
ライフサイエンス企業検索・リサーチBot Part1
| 目次 |
1. 導入
ライフサイエンス業界では、製薬・医療機器・バイオテック・ヘルスケアSaaSといった多様なプレイヤーが、急速な技術革新とパートナーシップの変化を続けています。
市場調査・提携分析・営業戦略立案において、「特定企業の最新情報をすぐに調べたい」というニーズは日常的に発生します。
しかし、実際にはニュースサイトやIRページを複数回り、情報を整理して報告書を作るには手間がかかります。
本記事では、そのような課題を解決するために構築した 「企業検索ボット」 の仕組みを紹介します。
このボットは、企業名を入力するだけで自動的にWeb検索→スクレイピング→要約→レポート出力までを実行します。
すべてノーコードで構築できるため、分析者・リサーチャー・営業担当者が誰でも導入可能です。
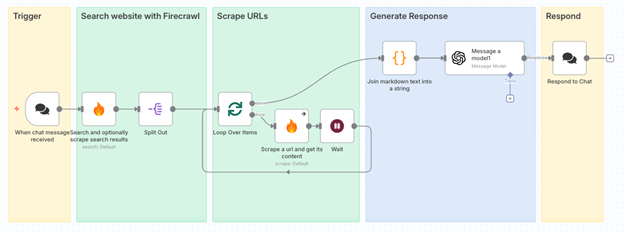
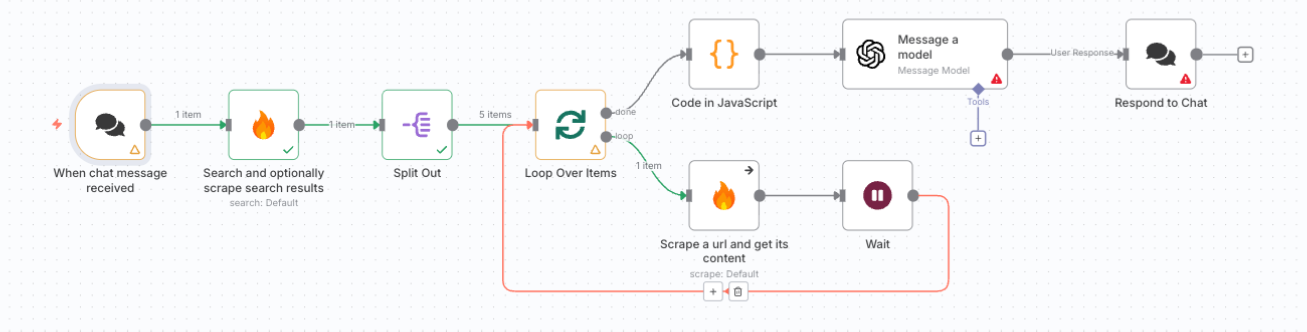
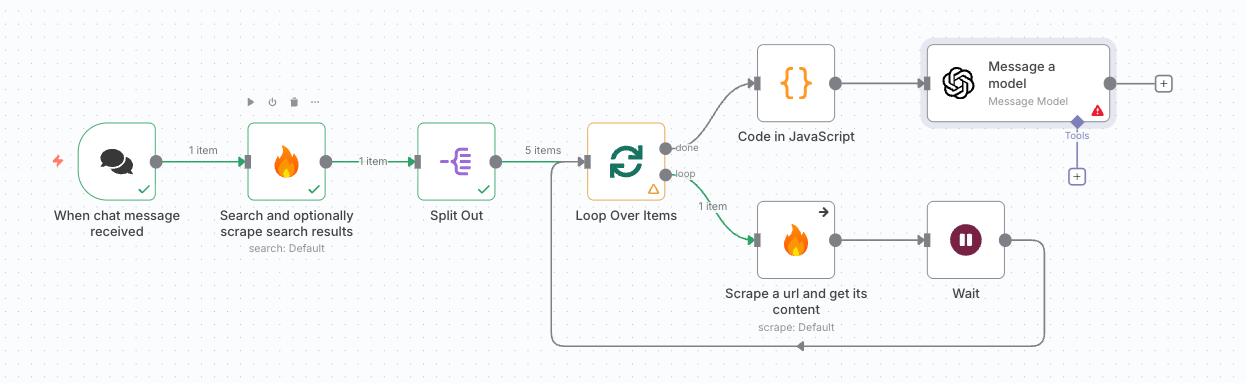
2. ワークフロー全体像
企業名をフックに、Web検索から企業分析レポートを自動生成する流れは以下の通りです。
- メッセージを受信してワークフローを起動
- FirecrawlでWeb検索を実行し、複数のURLを取得
- 取得したURL群をループ処理してスクレイピング
- 収集結果をOpenAIに渡して要約レポートを生成
- n8nのチャット画面または外部アプリ(Slackなど)に結果を返却
3. n8n設定の基本構造
3.1 トリガー設定
最初のノードとして
「When Chat Message Received」 を使用。
これにより、n8n内のチャット画面で企業名を入力するとワークフローが起動します。
4. FirecrawlによるWeb検索
4.1 検索ノード設定
Firecrawlノードで 「Search and optionally scrape search results」 を選択。
ここでLimit = 5に設定すると、上位5件のURLを取得します。テスト時はLimit = 1に設定しておくとコストを抑えられます。

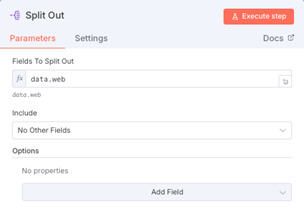
4.2 結果の分割
「Split out」ノードを追加し、
data.webを指定することで、Firecrawlが取得した結果を1件ずつ分割します。スプレッドシートの行のように、URLごとのループ処理が可能になります。
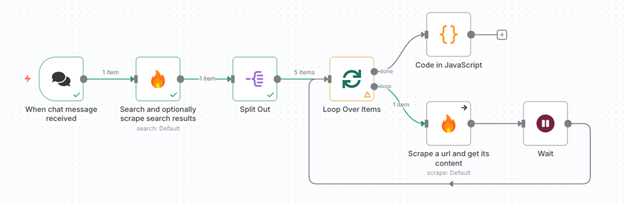
5. スクレイピング設定
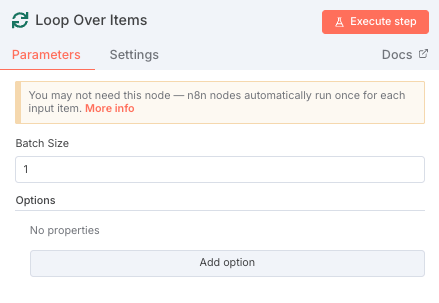
「Loop Over Items」ノードを追加し、Batch Size = 1に設定。
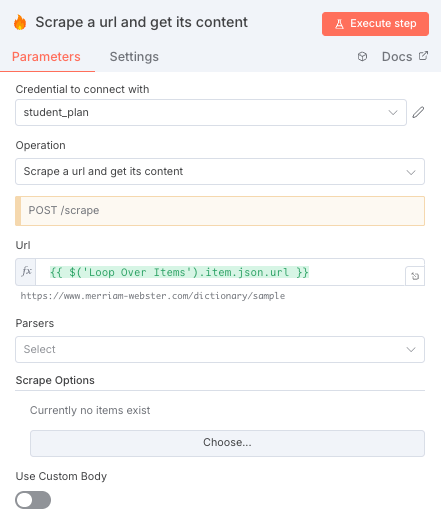
Firecrawlで 「Scrape a URL and get its content」 を選び、各URLの本文を自動的に取得します。
- On Error → Continue に変更:
スクレイピングに失敗したURLがあってもワークフローが停止しないようにします。 - Waitノード(5秒)を追加:
短時間に連続リクエストを送るとエラーが起きやすいため、明示的に待機を入れます。(Firecrawl利用時のマナーとしても有効)

6. スクレイピング結果の整理
複数ページから取得したテキストを1つにまとめるため、以下のようなコードブロックを追加します。
return {
output: $input.all()
.map(e => e.json.data?.markdown)
.filter(markdown => markdown !== undefined)
.join(',');
};
// 基礎:
// $input.all()という前の処理から流れてきた全てのデータを受け取って
// その中にある$input.all()/data/markdownというコンテンツを読み取り
// 取得できた全てのmarkdownを対象にして、
// ','、つまりカンマで区切って結合していく
// 応用:
// e.json?.markdownで、markdownが存在せずともundefinedという値を返す
// これによりスクレイピングでエラーが起きてデータがなくても
// エラーにならない。
// その後にあるfilter(markdown => markdown !== undefined)
// ⇒ markdownがundefinedじゃないもの(否定)のみ抽出
このスクリプトにより、全てのスクレイピング結果を
カンマ区切りで1つのテキストデータにまとめ、OpenAIに渡せる形式に整形します。
7. OpenAIノードによる企業レポート生成
次にOpenAIノードを追加します。
以下のようにプロンプトを構成することで、製薬・バイオ・医療機器企業に最適化した分析レポートを生成します。
🔧 プロンプト概要
▼ プロンプトの詳細(今日の日付 と スクレイピング結果 を変数として利用)
#syste_role
あなたは優秀な企業アナリストであり、特にライフサイエンス、製薬、バイオテクノロジー業界の企業分析を専門としています。
#instruction
• ユーザーから提供された企業名(検索対象企業)について、Web検索を行い、最新かつ正確な情報に基づいて詳細な企業分析レポートを作成してください。
• レポートは、以下の #output_format で指定されたセクションからなる構造で記述してください。アウトプットはMarkdown形式で出力してください。
• 情報が見つからないセクションについては、「情報が見つかりませんでした」と明記してください。ハルシネーションを避けるためにも、存在しない情報から文章を生成しないでください。
• 特に「AI, DXに関する取り組み」と「想定される経営課題・事業課題」は、ライフサイエンス・製薬業界の文脈を踏まえて深く分析してください。
• 分析は #input_data に与えられた事実のみをもとに行ってください。
#output_format
• 会社名(検索対象企業の正式名称を記述)
• 事業概要
主要な事業領域、ターゲット疾患、研究開発パイプラインのフェーズ
(例:臨床開発後期が多い、基礎研究中心など)、主要なビジネスモデル
(例:自社開発・販売、導出中心など)を具体的に記述。
• 売上・営業利益
直近の会計年度、または公表されている最新の財務実績(売上高、営業利益、前年比成長率など)を記載。
可能であれば、セグメント別の売上構成にも言及。
• 事業規模・組織体制
従業員数、拠点(国内・海外)、主要な研究開発(R&D)体制の特徴
(例:オープンイノベーションへの積極性、特定技術への集中投資など)を記述。
• 主力製品や新製品について
現在の収益の柱となっている製品名、適応症、および開発中のフェーズの進行している新薬候補(パイプライン)を具体的に記述。
• 想定される経営課題・事業課題
製薬・ライフサイエンス業界特有の課題(例:パテントクリフ、開発費高騰、規制当局の承認時期、グローバル競争下での技術的遅れなど)を記載。
企業が直面していると想定される具体的課題を深く分析して記述。
• AI, DXに関する取り組み
AIを活用した新薬探索(ドラッグ・ディスカバリー)、臨床開発の効率化、営業・マーケティング領域でのDX(例:リモートMR、デジタルチャネル活用)、RPA導入などの具体的事例を記述。
• リサーチに関するアイデア
上記分析を踏まえ、この企業や業界動向についてさらに深掘りして調査すべきリサーチテーマや次のアクションを記述。
(例:競合他社のAI投資状況比較、特定製品の地域別市場シェア調査などを 3〜5点程度)
#input_data
{{ $json["Join markdown text into a string"].item.json.output }}
#current_date
{{ $now.format('yyyy-MM-dd') }}
8. 出力例
@企業情報検索ボット 対象企業:武田薬品工業株式会社(Takeda Pharmaceutical Company Limited) 業種:医薬品 事業概要 武田薬品工業株式会社は、日本を代表する国際製薬企業であり、消化器系疾患、希少疾患、血液系腫瘍、オンコロジー(がん)、ニューロサイエンス(神経精神疾患)、ワクチン領域に焦点を置いた研究開発・販売を行っています。 研究開発は特にがん、希少疾患、免疫、神経、消化器、ワクチンの5領域に集中しており、特にオンコロジーや希少疾患、希少免疫領域では臨床開発の後期段階の製品も有しています。 ビジネスモデルとしては、自社開発製品の販売に加え、買収によるパイプライン強化や、他社製品の導入・提携も積極的に行っています。 かつては一般医薬品部門も保有していましたが、現在は処方薬中心のポートフォリオ構成を保持しています。 売上・業績情報 • 2023年3月期の売上高は約4兆274億円 • 営業利益は約9,059億円 • 直近5年では、持続バランスの取れた事業成長と安定的な収益体質を維持している • 海外売上比率は約79.9%(2024年上半期データ)でグローバル展開が主体 • セグメント別では消化器疾患、がん、希少疾患医薬品が売上の大部分を占める 事業規模・組織体制 • 連結従業員数は47,455名(2025年3月31日時点) • 本社は大阪市中央区および東京都中央区にあり、主要R&D拠点を国内外に配置 • 研究開発拠点として米国ボストン、スイス・チューリッヒ、シンガポール等に展開し、オープンイノベーションを重視 • グローバル経営体制のもと、多様な人材構成を特徴とするダイバーシティ経営を実践 主力製品・新製品について 主な販売中の製品: • エンティビオ(消化管用抗炎症薬) • ニンラーロ(多発性骨髄腫治療薬) • アディシブ(高血圧治療薬) • アルンブリグ(非小細胞肺がん治療薬) • テイクカブリ(HIV治療薬) 開発中の注目パイプライン: • シャイアー買収により希少疾患・オンコロジー領域で先進的なパイプラインを多数保有 • Innovent社との共同開発プロジェクトが進行中(2025年10月時点の最新発表) • 神経疾患・ワクチン領域でも新規開発案件が拡大中 想定される経営課題・事業課題 • 特許切れ(パテントクリフ)への対応 • グローバル開発コスト・販売コストの上昇による収益性圧迫 • 開発プロセスの長期化およびFDA等の承認遅延リスク • 欧米市場における価格規制・薬価引き下げリスク • プロジェクトマネジメントとコンプライアンスの両立課題 • AI創薬領域への投資増大に伴うROI不確実性 AI・DXに関する取り組み • 創薬工程にAIを活用したドラッグ・ディスカバリー技術の導入を推進 • 外部ベンチャーとの協働を通じた創薬AI基盤の構築 • 営業部門ではリモートMRおよびCRMデータ統合による営業効率化を実施 • ロボティック・プロセス・オートメーション(RPA)導入で業務標準化を推進 • グローバル本社直轄でAI活用推進部門を新設し、各国子会社間で技術連携を展開 リサーチに関する提案・次のアクション 1. AI創薬分野の国内外パートナー動向の比較分析 2. 製薬大手におけるパテントクリフ対応策の定量比較 3. Takedaの主要新薬の地域別収益構造(アジア・北米・欧州)分析 4. リモートMR導入後の営業効率化とROI検証 5. オンコロジー領域におけるAI創薬ベンチャーとの共同研究数・投資比率の可視化 備考 本レポートは2025年10月末時点の公情報(プレスリリース・IR資料等)を基に作成されています。
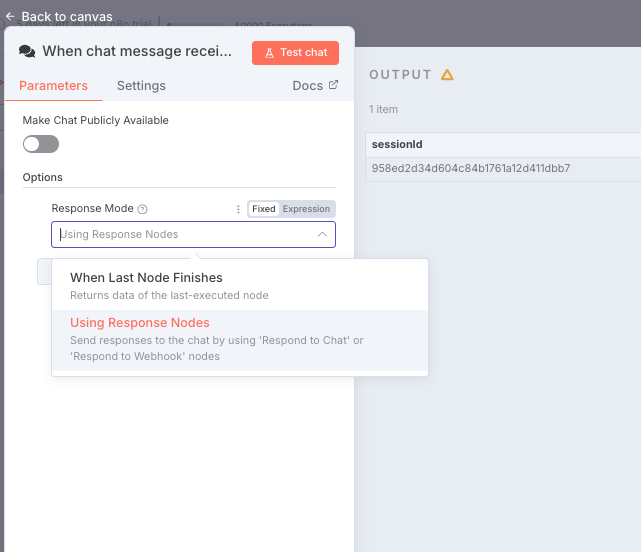
9. 最後の出力設定
最後に「Respond to Chat」ノードを配置します。
「When Chat Message Received」ノードの設定において、Response Mode → Using Response Nodes を選択しておくことで、n8nのチャット画面上に直接レポートが出力されます。
10. まとめ
本記事で紹介した「企業検索ボット(STEP0)」は、
ライフサイエンス業界のリサーチを圧倒的に効率化できる仕組みです。
- コード不要で構築可能
- Firecrawl+OpenAIで自動分析
- R&D・DX・アライアンス領域に特化した企業分析にも対応
今後は、Slack連携やスレッド単位のQ&A、RAGデータベース化へと拡張し、「会話で企業を理解するボット」として進化させていきます。
11. 詳細ステップ
STEP0. 企業検索ボット簡易ワークフロー
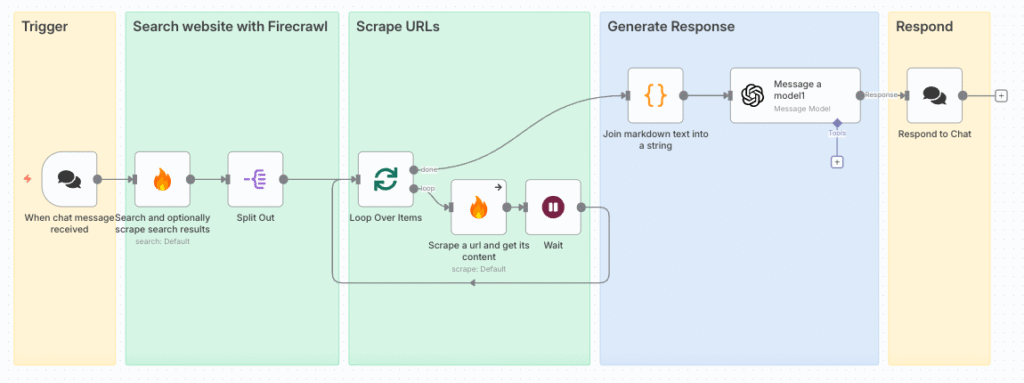
一連の流れ
- メッセージを受信することでワークフローを起動
- Firecrawlを用いてWeb検索を実施し、複数のURLを取得(Firecrawl / Split out)
- URL群に対してスクレイピングを実施(Loop Over Items / Firecrawl)
- 結果をまとめて企業情報に関するレポートを生成(OpenAI)
- 結果を返却
1. メッセージを受信することでワークフローを起動
- When Chat message recievedを最初のノードに設定
- 次にFirecrawlと検索、その中の「Search and optionally scrape search results」を選択
- ノードの設定は以下。
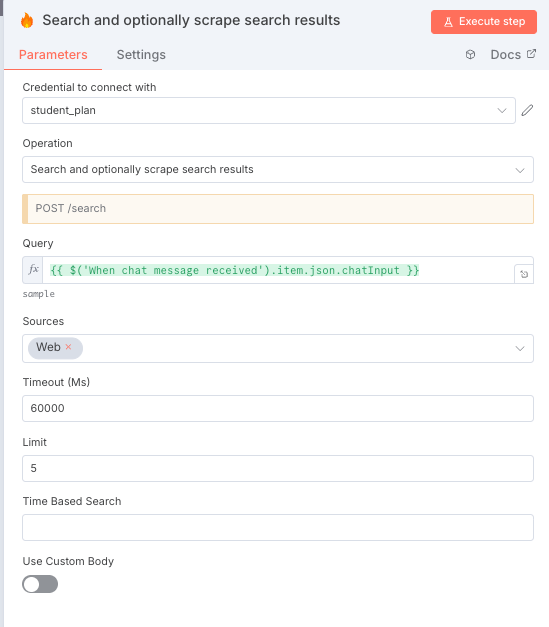
Limit = 5となっている部分は検索結果として取得するURLの数を示している。
Limitの数を多くすれば、その分大量のURLを取得することができるが、LLM APIのコストもFirecrawlのコストも嵩む。テストを行う時にはLimit = 1に設定して、1件のみ取得するなど注意が必要である。
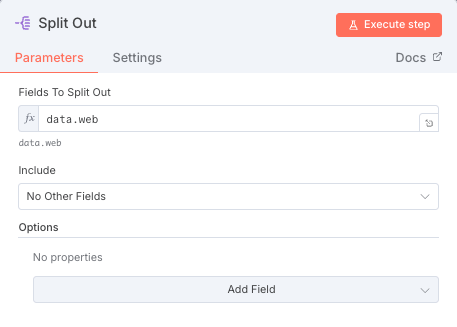
- 次に「Split out」ノードを追加する。このノードはFirecrawlが取得したデータを分して、ループ処理できるように変換する役割を持つ。以下のように、data.webと記載するとFirecrawlが取得したデータを分割して、Spreadsheetで言う一行ずつに整形してくれる。
- Loop Over Items を追加。
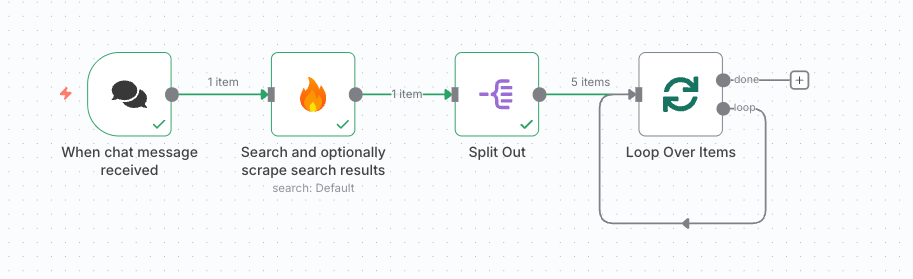
- 設定のBatch Sizeは1に設定しておく
- 次にもう一度Firecrawlノードを追加するが、今回は「Scrape a url and get its content 」を選択。
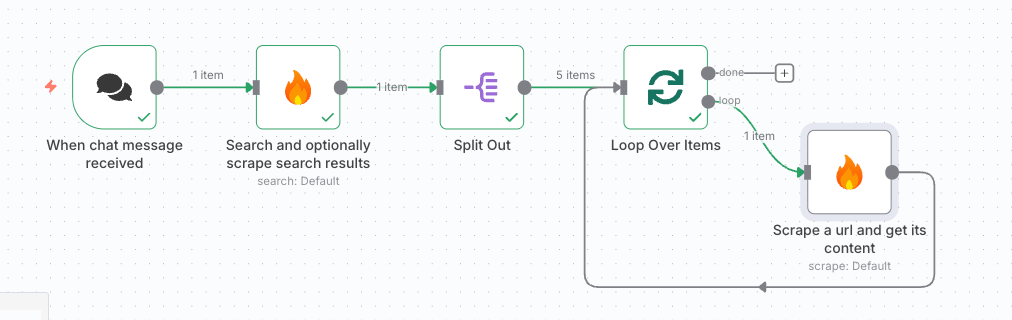
- 内部の設定は以下。Urlフィールドに、一つ目のFirecrawlノードで取得したURLを1つずつ入れていく。これにより、10個のURLがあっても1つずつ検索していくことができる
- 追加の設定で「Settings」タブを選択して、On ErrorをデフォルトのStop WorkflowからContinueに変更する。これがないと、スクレイピングできないサイトに遭遇した際に毎回ワークフローが止まってしまい、回答が返ってこない。
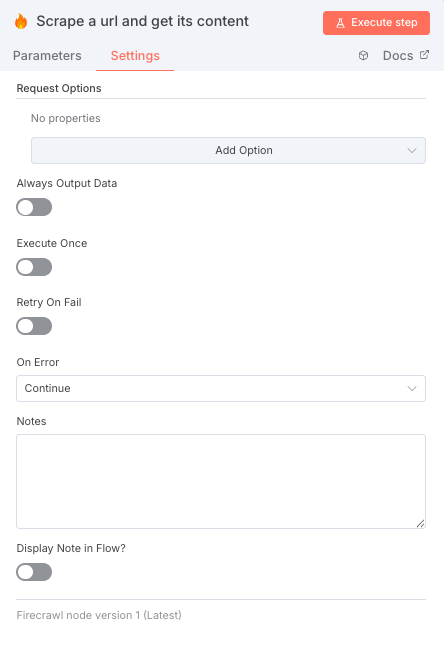
- Waitノードを各スクレイピングの後に追加する。Firecrawlは同時に複数回のリクエストを送信するとエラーになってしまうことがある。なので明示的に5秒くらい待機させてエラーを回避する必要がある。また、スクレイピングのマナーとしても最低1秒は待機させることが好ましい。
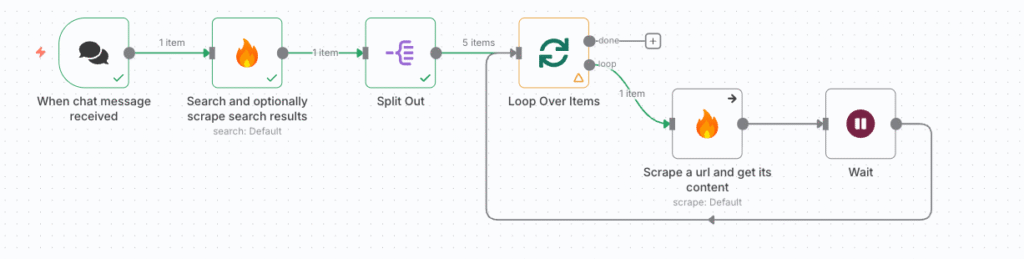
- 今回は明示的に5秒待機。
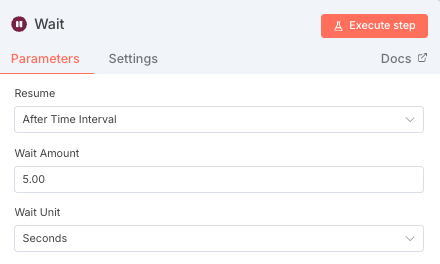
- Loopしたスクレイピング結果をまとめてLLMに投げるデータとして準備する必要があるため、コードブロックをセット
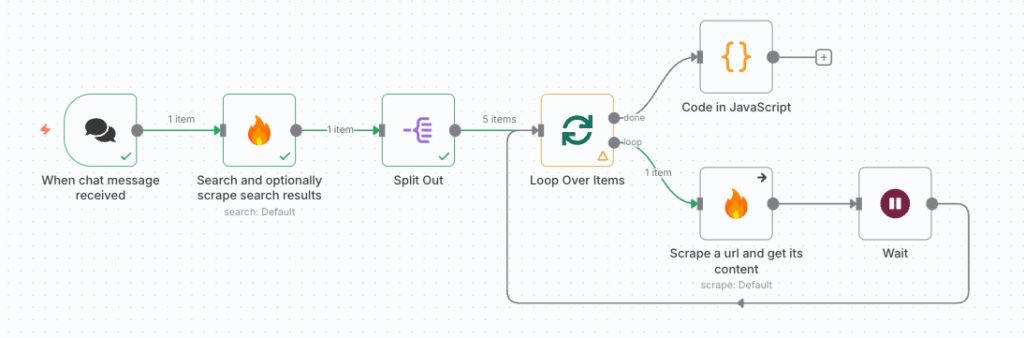
- コードブロックでは以下のようなコードを記述
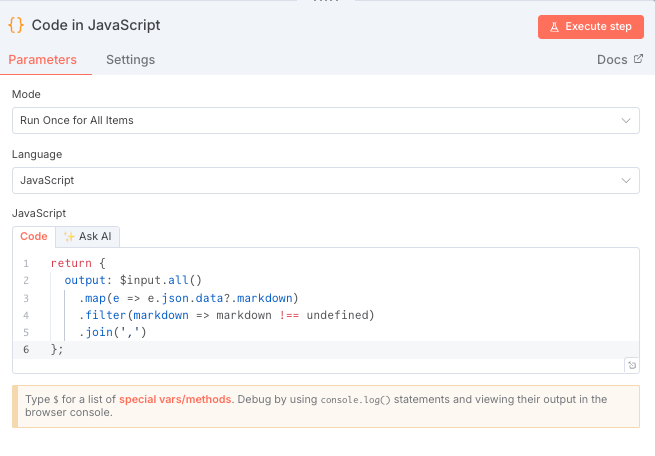
return{
output:$input.all()
.map(e=>e.json.data?.markdown)
.filter(markdown=>markdown!==undefined)
.join(',')
};
// 基礎:
// $input.all()という前の処理から流れてきた全てのデータを受け取って
// その中にある$input.all()/data/markdownというコンテンツを読み取り
// 取得できた全てのmarkdownを対象にして、
// ','、つまりカンマで区切って結合していく
// 応用:
// e.json?.markdownで、markdownが存在せずともundefinedという値を返す
// これによりスクレイピングでエラーが起きてデータがなくても
// エラーにならない・
// その後にあるfilter(markdown => markdown !== undefined)
// でmarkdownがundefinedじゃないもの(否定)のみ抽出
- LLMノードを追加(今回はOpenAIを使用)
▼プロンプトの詳細は以下(今日の日付とスクレイピング結果を変数として利用)
#syste_role
あなたは優秀な企業アナリストであり、特にライフサイエンス、製薬、バイオテクノロジー業界の企業分析を専門としています。
#instruction
-
ユーザーから提供された企業名(検索対象企業)について、Web検索を行い、最新かつ正確な情報に基づいて詳細な企業分析レポートを作成してください。
-レポートは、以下の#output_formatで指定されたセクションからなる構造で記述してください。アウトプットの生成はMarkdown形式で出力してください。
-情報が見つからないセクションについては、「情報が見つかりませんでした」と明記してください。ハルシネーションを避けるためにも存在しない情報からの文章生成を絶対に行わないでください。
-特に「AI,DXに関する取り組み」と「想定される経営課題・事業課題」は、ライフサイエンス・製薬業界の文脈を踏まえて深く分析してください。分析は#input_dataにて与えられた事実のみをもとに行なってください。
#output_format
*会社名*(検索対象企業の正式名称を記述)
*事業概要*(主要な事業領域、ターゲット疾患、研究開発パイプラインのフェーズ(例:臨床開発後期が多い、基礎研究が中心など)、主要なビジネスモデル(例:自社開発・販売、導出中心など)を具体的に記述)
*売上・営業利益*(直近の会計年度、または公表されている最新の財務実績(売上高、営業利益、前年比成長率など)を記述。単位(例:億円)を明記。可能であれば、セグメント別の売上構成にも言及)
*事業規模・組織体制*(従業員数、拠点(国内・海外)、主要な研究開発(R&D)体制の特徴(例:オープンイノベーションへの積極性、特定技術への集中投資など)を記述)
*主力製品や新製品について*(現在の収益の柱となっている製品名、適応症、および開発中のフェーズの進んでいる新薬候補(パイプライン)について具体的に記述)
*想定される経営課題・事業課題*(製薬・ライフサイエンス業界特有の課題(例:**特許の崖(パテントクリフ)**への対応、開発費高騰、規制当局の承認動向、グローバル競争における特定の技術的遅れなど)を念頭に、この企業が直面していると想定される具体的な課題を深く分析して記述)
*AI,DXに関する取り組み*(AIを活用した新薬探索(ドラッグ・ディスカバリー)、____________臨床開発の効率化、営業・マーケティングにおけるDX(例:リモートMR、デジタルチャネルの活用)、RPA導入など、具体的な取り組み事例を記述)
*リサーチに関するアイデア*(上記分析を踏まえ、この企業や業界動向についてさらに深掘りして調査すべき具体的なリサーチテーマや次のアクション(例:競合他社の同様のAI投資状況の比較、特定の主力製品の地域別市場シェア調査など)を3~5点提案)
#input_data
{{$('Join markdown text into a string').item.json.output}}
# current_date
{{$now.format('yyyy-MM-dd')}}
- 最後にRespond to chatノードを追加
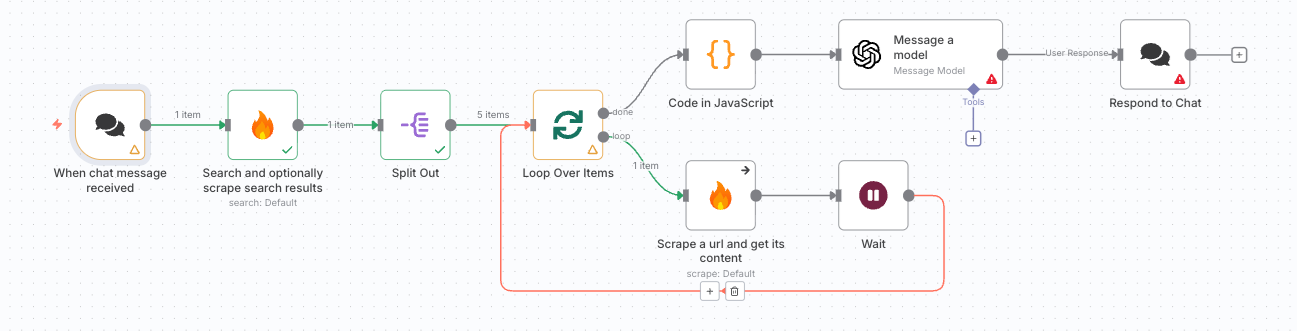
- このままだとエラーになるので一番最初のWhen chat message recievedノードの設定を少し変更する。Add OptionsからResponse Modeを選択し、Using Response Nodesにする。これでn8n内のチャット画面からワークフローを起動して、最終的な結果をチャットに返すことができる

ヘルツレーベンでは、ライフサイエンス業界に特化したDX・自動化支援を提供しています。
PubMedや学術情報の自動収集をはじめ、Slack・Gmailなどを活用したナレッジ共有の仕組みまで、実務に直結するワークフローを設計・導入いたします。
提供サービスの例
- 製薬・医療機器業界での提案活動や調査業務の自動化支援
- アカデミアや研究者向けの文献レビュー・情報共有フローの最適化
- 医療従事者のキャリア開発を支援するリスキリングプログラム
👉 ご興味をお持ちの方はぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら

")
