
ClinicalTrials.gov 治験情報を自然言語で取得するAIワークフロー Part2
連載シリーズ
ClinicalTrials.gov 治験情報を自然言語で取得するAIワークフロー
| 目次 |
ワークフローの全体イメージ
| 検索 | 結果 | UI | ||
|---|---|---|---|---|
| Part 1 | 自然言語からAPI検索を実施して要約 | 単語 | 要約 | Slack |
| Part 2 | 自然言語からAPI検索を行い、生成AIが要約まで実施 | 文章 | 要約 | Slack |
| Part 3 | 検索結果の一覧からcsvファイルと要約を生成する | 文章 | 要約 + csvファイル | Slack |
赤文字でハイライトされた箇所が、本記事で解説している部分です
Part2. 文章で質問すると情報を抽出して詳細なAPI検索を実施し、要約を返す
◆入力と回答のゴールイメージ
| Slack上での質問 | 得られる回答のイメージ |
|---|---|
| @ボットのメンション 小児喘息を対象とした第2相または第3相で、現在参加者を募集している治験のうち、最新のものから15件 | ご質問ありがとうございます。「糖尿病」に関連するClinicalTrials.govに登録されている臨床試験について、取得したデータに基づいてご説明いたします。提供されたデータによると、糖尿病に関連する様々な側面(診断、治療、合併症など)を対象とした複数の試験が実施されていることがわかります。これらには、観察研究と介入研究の両方が含まれており、中には既に完了したものや、これから参加者募集を開始する予定の試験もあります。 以下に、抽出された疾患名や条件をもとに、具体的な試験内容を要約してご紹介します。 ### 1. 糖尿病性心血管合併症に関する研究* **Diabetic Cardiovascular Complications: Multi-Omics Analysis** (ID: NCT06824233) * **概要**: 糖尿病患者における心血管合併症について、マルチオミクス解析を用いて研究する観察研究です。糖尿病が心血管系に与える影響を多角的に解析することを目指しています。 * ** ステータス**: 2025年3月1日から募集開始予定 (NOT_YET_RECRUITING)です。 * **詳細**: 血管系に与える影響を多角的に解析することを目指しています。 * ** ステータス**: 2025年3月1日から募集開始予定 (NOT_YET_RECRUITING)です。 * **詳細**: [https://clinicaltrials.gov/study/NCT06824233] (https://clinicaltrials.gov/study/NCT06824233) **Genetic Markers of Coronary Heart Disease in Type 2 Diabetes** (ID: NCT00078052) * **概要**: 2型糖尿病患者における冠状動脈性心臓病の遺伝子マーカーを特定するための観察研究です。大規模な参加者 (12万人)を対象として実施されました。 * **ステータス**: 完了済み (COMPLETED)です。 * **詳細**: [https://clinicaltrials.gov/study/NCT00078052] (https://clinicaltrials.gov/study/NCT00078052) ### 2. 糖尿病性合併症の治療に関する研究 … (中略) ### まとめ 現在、ClinicalTrials.govには、糖尿病の診断、様々な合併症(心血管疾患、足潰瘍、網膜症、神経障害など)の治療法開発、特定の糖尿病タイプ(1型、2型、前糖尿病)への介入、および血糖モニタリング技術の評価など、多岐にわたる研究が登録されています。ほとんどの試験は既に完了していますが、「Diabetic Cardiovascular Complications: Multi-Omics Analysis (ID: NCT06824233)」は2025年3月から募集開始予定です。 これらの情報が、糖尿病に関する臨床試験の理解の一助となれば幸いです。 |
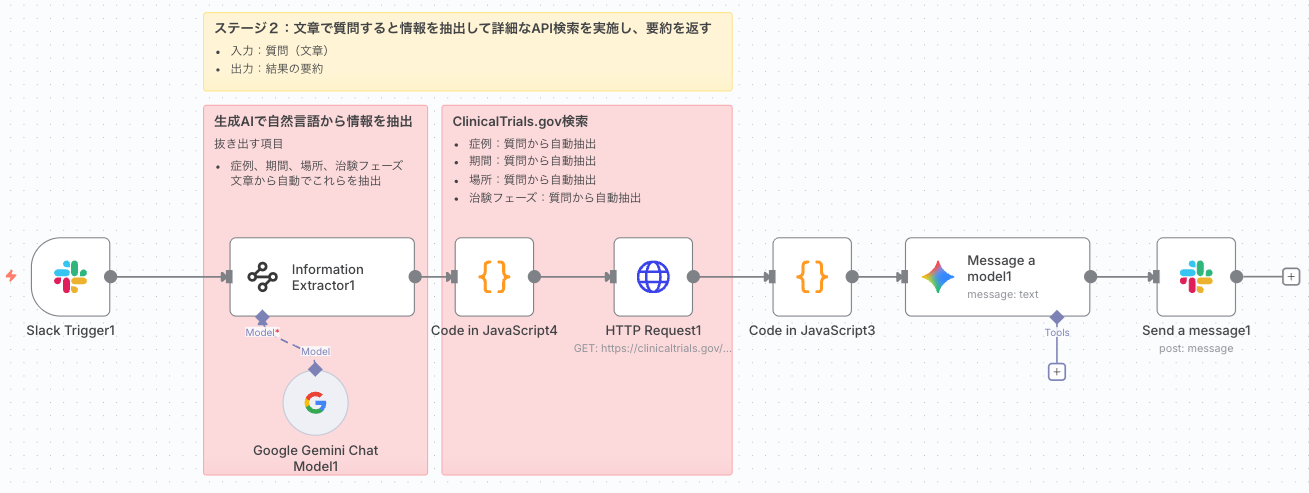
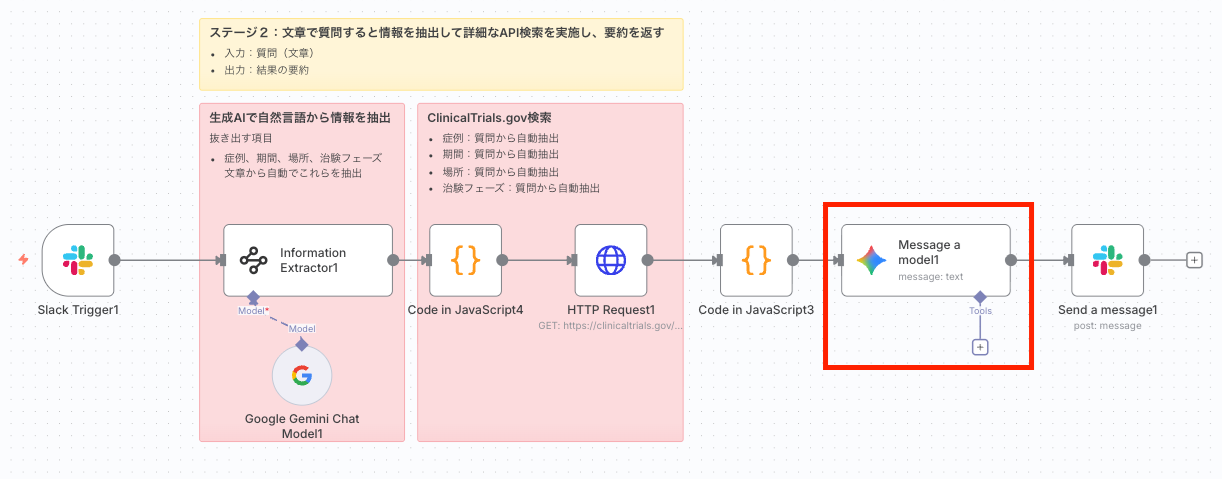
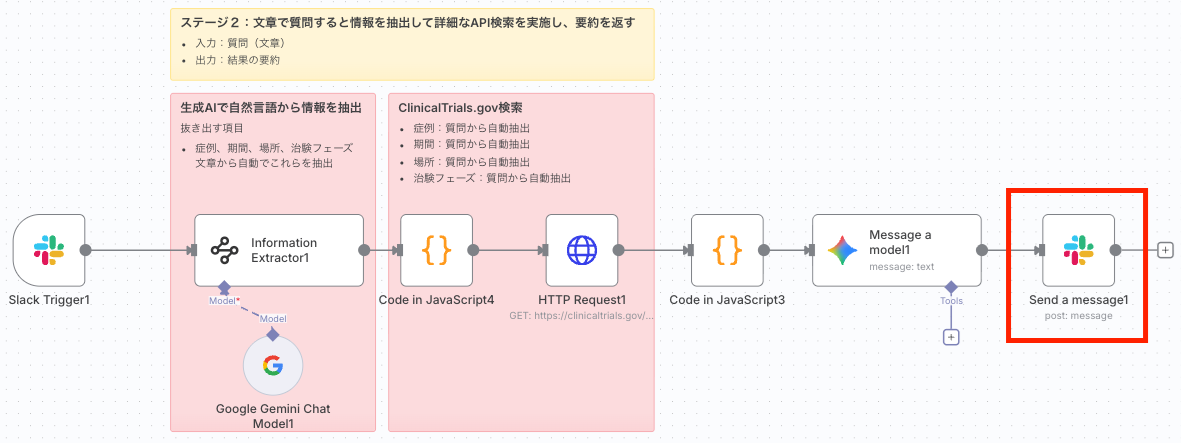
<ワークフローの流れ>
- Slack Trigger: Slackへのメンションをトリガーにワークフローを開始。
- Information Extractor: ユーザーの質問から、AIがClinicalTrials.govの検索クエリパラメータを抽出。
- Code in JavaScript6: 抽出されたパラメータから空の項目を削除しJSONを整形。
- HTTP Request: 整形されたクエリパラメータを用いてClinicalTrials.gov APIを検索。
- Code in JavaScript: 取得した臨床試験データを整形し、AI向けに要約。
- Message a model: Geminiモデルが要約されたデータとユーザーの質問に基づき回答を生成。
- Send a message: 生成された回答をSlackに返信。
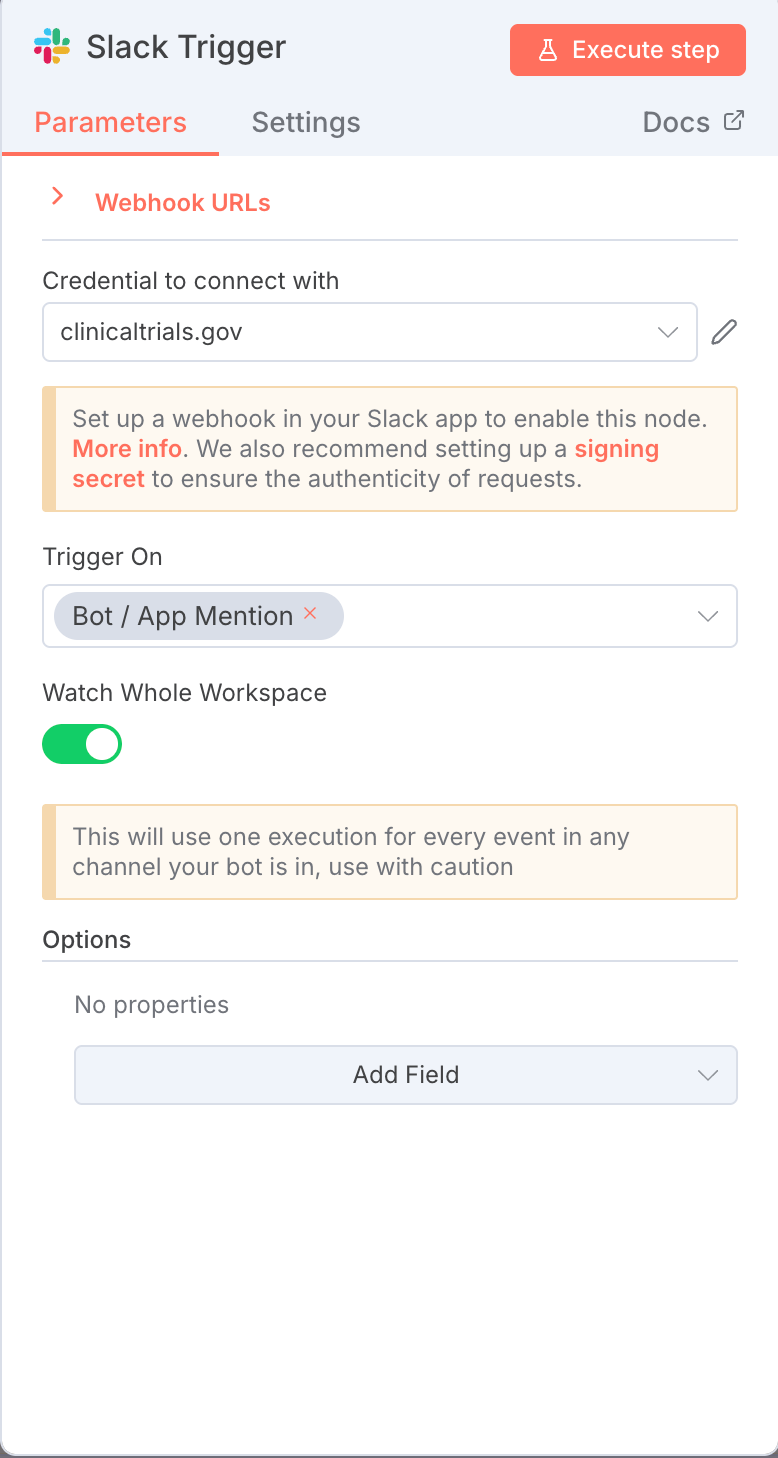
1. Slack Triggerノードでワークフロー起動
このノードは、ワークフローの起点となる部分です。
| 設定項目 | 値 | 役割 |
|---|---|---|
| Trigger | app_mention | Slack上でこのn8nボットにメンションがあったときにワークフローを起動します。 |
| Watch Whole Workspace | true(緑色になっている状態が正しい状態) | ワークスペース全体のメンションを監視します。 |
| Name | Sack Trigger | – |
- 役割: Slack上にインストールされたn8nボットアカウントに対してメンションを行うことで、ワークフローを起動します。
- 期待するメッセージ形式:
@ボットのアカウント名 小児喘息を対象とした第2相または第3相で、現在参加者を募集している治験のうち、最新のものから15件
- 注意点:
- メンションの後、必ず改行を入れてから検索したい疾患名(条件)やその他の検索指示を入力してください。
- 前記事と同じで「Watch Whole Workspace」はONにしておいてください。
2. Information Extractorノードで検索条件を抽出
ここが本記事で最も重要なノードになります。文章形式で自然言語を投げてあなたの意図を読み取ってAPI検索を行うための土台になるノードです。
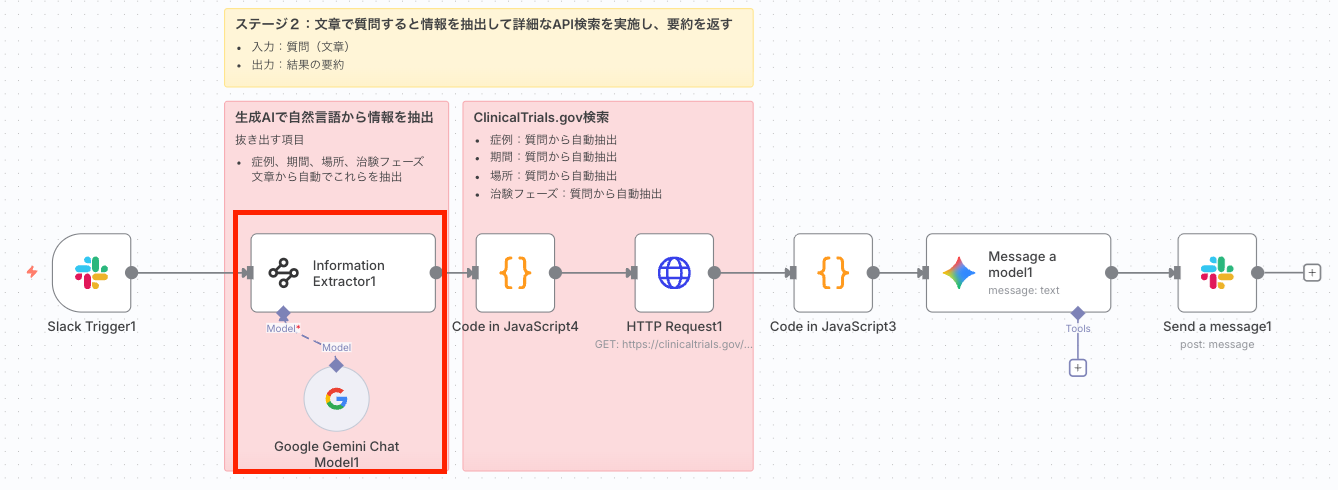
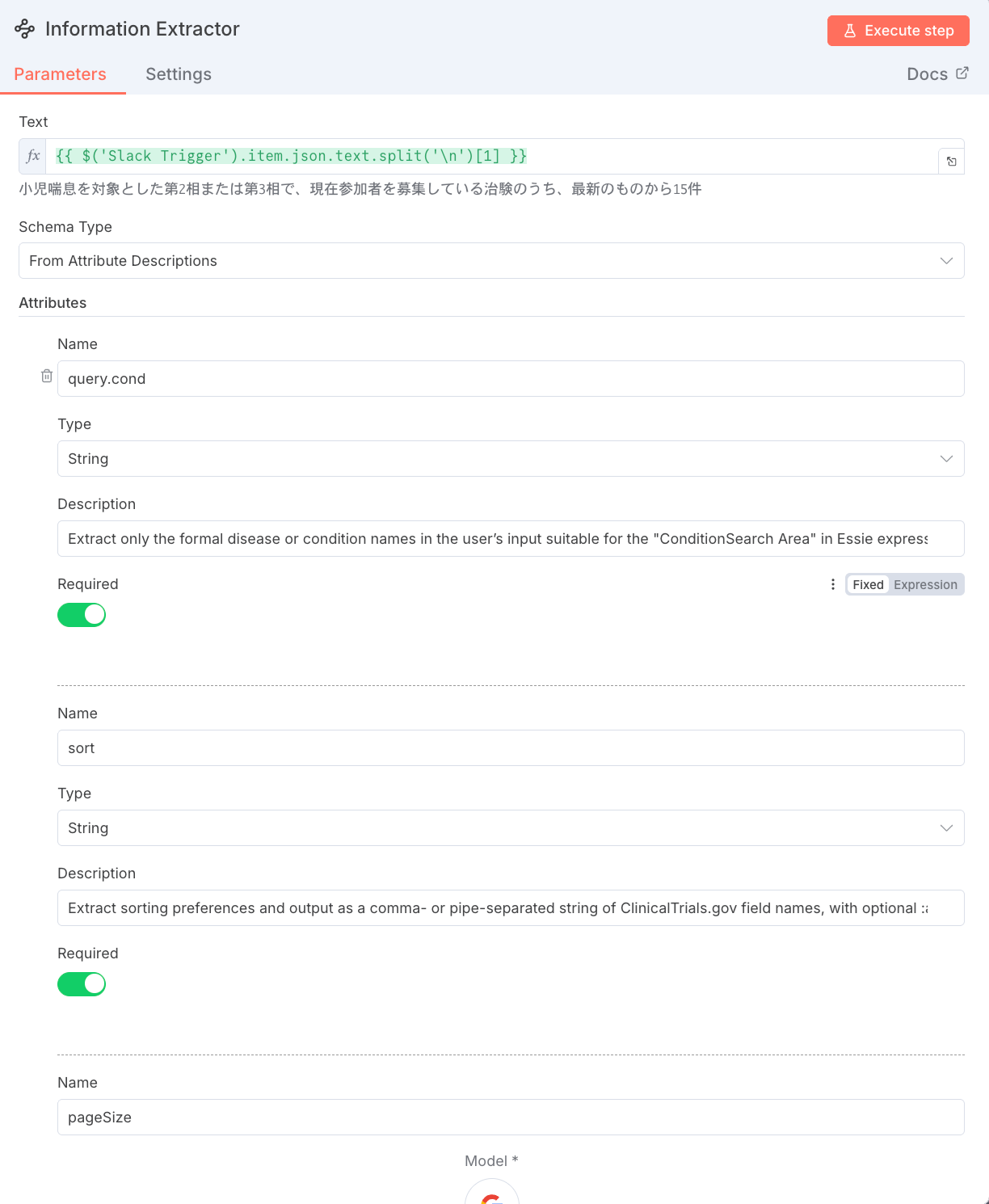
このノードは、ユーザーの自然言語の質問を、ClinicalTrials.gov API が理解できる厳密なクエリパラメータに変換します。
- 入力テキスト:
={{$('Slack Trigger').item.json.text.split('\n')[1] }}- Slackメッセージの改行以降(2行目)のテキストが入力されます。
- 役割: ユーザーの質問(例: 「第3相の治験を15件、日本で」)から、疾患名(
query.cond)、件数(pageSize)、並び順(sort)、高度なフィルタ(filter.advancedなど)といった複数の要素をAIが解析し、次のノードへJSON形式で出力します。
以下の「項目」「必須」「抽出指示」をそれぞれInformation Extrractorのフィールドに抽出してください。
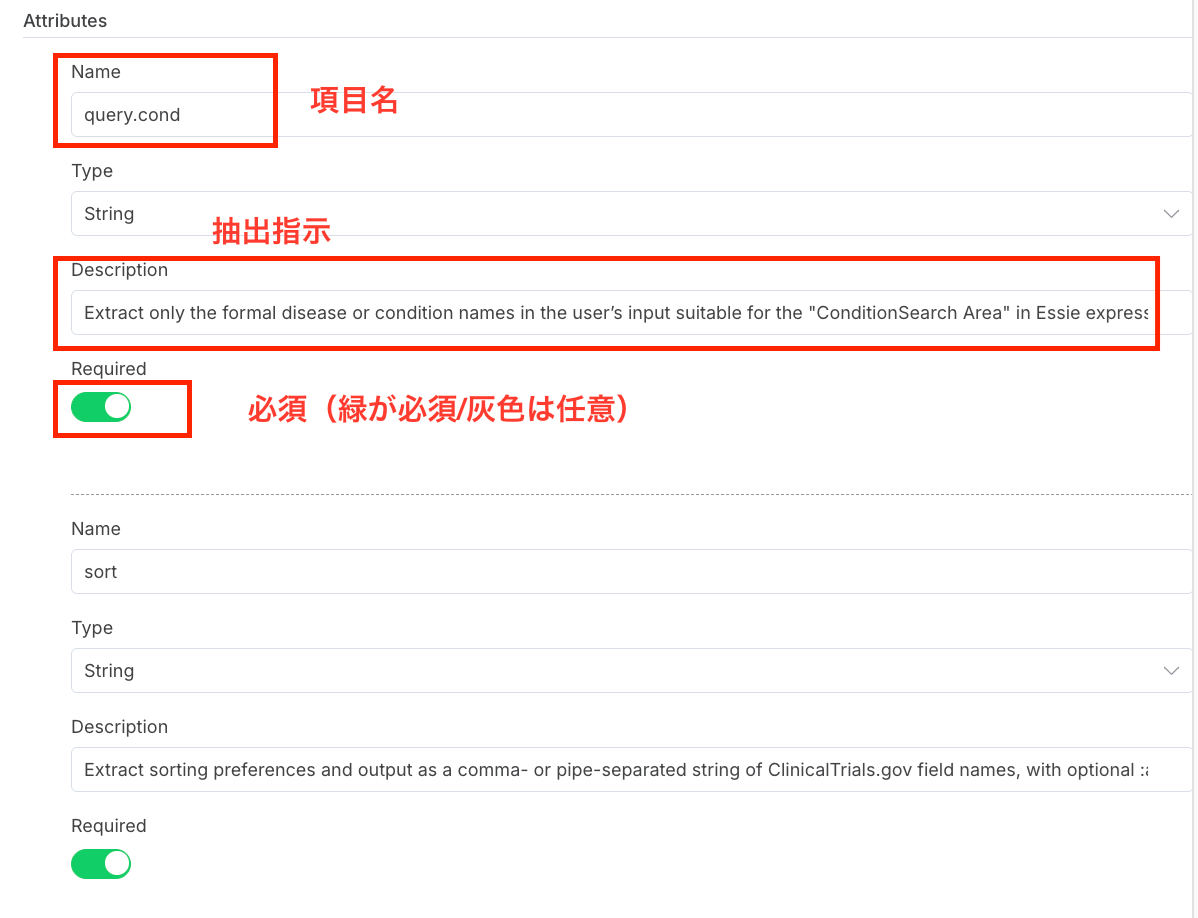
以下は全てコピペで大丈夫です。
| 項目名 (Name) | 必須 (Required) | Description (抽出指示) |
|---|---|---|
| query.cond | 必須 | Extract only the formal disease or condition names in the userʼs input suitable for the “ConditionSearch Area” in Essie expression syntax. Return as valid Essie expressions (e.g. diabetes, (lung OR breast) AND cancer). If in Japanese, translate to English. |
| sort | 必須 | Extract sorting preferences and output as a comma- or pipe-separated string of ClinicalTrials.gov field names, with optional :asc or :desc , and without brackets or array syntax. Example: “@relevance” , “EnrollmentCount:desc,NumArmGroups” , “LastUpdatePostDate” . Return as a plain string, not a JSON array. |
| pageSize | 必須 | If the user specifies the number of results desired, extract and return as pageSize(e.g., “一覧で10件” → pageSize: 10). Default to 10 if unspecified. |
| query.term | 任意 | Extract other relevant search terms (e.g., symptoms,findings, study context) for “BasicSearch Area” in Essiesyntax. Return as valid Essie expressions (e.g., AREA[LastUpdatePostDate]RANGE[2023-01-01,MAX] ). If in Japanese, translate as needed. |
| query.locn | 任意 | Extract location (country, region, city, etc.) relevant for “LocationSearch Area” in Essie syntax. Return as AREA expressions (e.g., AREA[LocationCountry]Japan AND AREA[LocationStatus]Recruiting ). Translate to English. |
| query.intr | 任意 | Extract intervention/treatment names, medical devices,or substance keywords from user input for “InterventionSearch Area”. Return as AREA expressions (e.g., AREA[InterventionName]Liraglutide ). Translate toofficial English values. |
| query.id | 任意 | Extract study IDs (NCT numbers, aliases), return as IDs or AREA expressions as appropriate. E.g., NCT01234567 or AREA[NCTIdAlias]JP12345 |
| filter.overallStatus | 任意 | Extract specific recruitment statuses (e.g., “募集中”, “完了” etc.), map to allowed API status codes and return asarray, e.g., RECRUITING, COMPLETED. Use official allowedvalues: ACTIVE_NOT_RECRUITING, COMPLETED, ENROLLING_BY_INVITATION, NOT_YET_RECRUITING, RECRUITING, SUSPENDED, TERMINATED, WITHDRAWN, AVAILABLE, NO_LONGER_AVAILABLE, TEMPORARILY_NOT_AVAILABLE, APPROVED_FOR_MARKETING, WITHHELD, UNKNOWN. |
| filter.advanced | 任意 | Extract any advanced area+operator expressions from the user’s input and return as valid Essie expressions for ClinicalTrials.gov API. For any field that uses enumeratedvalues (such as trial phase), always translate user input (e.g., “第3相”) to the enum value from this list: NA, EARLY_PHASE1, PHASE1, PHASE2, PHASE3, PHASE4, output in the format AREA[Phase]PHASE3. |
3. Code in JavaScriptノードでクエリを整形
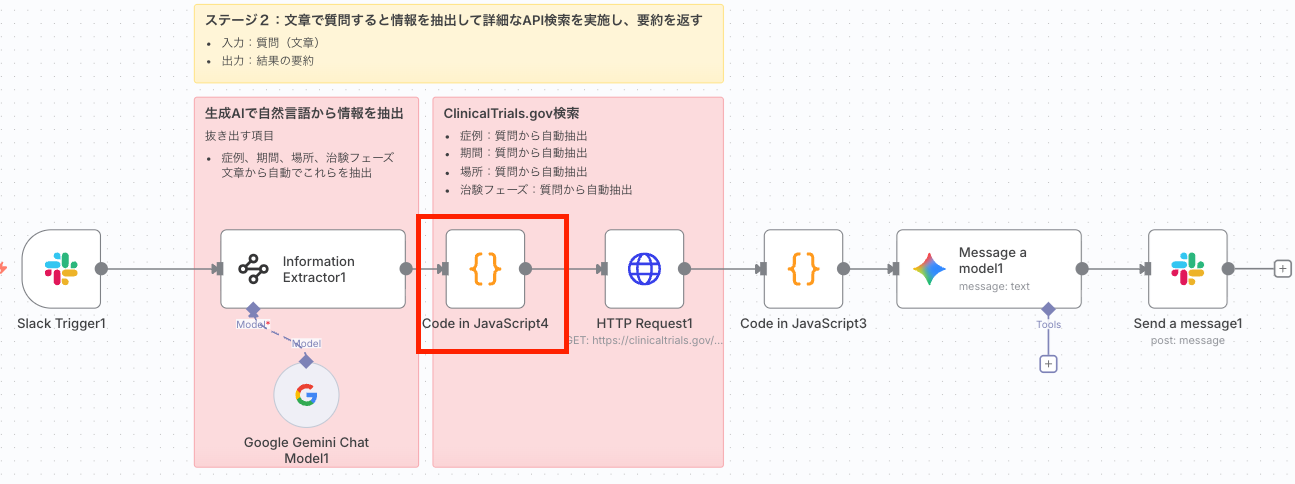
Information Extractorノードの出力には、ユーザーが指定しなかった空の検索パラメータも含まれます。このノードは、それらの不要な空のパラメータを削除し、APIリクエスト用のクリーンなJSONオブジェクトを作成します。この作業をしないとHTTP RequestノードでAPI検索を行う時に、どうしてもエラーが発生してしまいます。
let output = $json.output||{};
let results = {
'query.cond':output['query.cond']||"",
// ... 他のパラメータの初期化 ...
};
const filtered = Object.fromEntries(
Object.entries(results).filter(([k,v])=>
v!==""&&v!=null
);
return{json:filtered};
- 役割: Information Extractorノードから受け取ったデータから、値が空でない( “” や null ではない)パラメータだけを抽出します。
- 目的: 必要な検索条件のみを次のHTTP Requestノードに渡すことで、APIへのリクエストを最適化し、正確な検索結果を得るための前処理を行います。
4. HTTP RequestノードでAPIを検索
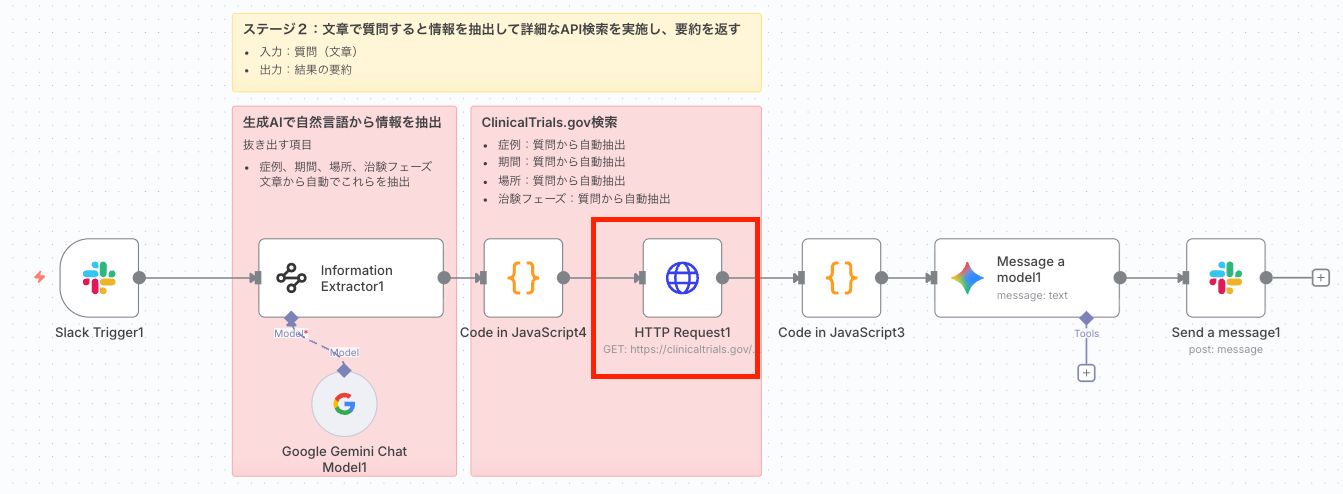
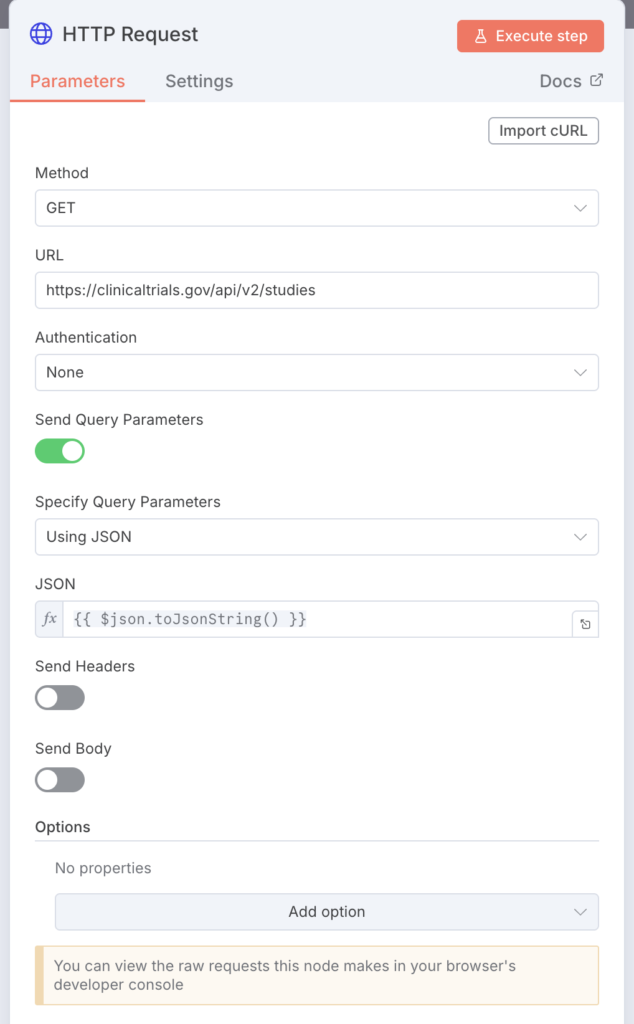
Code in JavaScript6ノードで整形されたクエリパラメータを用いて、「ClinicalTrials.gov」のAPIを呼び出し、臨床試験データを取得します。
| 設定項目 | 値 | 役割 |
|---|---|---|
| URL | https://clinicaltrials.gov/api/v2/studies | ClinicalTrials.govのAPIエンドポイントです。 |
| Send Query | true | クエリパラメータを付けてリクエストを送信します。 |
| Specify Query | json | 前のノードから渡されたJSONオブジェクト全体をクエリとして使用することを指定します。 |
| JSON Query | ={{$json.toJsonString()}} | Code in JavaScript6ノードから受け取った動的な検索パラメータ(JSON)を文字列化して、リクエストに含めます。 |
- 役割: AIが抽出した複雑で動的な検索条件を一括でAPIに渡し、最新の臨床試験データ(JSON形式)を取得します。
5. Code in JavaScriptノードでデータを整形
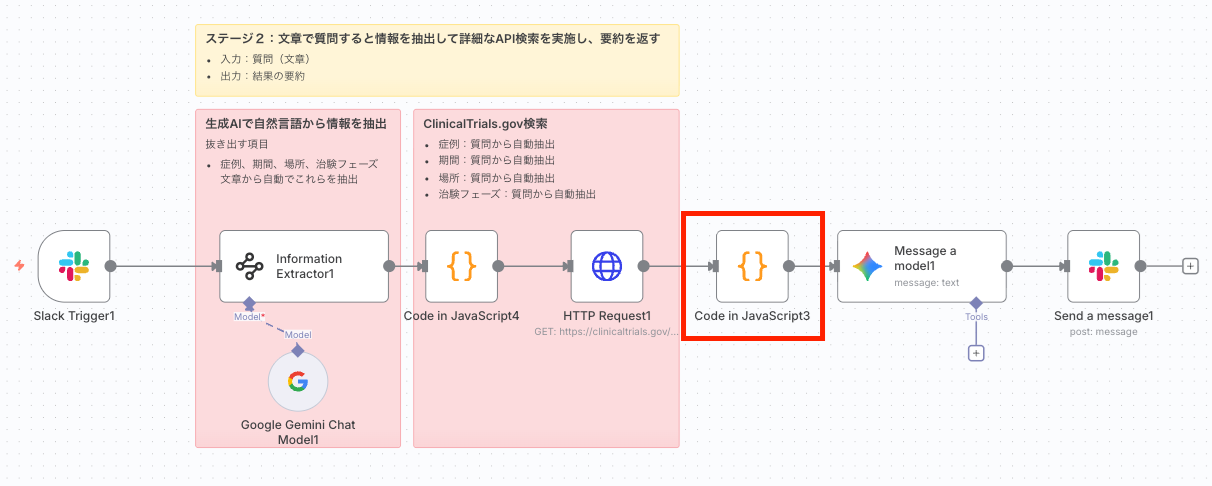
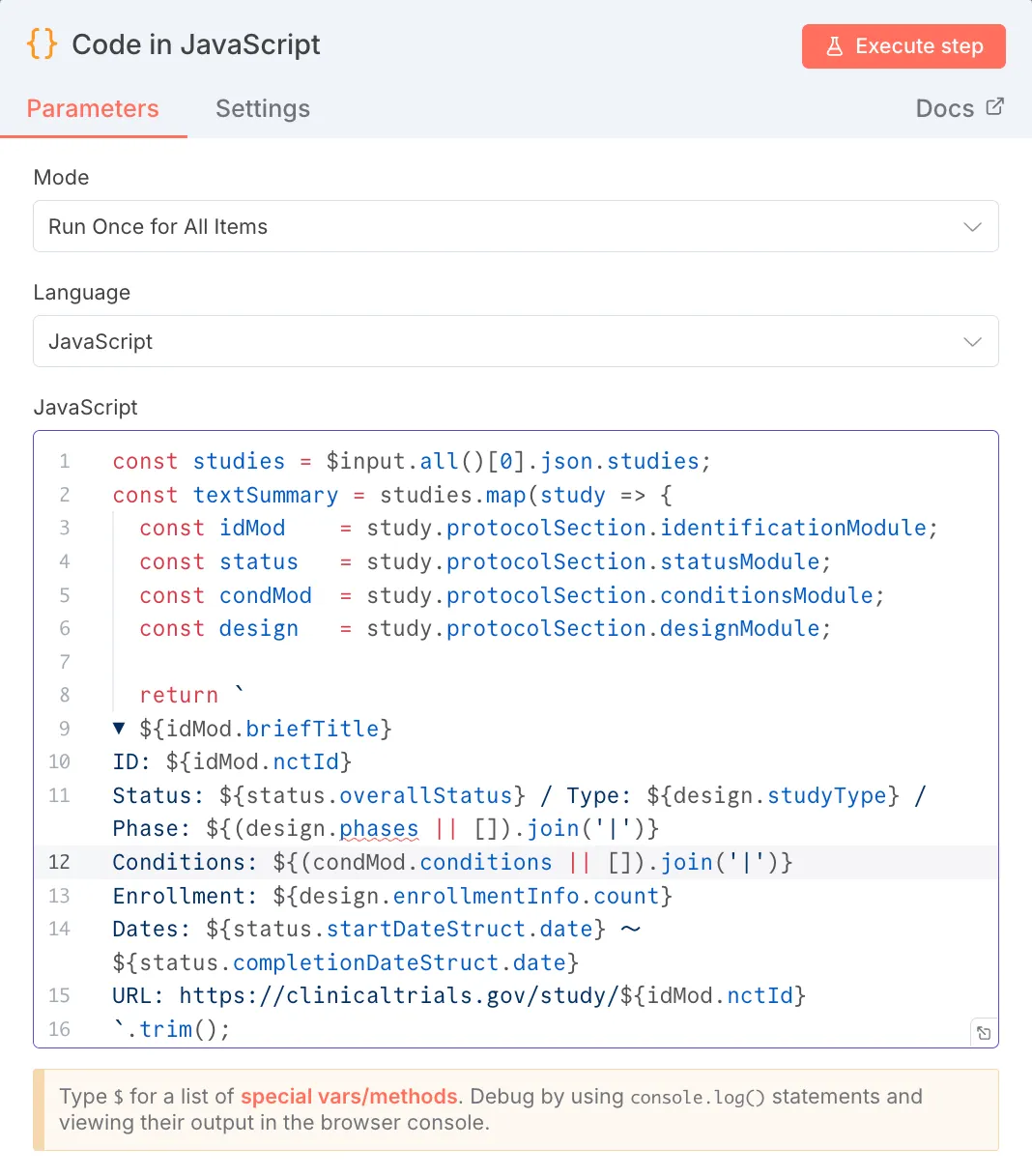
HTTP Requestノードで取得した生のJSONデータを、次のAIノードが処理しやすいように、また最終的な回答に含めるために必要な情報だけを抽出・整形します。
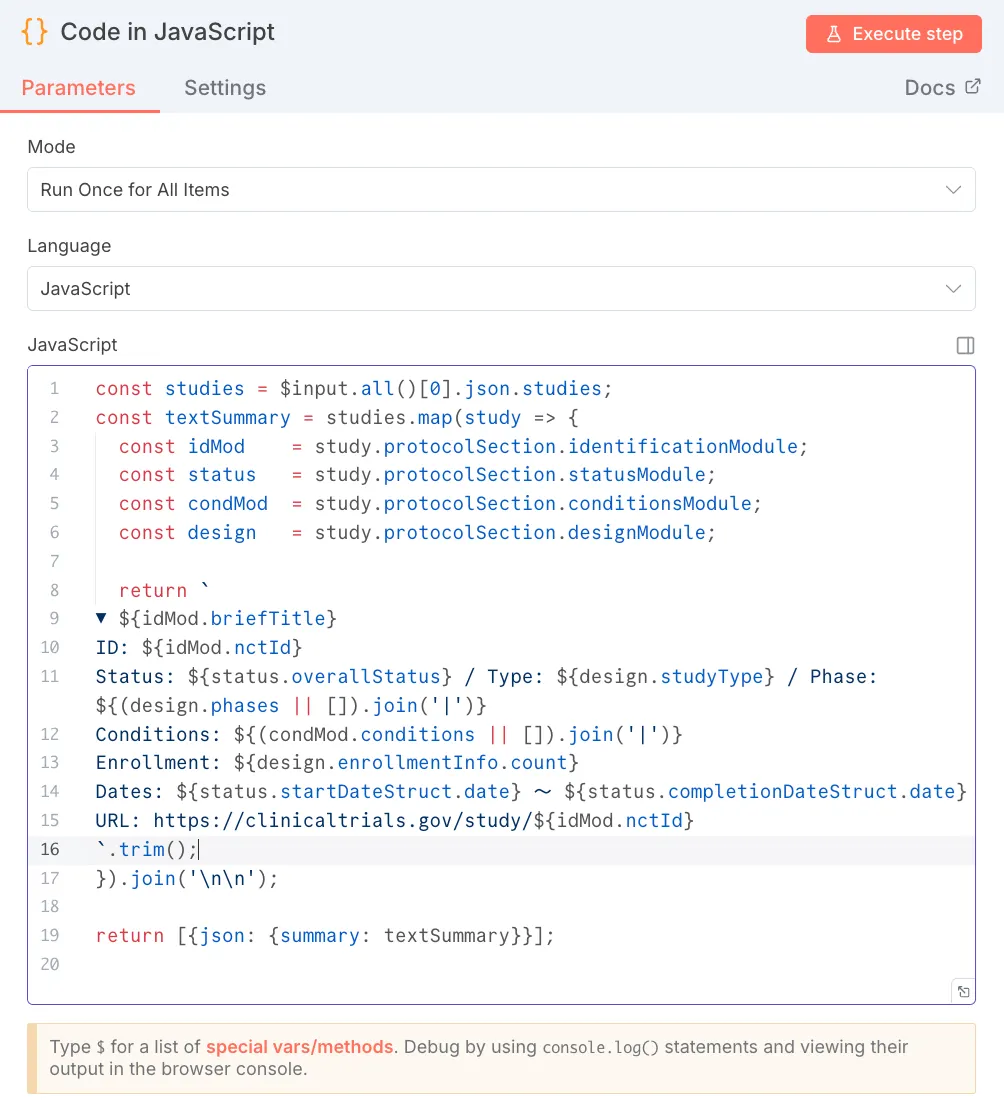
const studies = $input.all()[0].json.studies;
// ... (中略) ...
return `
▼ ${idMod.briefTitle}
ID: ${idMod.nctId}
Status: ${status.overallStatus} / Type: ${design.studyType} / Phase: ${(design.phases || []).join('|')}
Conditions: ${(condMod.conditions || []).join('|')}
// ... (後略) ...
`.trim();
}).join('\n\n');
return [{json: {summary: textSummary}}];
 役割: APIから返された複数の試験データ(studies)をループ処理し、各試験のタイトル、ID、ステータス、フェーズ、条件、登録者数、期間、URLなどの主要情報を抽出し、読みやすいテキスト形式に結合します。
役割: APIから返された複数の試験データ(studies)をループ処理し、各試験のタイトル、ID、ステータス、フェーズ、条件、登録者数、期間、URLなどの主要情報を抽出し、読みやすいテキスト形式に結合します。- 出力形式: 以下の形式で、各試験の要約が\n\nで区切られて連なります。
▼ [試験のタイトル]
ID: [NCT ID]
…
URL: https://clinicaltrials.gov/study/[NCT ID]
- 格納先: 整形されたテキストは、 summary というキーを持つJSONオブジェクトとして次のノードに渡されます。
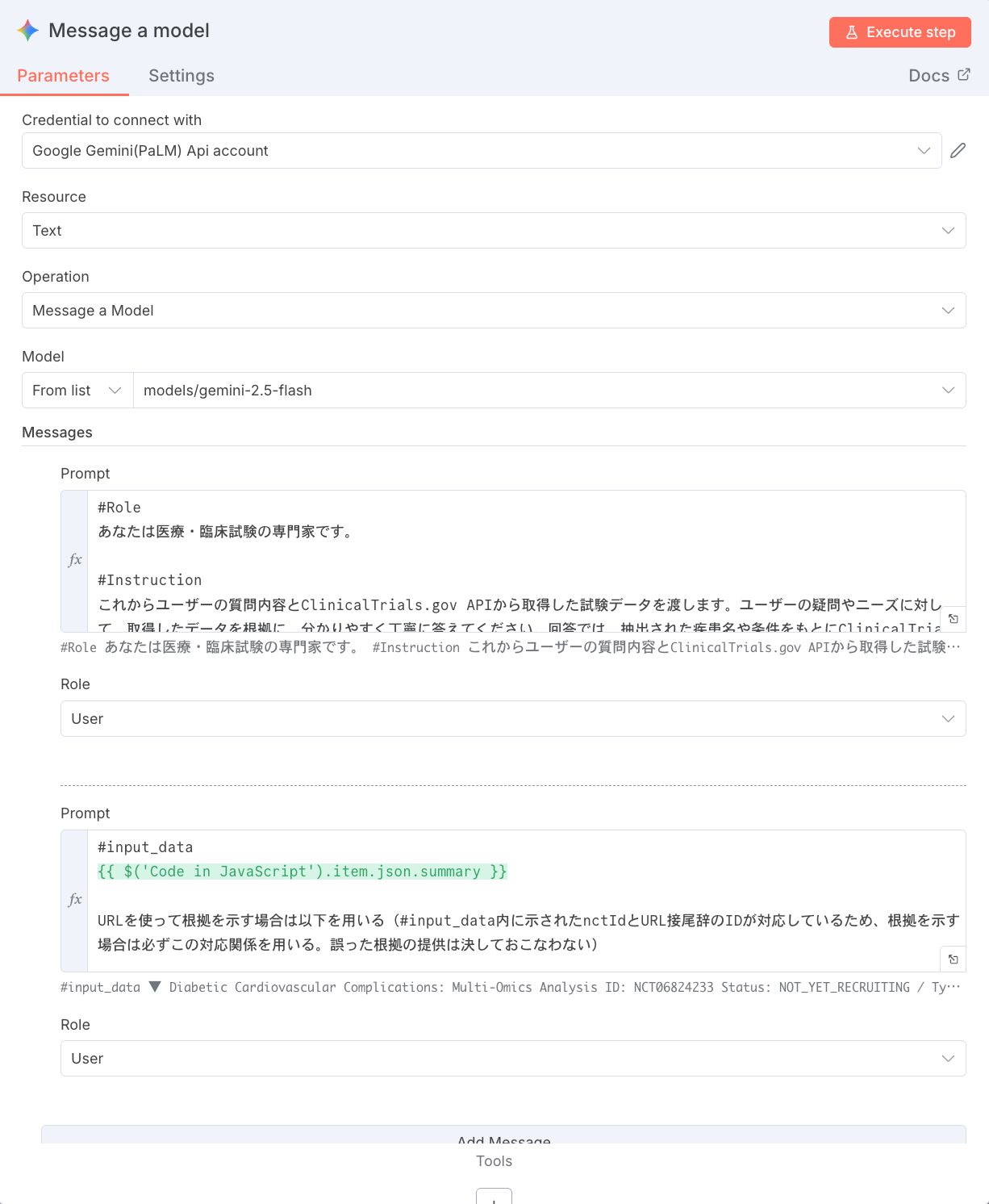
6. Message a modelノードでAIが回答を生成
整形された臨床試験データとユーザーの元の質問に基づき生成AIが専門家として回答文を生成します。
| 設定項目 | 値 | 役割 |
|---|---|---|
| Model ID | models/gemini-2.5-flash | 使用するAIモデルを指定します。 |
| Messages | 2つのプロンプトを設定 | AIへの指示と入力データを渡します。 |
◆プロンプト(AIへの指示とデータ)の詳細
- システムプロンプト (役割と指示):
#Role あなたは医療・臨床試験の専門家です。 #Instruction これからユーザーの質問内容とClinicalTrials.gov APIから取得した試験データを渡します。 ユーザーの疑問やニーズに対して、取得したデータを根拠に、分かりやすく丁寧に答えてください。 回答では、抽出された疾患名や条件をもとにClinicalTrials.govの試験内容を要約し、質問に沿って解説してくださ い。 与えられた情報以外の情報は絶対に含めないでください。専門家として確実に正しい根拠のある情報のみを提出してください。 仮に、与えられたデータで回答することが困難な場合は、ユーザーに別の質問方法を促してください。 文章は必ず日本語で生成してください。 治験のタイトルなども示しながら、どのような治験が存在するかを説明してください。
AIに医療・臨床試験の専門家としての役割を与え、与えられたデータのみに基づき、分かりやすく根拠のある回答を生成するように厳しく指示しています。
- ユーザープロンプト (入力データ):
#input_data
{{ $('Code in JavaScript').item.json.summary }}
URLを使って根拠を示す場合は以下を用いる
(#input_data内に示されたnctIdとURL接尾辞のIDが対応しているため、
根拠を示す場合は必ずこの対応関係を用いる。誤った根拠の提供は決しておこなわない)
#user_query
{{ $('Slack Trigger').item.json.text.split('\n')[1]}}
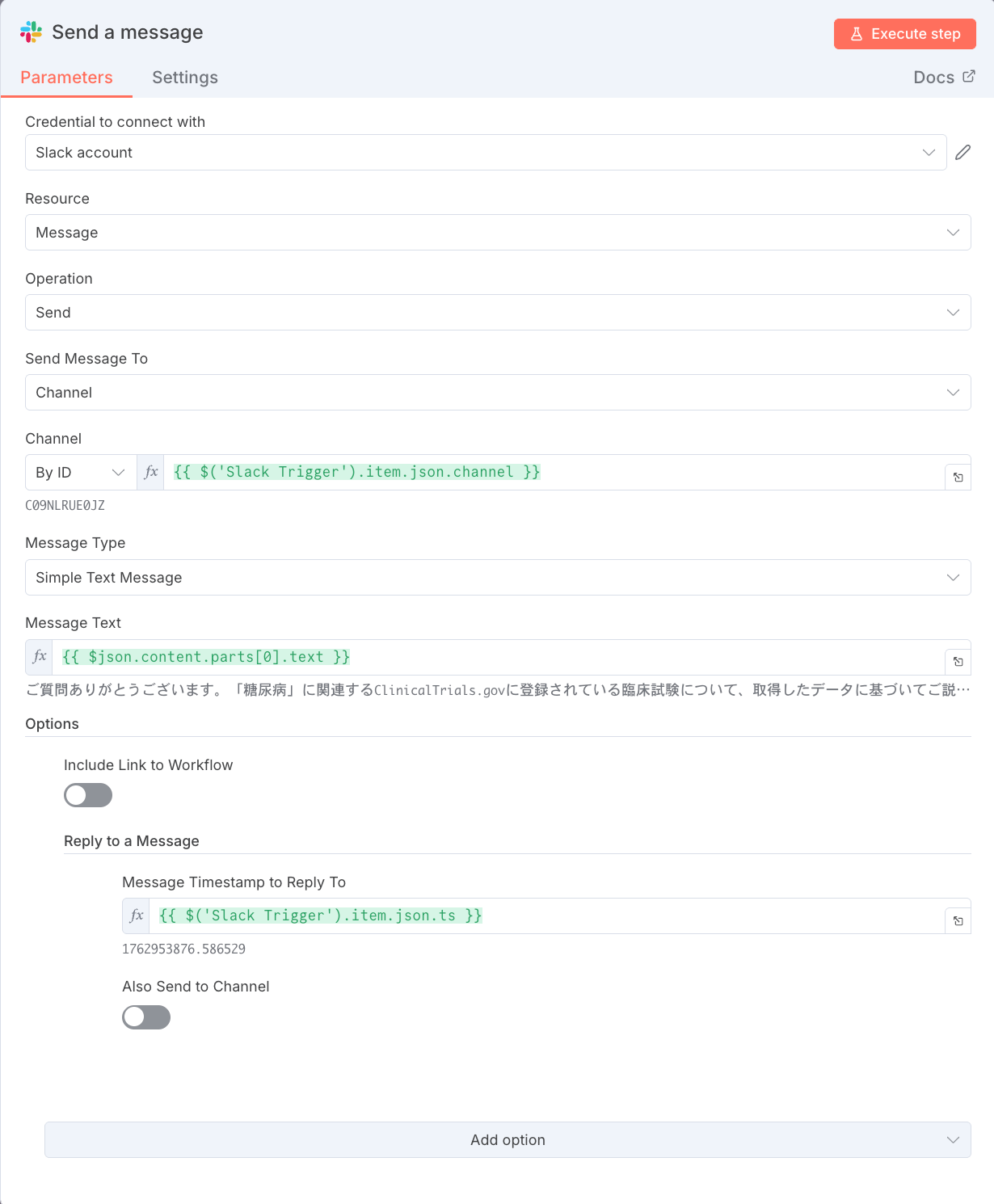
7. Send a messageノードでSlackに返信
AIが生成した回答を、元のメッセージが投稿されたチャンネルとスレッドに返信します。
| 設定項目 | 値 | 役割 |
|---|---|---|
| Send Message to | channel | 投稿先としてチャンネルを指定します。 |
| Channel ID | ={{$(‘SlackTrigger’).item.json.channel }} | 元のメッセージが投稿されたチャンネルのIDを取得し、返信先とします。 |
| Text | ={{$json.content.parts[0].text }} | AIノード(Message a model)で生成された回答テキストを取得します。 |
| thread_ts (Reply Values) | ={{$(‘Slack Trigger’).item.json.ts }} | 元のメッセージのタイムスタンプ( ts )を取得し、スレッドへの返信として投稿します。 |
- 役割: AIによって生成された最終回答を、ユーザーがメンションしたSlackチャンネル内の元のメッセージのスレッドに投稿し、会話を完結させます。

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら

監修者 株式会社ヘルツレーベン代表 木下 渉
株式会社ヘルツレーベン 代表取締役/医療・製薬・医療機器領域に特化したDXコンサルタント/
横浜市立大学大学院 ヘルスデータサイエンス研究科 修了
製薬・医療機器企業向けのデータ利活用支援、提案代行、営業戦略支援を中心に、医療従事者向けのデジタルスキル教育にも取り組む。AI・データ活用の専門家として、企業研修、プロジェクトPMO、生成AI導入支援など幅広く活動中
連載シリーズ
ClinicalTrials.gov 治験情報を自然言語で取得するAIワークフロー


")