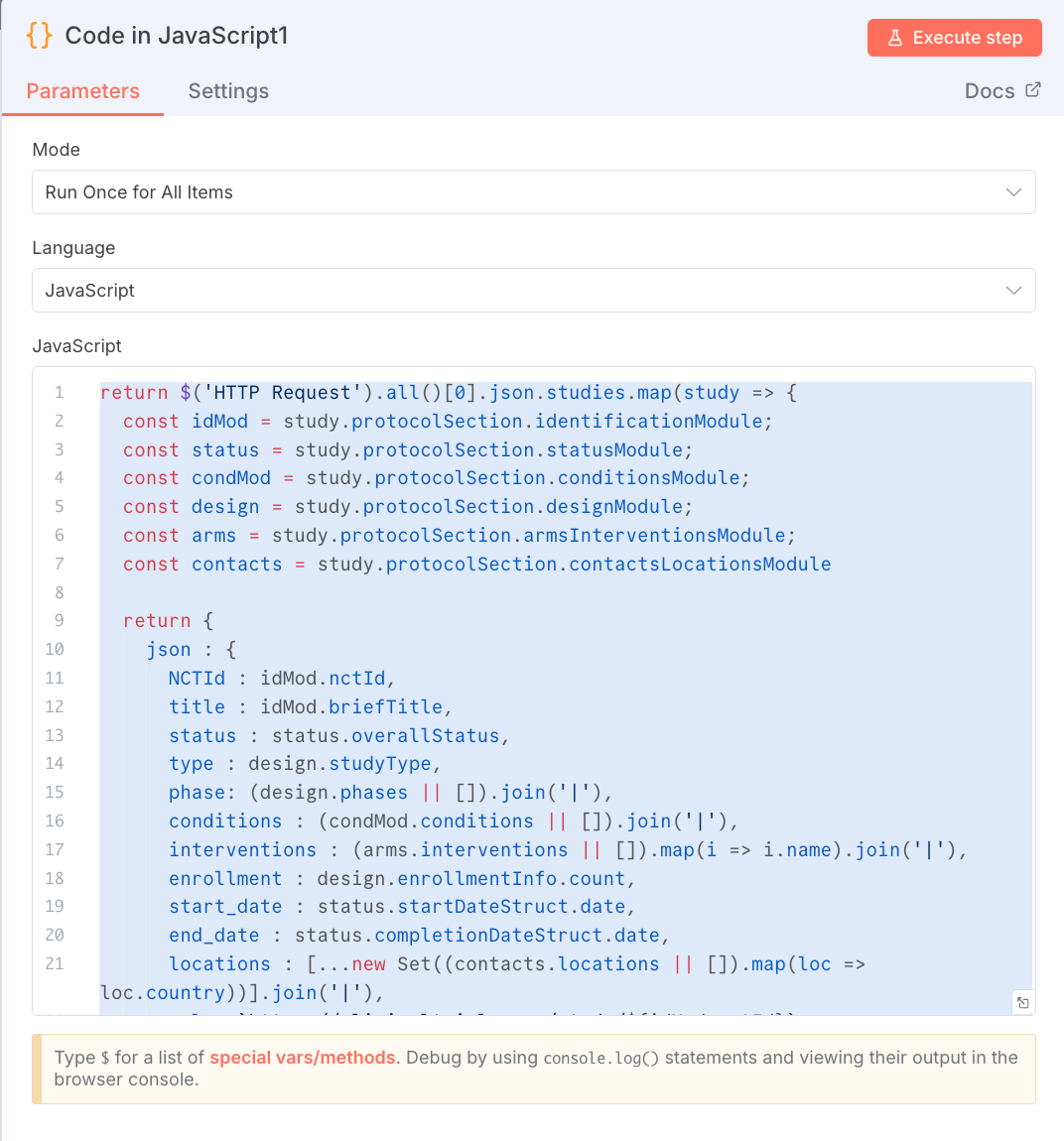
return $('HTTP Request').all()[0].json.studies.map(study ⇒ {
const idMod = study.protocolSection.identificationModule;
const status = study.protocolSection.statusModule;
const condMod = study.protocolSection.conditionsModule;
const design = study.protocolSection.designModule;
const arms = study.protocolSection.armsInterventionsModule;
const contacts = study.protocolSection.contactsLocationsModule
return {
json : {
NCTId : idMod.nctId,
title : idMod.briefTitle,
status : status.overallStatus,
type : design.studyType,
phase: (design.phases || []).join('|'),
conditions : (condMod.conditions || []).join('|'),
interventions : (arms.interventions || []).map(i ⇒ i.name).join('|'),
enrollment : design.enrollmentInfo.count,
start_date : status.startDateStruct.date,
end_date : status.completionDateStruct.date,
locations : [...new Set((contacts.locations || []).map(loc ⇒ loc.country))].join('|'),
url : `https://clinicaltrials.gov/study/${idMod.nctId}`
}
}
})
- 役割: APIから返された複数の試験データ( studies )をループ処理し、各試験の情報を構造化されたオブジェクトとして抽出します。各試験は独立したアイテムとして出力され、次のConvert to File1ノードでCSV形式に変換されます。
- 出力形式: 各試験が以下のようなデータに整形された状態で出力されます。
{
"NCTId": "NCT01234567",
"title": "試験のタイトル",
"status": "RECRUITING",
"type": "INTERVENTIONAL",
"phase": "PHASE2|PHASE3",
"conditions": "条件1|条件2",
"interventions": "介入1|介入2",
"enrollment": 100,
"start_date": "2024-01-01",
"end_date": "2025-12-31",
"locations": "United States|Japan",
"url": "<https://clinicaltrials.gov/study/NCT01234567>"
}
ポイント(応用):
- locations フィールドでは、 […new Set(…)] を使用して重複する国名を除去しています。
- interventions フィールドでは、介入情報の配列から name プロパティを抽出して結合しています。
- phase フィールドでは、複数のフェーズがある場合は
| で区切って結合しています。
- 格納先: 構造化されたオブジェクトの配列が、次のConvert to File1ノードに渡されます。
9. Convert to File1ノードでCSVファイルに変換
Code in JavaScript1ノードで生成された構造化データを、CSV形式のファイルに変換します。
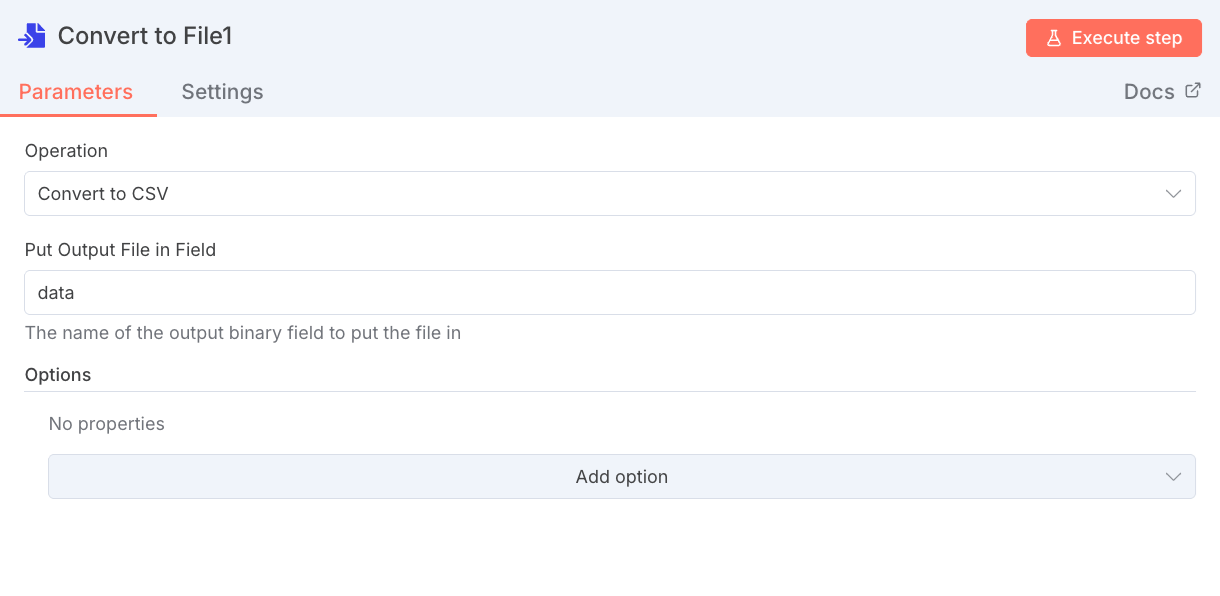
| 設定項目 | 値 | 役割 |
|---|---|---|
| File Format | csv | 出力ファイル形式をCSVに指定します。 |
- 役割: 構造化されたJSONデータの配列を、ExcelやGoogleスプレッドシートなどで開けるCSV形式のファイルに変換します。
- 入力: Code in JavaScript1ノードから渡された、各試験を表すオブジェクトの配列
- 出力: CSV形式のファイルオブジェクト(次のUpload a fileノードで使用可能な形式)
10. Upload a fileノードでSlackにCSVファイルをアップロード
Convert to File1ノードで生成されたCSVファイルを、元のメッセージが投稿されたチャンネルとスレッドにアップロードします。
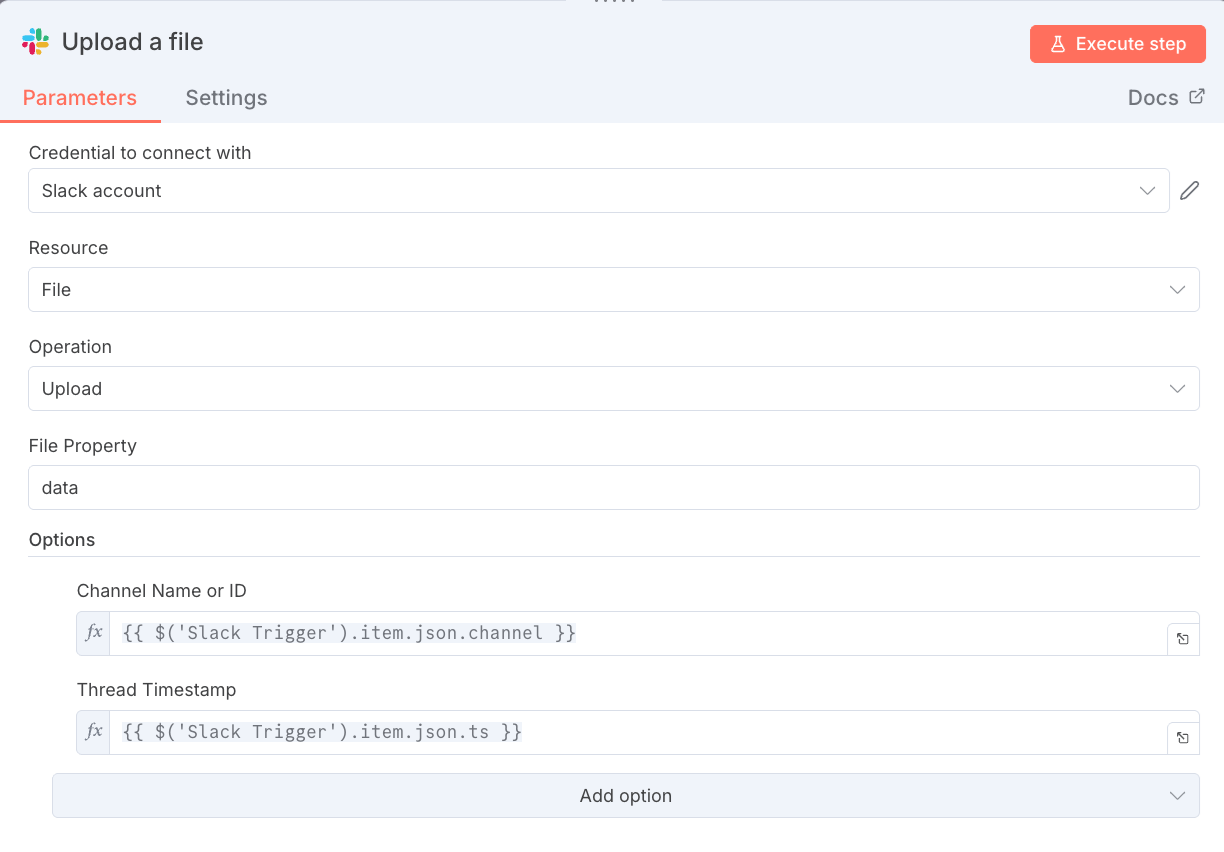
| 設定項目 | 値 | 役割 |
|---|---|---|
| Resource | file | ファイルをアップロードするという宣言です。 |
| Channel ID (Options) | ={{$(‘Slack Trigger’).item.json.channel }} | 元のメッセージが投稿されたチャンネルのIDを取得し、アップロード先とします。 |
| Thread TS (Options) | ={{$(‘Slack Trigger’).item.json.ts }} | 元のメッセージのタイムスタンプ( ts )を取得し、スレッドへの返信としてファイルをアップロードします。 |
- 役割: CSVファイルを、ユーザーがメンションしたSlackチャンネル内の元のメッセージのスレッドに添付ファイルとして投稿します。これにより、ユーザーは検索結果の一覧をスプレッドシート形式でダウンロード・分析することができます。
- その他:
- Options > Thread Timestampを追加しないと、チャンネルにそのまま普通のメッセージとして送信されてしまいます。最初にユーザーが質問をしたメッセージのts (タイムスタンプ)を挿入してあげることで、メッセージのリプライとして送信が可能です。
お疲れ様でした。ここまでで文章で検索するClinicalTrials.govワークフローは完成です。
拡張案:GoogleスプレッドシートやMicrosoft Excelへの出力
本ワークフローでは、CSVファイルをSlackに直接アップロードする方式を採用していますが、以下のような拡張も可能です。
各ツール(Google Cloud / Microsoft Online)の認証情報が必要なため、今回は利用を控えましたが、ビジネスでの実用性を考えるとSpreadsheetやExcelへの出力もチャレンジする価値はあると思います。
Googleスプレッドシートへの出力
- Google Sheetsノードを使用して、Code in JavaScript1の出力データを直接スプレッドシートに書き込みます。
- スプレッドシートの共有URLを生成し、そのURLをSlackメッセージに含めます。
Microsoft Excel(.xlsx)ファイルの生成
- Microsoft Excelノードを使用して、構造化データを直接Excelファイルとして生成します。
- 生成されたExcelファイルをSlackにアップロードします。

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら

監修者 株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中
連載シリーズ
ClinicalTrials.gov 治験情報を自然言語で取得するAIワークフロー


")